《同花顺2024春招交流讨论》专题
-
集团财产不工作在春流云?
我使用Spring Stream云来消费Kafka上的消息。当Kafka上的信息产生时,所有的消费者都受到了冲击。 但Kafka的文献表明,通过使用群体,只有一个消费者消费信息。 这是我的消费代码。 这是我的配置,但我的两个方法都调用了:(
-
火花纱模式如何从火花提交中获得应用程序
当我使用spark-submit with master yarn和deploy-mode cluster提交spark作业时,它不会打印/返回任何applicationId,一旦作业完成,我必须手动检查MapReduce jobHistory或spark HistoryServer来获取作业细节。 我的集群被许多用户使用,在jobHistory/HistoryServer中找到我的作业需要很多时
-
 深信服2024秋招,测试开发工程师面经
深信服2024秋招,测试开发工程师面经深信服在成都的线下面试主要集中在9月22日——24日,我是23日上午 面试问题: 1、个人介绍 2、项目经历 3、团队项目中负责的模块,队友都负责哪些工作? 4、栈、队列的实际应用? 5、SQLite的特点 6、数据库的底层数据结构? 7、手撕编程题:求一个数组中出现次数最多的元素,和它的出现次数 8、考虑特殊情况,数组为空怎么办,有多个相同次数的元素怎么办? 9、python的迭代器和生成器都在
-
 2024秋招冰川网络数值策划面经(已挂
2024秋招冰川网络数值策划面经(已挂写个面经攒攒人品,祈愿意向,还挺喜欢这个公司的。 10.19下午一面业务面 自我介绍有点偏向官方了,面试官希望我有自己方面的介绍 自我介绍 阴阳师最好的玩法模式分析 分析阴阳师抽卡模式 对比阴阳师和原神的抽卡模式 自我性格,爱好介绍 反问 10.23上午二面hr面 自我介绍 校园项目是主要讲什么 最喜欢的游戏 介绍这款游戏 为什么要来做游戏 对自己的缺点认识 爱好,日常活动 期望薪资 hr人很好很
-
 2024秋招美团优选产品面试内容(已挂)
2024秋招美团优选产品面试内容(已挂)面试岗位:物流产品组/用户产品组 面试次数:物流2次+用户1次#面经# 面试内容: · 物流产品(一面)20min 整体印象:面试官非常友善,没有假大空的问题,专注简历内容,很顺利; 面试内容: · 简历挖掘,核心想问两件事情: 1. 你认为的项目难点+解决方法+怎样的核心能力得到锻炼; 2. 你的工作内容及职责,询问细节体现你在项目中的作用。 · 问题讨论:业务背景介绍+问题+你的解决方案 询问
-
 游卡2024校招游戏策划岗位面经(已oc)
游卡2024校招游戏策划岗位面经(已oc)因为offer了来还愿一下,写一个面经。 流程走了一个月,拥有了2023的最后的奇迹,非常开心。 bg双非建筑,有两端游戏策划岗位经历的实习,转行。 ———————————————— 12.12群面,14个人+一个面试官+一个hr 轮流自我介绍1min 轮流主题演讲1min 小组讨论30min+展示10min 面试官提问10min 小组重视“组”“整体”两个概念(个人认为);大家bg都很强,蛮多硕
-
 百度2024届秋招提前批后端一面面经
百度2024届秋招提前批后端一面面经1.自我介绍 2.场景题,如何解决菜品超卖问题? 3.Redis缓存穿透,击穿,雪崩分别是什么? 4.MySQL主从复制怎么做的? 5.算法:快速排序 6.算法:两数之和(力扣第一题原题) 7.反问: ①部门主要业务 ②工作氛围 ③对我的建议 建议过程中又提问了MySQL为什么使用B+树作为索引?为什么不是B树,红黑树? 全程项目中深挖八股,1h左右
-
 众安java 2024校招提前批一面+终面(已OC)
众安java 2024校招提前批一面+终面(已OC)技术面(2023年6月14日) 问题 Java内存模型(JVM内存模型) Collection接口中List、Set、Map的区别 设计模式熟悉吗,介绍几个 MySQL存储结构 索引失效 为什么使用函数MySQL索引就会失效 Spring 事务有哪两种? @Transactional原理 一个方法含有@Transactional注解,当他调用其他含有该注解的方法的时候是怎么把调用的方法合并成一个事
-
 22前端,去年11月底被裁,春招面经集合(社招)
22前端,去年11月底被裁,春招面经集合(社招)3.14更新,最后一家oc了,先去待着了,完结撒花 当前剩余面试个数:0 拼多多 自我介绍 react常用钩子 useEffect怎么模拟生命周期 vue3跟vue2有什么区别 proxy有什么polyfill可以兼容低版本浏览器吗 px,em,rem区别 不同设备怎么适配 flex实现左侧固定右侧自适应 flex三个属性分别是什么 写题,版本号比较 之前公司项目介绍一下 你觉得哪个比较难 vit
-
 顺丰前端秋招一二三面
顺丰前端秋招一二三面9.7一面 react和vue的区别 浏览器的渲染原理 proxy和object.definedproperty 5、flex布局,左右定宽中间自适应怎么实现 有序列表内容 异步编程的方法 有序列表内容 深浅拷贝 有序列表内容 V-for需要确定key,为什么 数组遍历方法 9.15 二面 实习项目相关 未来规划怎么样的 webgl详细讲解下 为什么不用echarts? ecgarts的Canva
-
过滤流不同
null 或用java
-
火花流未阅读所有Kafka记录
我们从kafka向SparkStreaming发送了15张唱片,但是spark只收到了11张唱片。我用的是spark 2.1.0和kafka_2.12-0.10.2.0。 密码 bin/Kafka-console-producer . sh-broker-list localhost:9092-topic input data topic # 1 2 3 4 5 6 7 8 9 10 11 12
-
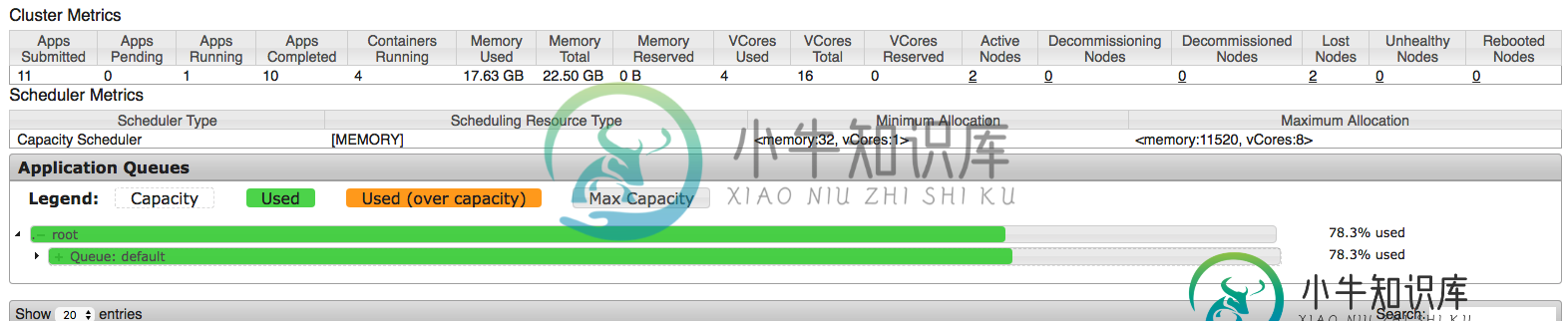 带纱线的火花流应用配置
带纱线的火花流应用配置在配置spark应用程序时,我试图从集群中挤出每一点,但似乎我并没有完全正确地理解每一件事。因此,我正在AWS EMR集群上运行该应用程序,该集群具有1个主节点和2个m3类型的核心节点。xlarge(每个节点15G ram和4个vCPU)。这意味着,默认情况下,每个节点上为纱线调度的应用程序保留11.25 GB。因此,主节点仅由资源管理器(纱线)使用,这意味着剩余的2个核心节点将用于调度应用程序(
-
批之间的流数据共享火花
Spark streaming以微批量处理数据。 使用RDD并行处理每个间隔数据,每个间隔之间没有任何数据共享。 但我的用例需要在间隔之间共享数据。 > 单词“hadoop”和“spark”与前一个间隔计数的相对计数 所有其他单词的正常字数。 注意:UpdateStateByKey执行有状态处理,但这将对每个记录而不是特定记录应用函数。 间隔-1 输入: 输出: 火花发生3次,但输出应为2(3-1
-
用于火花流的Kafka主题分区
我有一些关于Kafka主题分区->spark流媒体资源利用的用例,我想更清楚地说明这些用例。 我使用spark独立模式,所以我只有“执行者总数”和“执行者内存”的设置。据我所知并根据文档,将并行性引入Spark streaming的方法是使用分区的Kafka主题->RDD将具有与Kafka相同数量的分区,当我使用spark-kafka直接流集成时。 因此,如果我在主题中有一个分区和一个执行器核心,