《同花顺2024春招交流讨论》专题
-
 游戏交互校招上岸,前来还愿
游戏交互校招上岸,前来还愿1.简历筛选:由于之前就在网易游戏实习,所以找了同事前辈帮忙内推跳过了简历筛选,但是还是认认真真的做了作品集。(本人学校比较差,要是没实习没内推可能第一关就挂了,发自内心真的非常感谢给我的导师和前辈!) 2.笔试:我的游戏交互的笔试题是以“大闹天宫”为背景的动作手游交互操作设计,给了五天时间设计(实际差不多四天)据说难度比较难,满打满算做了四天,还通宵了一晚,直到截止前半个小时我才提交了笔试。
-
 23届秋招|美团|交互设计一面
23届秋招|美团|交互设计一面1. 自我介绍 2. 没有选择本专业作为职业的原因 3. 针对作品集提问,如设计亮点、如何确定优化点、有没有什么上线后跟预期不一样的点、有没有遇到什么困难 4. 我在项目中的职责 以上大概只进行了二十多分钟,剩下都是闲聊,包括Base地倾向,平时有什么爱好,针对部门业务和设计流程进行讨论。 复盘:整个过程较轻松,面试官会在自己讲述的时候有反馈,每个问题也点到为止没有深挖,但面试过程有点短,提问也不
-
 交通银行社招笔试经验分享
交通银行社招笔试经验分享大家好,我叫炎炽枫,工作五年。一看标题有些同行可能就想问,怎么拿到面试机会的,毕竟这么多外包。 答案是官网申请,百度输入交通银行招聘官网。一开始我也搜一些面试经验,结果都是校招的,社招的经验几乎没有,本以为会考一些综合知识,结果不是。 我面试的是前端岗 题型分单选20题40,多选15题30分,简答题3题6分论述题一题12分 选择题(css clientwidth, js,promise,this,
-
Mysql:交换不同行的数据
问题内容: 假设一个表看起来像这样: 如何将一行的值与另一行 交换 ,而使ID号保持不变? 例子: 结果: 请注意,除了id之外,所有值都是完整的。我需要使用非常大的值列表来执行此操作,因此我需要一个单行代码,或者最多不需要一个临时表的创建之类的东西。 注意:id是唯一的 谢谢 问题答案: 您可以使用联接不等式来排列要交换的行: http://sqlfiddle.com/#!18/27318a/5
-
按不同顺序添加相同的双精度时的不同结果
为什么在添加相同的数字时输出不同? 输出为: 如果我交换值 我得到的输出为:<代码>15.7000000000001 如何获得相同的输出?
-
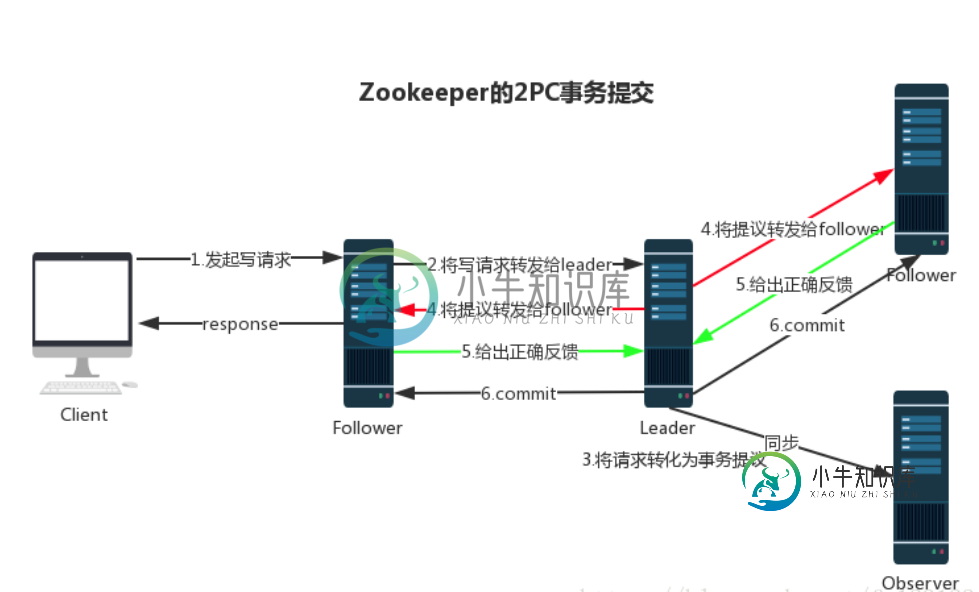 12.0 Zookeeper 数据同步流程
12.0 Zookeeper 数据同步流程在 Zookeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性。 ZAB 协议分为两部分: 消息广播 崩溃恢复 消息广播 Zookeeper 使用单一的主进程 Leader 来接收和处理客户端所有事务请求,并采用 ZAB 协议的原子广播协议,将事务请求以 Proposal 提议广播到所有 Follower 节点,当集群中有过半的Follower 服务器进行正确的 ACK 反馈,那么Lea
-
 科大讯飞2024届秋招研发类笔试试卷(六)前端-编程
科大讯飞2024届秋招研发类笔试试卷(六)前端-编程1模拟即可 #include <bits/stdc++.h> using namespace std; int main() { int n; cin >> n; vector<int> arr(n); for (int i = 0; i < n; i++) cin >> arr[i]; int res = 0; for (aut
-
在两个片段之间进行交流
我的应用程序中有三个片段,其中需要传递和接收数据。我应该如何进行他们之间的沟通。我试图参考许多网站,但没有解决方案。 请给我推荐一些好的链接。 提前感谢。
-
如何交错(合并)两个Java 8流?
问题内容: 对于下面的输出,我需要做什么? 我调查了一下,但是正如javadoc所解释的,它只是一个接一个地追加,它不会交错/散布。 创建一个延迟串联的流,其元素是第一个流的所有元素,后跟第二个流的所有元素。 错误地给 如果我收集它们并进行迭代,但是希望获得更多Java8-y,Streamy :-),可以这样做 注意 我不想压缩流 “ zip”操作将从每个集合中获取一个元素并将其组合。 压缩操作的
-
如何交织(合并)两个Java 8流?
我需要做什么才能使输出如下所示? 我查看了concat,但正如javadoc所解释的,它只是一个接一个地附加,而不是交错/穿插。 创建一个延迟连接的流,其元素是第一个流的所有元素,然后是第二个流的所有元素。 错误地给予 如果我收集它们并迭代,可以做到这一点,但希望有更多的Java8-y,Streamy:-) 笔记 我不想让溪流断流 “zip”操作将从每个集合中获取一个元素并将其组合。 zip操作的
-
嵌入式Kafka与真实课堂交流
我有一个Spring Boot应用程序,可以使用和。我有一位制片人。 我想写JUnit上面没有任何嘲弄类。我尝试了,但我不确定如何将其连接到我的应用程序定义的kafka代理,所以当我发送主题消息时,消费者(其中存在)应该选择消息并处理它。 有了我也得到了下面的错误。 有人能告诉我如何在不模仿任何类的情况下为我的Kafka制作人编写Junit,它应该用真实的类进行测试。
-
提交云数据流作业时出错
-
 百度测开暑期0410笔试交流
百度测开暑期0410笔试交流百度用的赛码网考,需要开摄像头,笔试包括30道选择题60分,两道编程题40分 题目一:优惠券这道题笔试时a了27%,笔试后发牛客上有佬给做了指正,我觉得应该是可以的了 题目描述:在L-R闭区间内,取一个整数x,优惠计算方式=x *(x的各位数字之和),问最大的优惠是多少? 例:[3,6],取3时,优惠为3*3=9,取4时,优惠为4*4=16,...因此最大优惠为6*6=36 再比如[28,31],
-
Kafka分区是如何在火花流与Kafka共享的?
我想知道Kafka分区是如何在从executor进程内部运行的SimpleConsumer之间共享的。我知道高水平的Kafka消费者是如何在消费者群体中的不同消费者之间分享利益的。但是,当Spark使用简单消费者时,这是如何发生的呢?跨计算机的流作业将有多个执行程序。
-
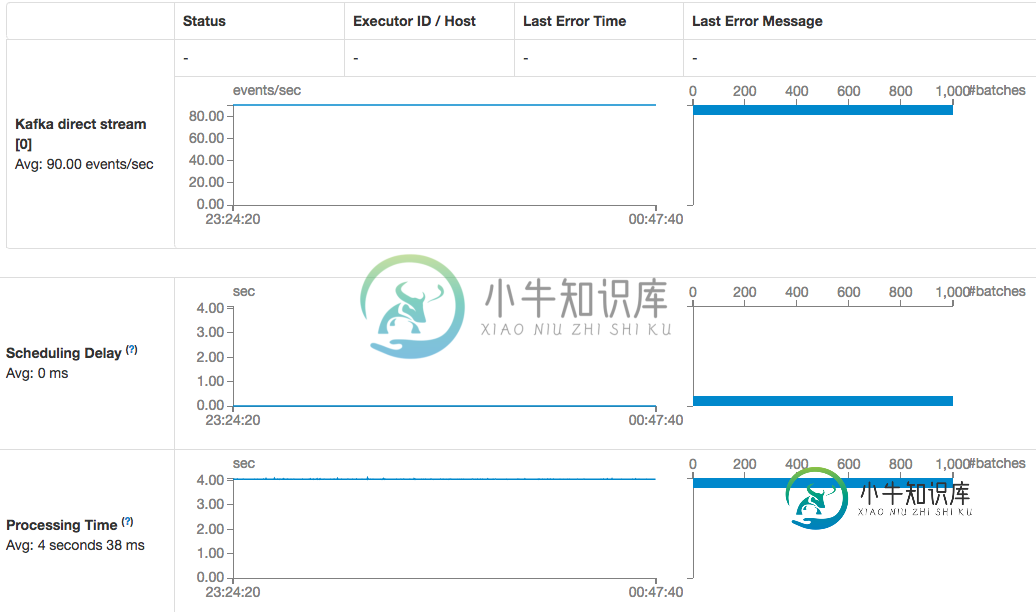 火花流Kafka直接消费者消费速度下降
火花流Kafka直接消费者消费速度下降我使用的是运行在AWS中的spark独立集群(spark and spark-streaming-kafka version 1.6.1),并对检查点目录使用S3桶,每个工作节点上没有调度延迟和足够的磁盘空间。 没有更改任何Kafka客户端初始化参数,非常肯定Kafka的结构没有更改: 也不明白为什么当直接使用者描述说时,我仍然需要在创建流上下文时使用检查点目录?