《同花顺2024春招交流讨论》专题
-
 秋招面经-花旗金融-UX/UI设计师
秋招面经-花旗金融-UX/UI设计师# 设计人的面试经历记录##设计人的面试记录# 公司:花旗金融信息服务 岗位:UX/UI设计师 一面很简单,是同岗位的设计师面的。先用英文讲解以前的项目,考察设计能力和设计思维。讲解到一半说可以了,说一开始看我的作品就很喜欢(感恩!)然后跟我介绍了岗位大概的职责和工作内容,问我和职业发展相符吗,我说可以的,然后就说过了,可以准备二面了。 二面是部门经理面试的,是技术出身,同样让讲解以前的项目,并问
-
并行流要比java中的流花费更多的时间[duplicate]
我在学习java stream api时在代码中发现了这个问题。 这是我的代码 我在sts和inteliJ IDE上试用了这段代码,结果都是一样的。并行比顺序需要更长的时间。我的JDK有问题吗?请建议。
-
 23秋招-顺丰前端一面-面经
23秋招-顺丰前端一面-面经时间:9 月 6 日 时长:40 min 左右 体验:非常糟糕 项目相关 项目的后台有没有考虑服务的稳定性? 静态资源有没有考虑拆分?(图片是放到了阿里云的 OSS 存储上) Vue Vue2 和 Vue3 的区别? 说一下对 diff 算法的理解 diff 算法是深度优先遍历还是广度优先遍历,复杂度是多少? keep-alive 组件的两个生命周期是什么? nextTick 是宏任务,还是微任务
-
 字节跳动校招补录顺利oc!
字节跳动校招补录顺利oc!岗位:AIGC算法岗 base:北京 一面1.23算法题:1.无序数组第k大数,要求优化部分快排 2.链表相加 二面1.25算法题:1.二叉树非递归实现中序遍历 2.手撕nms和iou 三面1.30无算法 四面2.1 HR面 五面2.7技术加面 2.8 offer审批通过 年后谈薪 #字节#
-
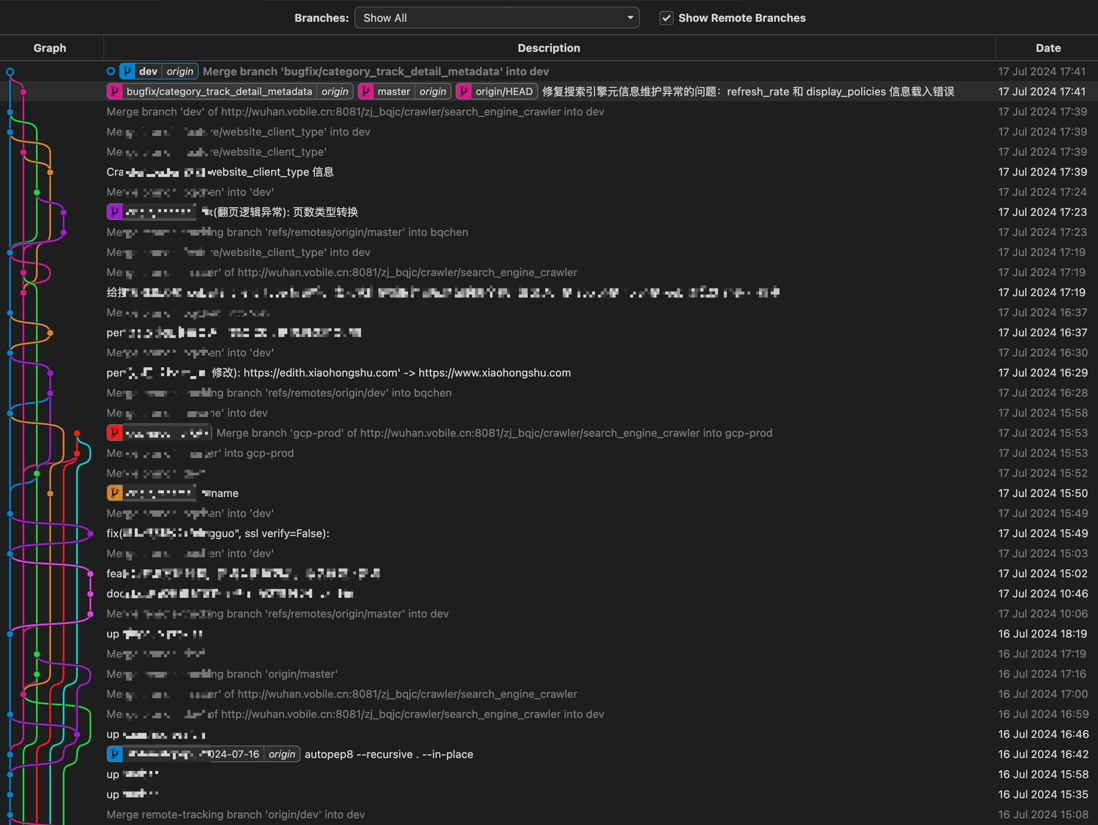 如何避免 git 提交记录拧成麻花?
如何避免 git 提交记录拧成麻花?感觉这样的提交记录让人看的头晕,这是好事还是坏事呢?我觉得不太好,看着很花,但是我们每天就是有很多人提 commit 做功能,怎么办? 优雅的提交记录管理和分支管理是什么样子的?
-
 【前端校招面经】理想汽车 2023 春招前端一二面面经
【前端校招面经】理想汽车 2023 春招前端一二面面经base: bj 今天下午脑子昏昏沉沉的, 头晕... 一面 自我介绍 Webpack 和 Vite 在配置上有很大差异, 你如何实现一个自动化工具, 将 Webpack 项目批量迁移到 Vite 假如你要对老旧项目的 eslint 进行升级, 你如何排查 eslint 因为配置或版本更新可能出现的报错 假如你要开发一个非常庞大的多级多选框组件, 你如何实现数据的异步加载? 🙌🌰: 页面上有三
-
页面对象模型讨论
我正在使用Selenium为我的网站构建一个测试框架,我实际上希望您在使用页面对象模型时对良好实践的想法:让我们说,我有一个欢迎页面,其中包含一个注销按钮存在的标题,这个标题可以在大多数页面中看到在我的页面中,我认为最好为标题写一个单独的类,比如: 公共类欢迎页 我的问题是,你认为在欢迎页面中包含标题作为属性更好还是应该将它们分开? 让我们以注销测试方法的代码为例: 案例一: 案例2: 第二个问题
-
从Kafka倒带偏移火花结构化流
我正在使用spark structured streaming(2.2.1)来消费来自Kafka(0.10)的主题。 我的检查点位置设置在外部HDFS目录上。在某些情况下,我希望重新启动流式应用程序,从一开始就消费数据。然而,即使我从HDFS目录中删除所有检查点数据并重新提交jar,Spark仍然能够找到我上次使用的偏移量并从那里恢复。偏移量还在哪里?我怀疑与Kafka消费者ID有关。但是,我无法
-
防止多个活动批处理火花流
我正在运行一个spark作业,流上下文每60秒运行一次。问题是一批处理时间太长(由于计算和保存RDD和Parquet到云存储),一批无法在1分钟内完成。它结束于下一批继续进入并成为活动的(状态=处理)。过了一段时间,我有10个活动批处理,而第一个已经完成。结果,它明显减慢,没有一批能够完成。是否存在严格限制一次活动批处理的数量为1。 多谢了。
-
Word2Vec : 阿帕奇火花和张量流实现
阅读 https://github.com/apache/spark/blob/master/mllib/src/main/scala/org/apache/spark/mllib/feature/Word2Vec.scala 这种实现的文字是谷歌Word2Vec的一个端口 https://code.google.com/archive/p/word2vec/ 这是“向量空间中单词表示的有效估计”
-
HDFS目录作为火花流中的参数
我在使用 Spark 流式处理示例时遇到问题:https://github.com/apache/spark/blob/master/examples/src/main/scala/org/apache/spark/streaming/examples/HdfsWordCount.scala 当我尝试使用 SBT 启动它时 我有这个例外 我确定该目录存在于Hadoop fs上,我甚至在那里复制了一
-
与流行为不同的平行流
结果:1 2 3 有人能解释为什么会发生这种情况,以及我如何让非并行版本给出与并行版本相同的结果吗?
-
使用akka流时的事件顺序
阅读akka-stream的留档,我不太清楚消息的顺序以及是否可以强制执行。让我用我为聊天服务器编写的一小段代码来设置我的问题的上下文。 为了让事情变得简单,我使用了这个流的形状和一个非常简单的源和汇。像这样的-- 现在,我的担忧来了。终端中打印的事件顺序根本不正常。我不知道该怎么解决。这是我得到的结果-- 输出中缺少第一条消息。消息似乎是在打印之前发送的。 我尝试通过使用(我在上面的代码中对此进
-
Apache Flink-连接流顺序和背压
下面的相同代码显示了两个源函数-一个产生0-20的偶数,另一个产生1-20的奇数,连接在一起以输出所有两个流的并集并将它们打印出来。 示例代码: 输出 Q1. Flink应该将连接流中最先到达的项目发送到协处理函数。然而,我们在这里看到的是,数字“2”是以源函数的方式在数字“11”之前生成的,但数字“11”是在“2”之前发送给协处理函数的。为什么会这样? 第二季度。 连接流中无背压发生。源函数一直
-
1.19 顺序执行和流程控制
脚本是一个命令一个命令顺序执行的。 Selenese 本身不支持条件语句(if - else, 等)或循环迭代(for, while, 等)。没有流程控制也可以制作很多有用的测试案例。然而,对于动态内容的功能测试,可能涉及到多个页面,编程逻辑通常是必要的。 如果必须使用流程控制,有以下三种解决方案: 使用 Selenium RC 运行脚本结合客户端库,如:Java 或 PHP 库,利用编程语言的流