《架构思维》专题
-
sp_help-表被“空字符串”架构绑定视图引用
我正在尝试系统地确定本地数据库和由其他人管理的远程数据库之间的模式差异。我让远程管理员运行了一个脚本,该脚本sp_help并在各种对象上sp_helptext。 有一个区别我不知道如何解释。在我的本地系统上,sp_help一个表上生成一行消息输出 没有具有架构绑定引用表“dbo.tbl”的视图。 在远程系统上,输出是“表被视图引用”,后跟一个空行。该查询是以文本形式输出的,因此这表明在远程机器上产
-
如何设置Azure移动应用程序表的架构?
目前,表是在“dbo”架构中创建的,但我想将其设置为其他内容。这可能吗?
-
Kafka架构注册表在同一主题中不兼容
我很困惑,如果模式注册中心不能演化模式升级/更改,那么我为什么要使用模式注册中心,或者说我为什么要使用AVRO?
-
KTable外键联接与avro架构注册表不兼容
使用汇流5.4.1 在将连接的流从连接的KTable转发到另一个主题时,我们碰巧在新的KTable外键连接中遇到了一个问题。 将错误中提到的模式与在模式注册表上注册的模式进行比较,结果完全相同…似乎Kafka 2.4.0中已经出现了类似的问题:https://issues.apache.org/jira/browse/Kafka-9390并且该问题在转发到另一个主题时仍然存在
-
查询MediaStore。音频使用Android架构组件的媒体?
我一直在关注Android架构组件LiveData、Room和ViewModel(MVVM)。它为我们节省了使用加载程序和在数据库表上监视数据的麻烦。但我想知道我们是否可以使用LiveData和这种架构来查询Medistore。音频媒体和其他通过ContentProviders提供的Uri。
-
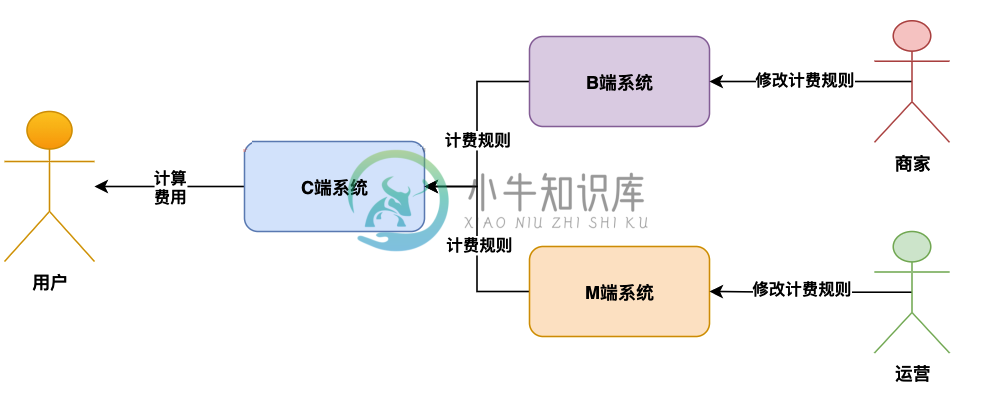 高可用高并发架构系统该如何设计?
高可用高并发架构系统该如何设计?主要内容:背景,计费业务系统架构设计,计费业务数据补偿系统设计,总结背景 今天给大家分享一个话题,就是对于线上跟钱有关的计费类的系统,在线上可能出现的一些把钱算错的问题,以及我们如何来设计架构解决这些问题。 但凡是跟算钱相关的系统,都是每个公司的重中之重,比如说价格系统、运费系统、计费系统、支付系统、基金系统、财务系统、结算系统等等,因为这些系统运行过程中,随时可能因为技术问题或者运营的人为误操作问题,把钱给算错了。 所以今天来给大家讲讲这一类跟算钱有关的系统,我
-
架构原理 - segment、buffer和translog对实时性的影响
既然介绍数据流向,首先第一步就是:写入的数据是如何变成 Elasticsearch 里可以被检索和聚合的索引内容的? 以单文件的静态层面看,每个全文索引都是一个词元的倒排索引,具体涉及到全文索引的通用知识,这里不单独介绍,有兴趣的读者可以阅读《Lucene in Action》等书籍详细了解。 动态更新的 Lucene 索引 以在线动态服务的层面看,要做到实时更新条件下数据的可用和可靠,就需要在倒
-
第六章 Hive - 5 Hive的存储架构与HQL语法
一 概述 当然,Hive和传统的关系型数据库有很大的区别,Hive将外部的任务解析成一个MapReduce可执行计划,而启动MapReduce是一个高延迟的一件事,每次提交任务和执行任务都需要消耗很多时间,这也就决定Hive只能处理一些高延迟的应用(如果你想处理低延迟的应用,你可以去考虑一下Hbase)。 同时,由于设计的目标不一样,Hive目前还不支持事务;不能对表数据进行修改(不能更新、删除、
-
一文读懂 hadoop、hbase、hive、spark 分布式系统架构
本文结构 首先,我们来分别部署一套hadoop、hbase、hive、spark,在讲解部署方法过程中会特殊说明一些重要配置,以及一些架构图以帮我们理解,目的是为后面讲解系统架构和关系打基础。 之后,我们会通过运行一些程序来分析一下这些系统的功能 最后,我们会总结这些系统之间的关系 分布式hadoop部署 首先,在http://hadoop.apache.org/releases.html找到最新
-
 小红书:iOS开发—效率与架构,一面面经
小红书:iOS开发—效率与架构,一面面经整体问的不是很难,没有问iOS基础,主要是八股问答,一面完了1分钟后立马发邮件通知通过~等待二面中... 时长:1小时6分钟 1. 自我介绍:5分钟 2. 计算机网络 2.1 讲一下HTTPS的加密过程。 答:TLS四次握手,client hello, server hello,pre-master key,CA证书哈希验证 2.2 HTTP有哪些常见的状态码? 答:2、3、4、5开头的各举几个例
-
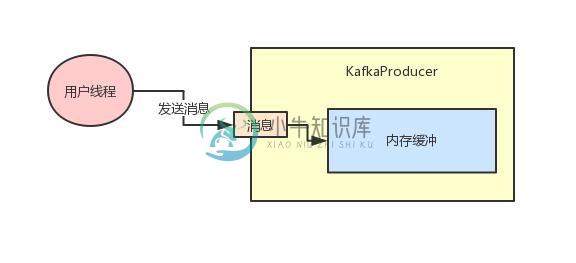 架构师必须知道的关于Kafka参数调优
架构师必须知道的关于Kafka参数调优主要内容:1、背景引入:很多同学看不懂kafka参数,2、一段Kafka生产端的示例代码,3、内存缓冲的大小,4、多少数据打包为一个Batch合适?,5、要是一个Batch迟迟无法凑满怎么办?,6、最大请求大小,7、重试机制,8、持久化机制1、背景引入:很多同学看不懂kafka参数 今天给大家聊一个很有意思的话题,大家知道很多公司都会基于Kafka作为MQ来开发一些复杂的大型系统。 而在使用Kafka的客户端编写代码与服务器交互的时候,是需要对客户端设置很多的参数的。 所以我就见过很多年轻的同学
-
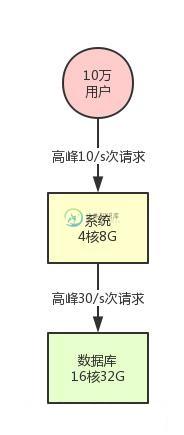 天猫双11高并发架构是怎么设计的?
天猫双11高并发架构是怎么设计的?主要内容:一、背景引入,二、先考虑一个最简单的系统架构,三、系统集群化部署,四、数据库分库分表 + 读写分离,五、缓存集群引入,六、引入消息中间件集群,七、现在能hold住高并发面试题了吗?,八、本文能带给你什么启发?一、背景引入 这篇文章,我们聊聊大量同学问我的一个问题,面试的时候被问到一个让人特别手足无措的问题:你的系统如何支撑高并发? 大多数同学被问到这个问题压根儿没什么思路去回答,不知道从什么地方说起,其实本质就是没经历过一些真正有高并发系统的锤炼罢了。 因为没有过相关的项目经历,所以就
-
 大数据分析师应该具备的知识架构
大数据分析师应该具备的知识架构算法选取在算法选取方面,个人感觉也是要结合业务来实施。首先,要弄清楚业务那边主要关注的是什么指标。而与这一个指标相关的参数有那些,这些参数都是如何来影响这些指标的。至于算法的准确度,这一点,可以通过对数据颗粒度的细化来不断提高。不同的代码对系统的资源调度是不同的,而若你对算法的了解程度最大限度决定了你最终产品的反应快慢! 但据《财经》记者调查,这些有政府和国资背景的大数据交易所大部分生意寥寥,纯市
-
 阶跃星辰大数据基础架构研发一面
阶跃星辰大数据基础架构研发一面系统组 1.自我介绍 2.实习拷打 3.项目拷打 4.spark任务提交过程 5.sparkrdd运行过程shuffle阶段拆分 6.hdfs上文件存储方式 7.hdfs写数据流程 8.算法:判断链表是否有环 9.反问 23大概40min 4567 10min 8 5min
-
 北京百度 基础架构 大前端 一面 面经
北京百度 基础架构 大前端 一面 面经时长45mins 自我介绍 你的开源项目有没有其他人的使用反馈或 issue? 你有什么优势? 说说你最近在学习的技术? Vite 为什么这么快? 在开发环境和生产环境有什么优化? 开发环境esbuild 生产环境不太清楚 H5项目的响应式,移动端适配是怎么做的?有没有做PC端适配? postcss 对响应式布局的理解? rem flex vh/vw 如何做同一个列表在不同端有不同行的展示? 说了