
带纱线的火花流应用配置

在配置spark应用程序时,我试图从集群中挤出每一点,但似乎我并没有完全正确地理解每一件事。因此,我正在AWS EMR集群上运行该应用程序,该集群具有1个主节点和2个m3类型的核心节点。xlarge(每个节点15G ram和4个vCPU)。这意味着,默认情况下,每个节点上为纱线调度的应用程序保留11.25 GB。因此,主节点仅由资源管理器(纱线)使用,这意味着剩余的2个核心节点将用于调度应用程序(因此,我们有22.5G用于此目的)。到现在为止,一直都还不错。但我不明白的部分来了。我使用以下参数启动spark应用程序:
--驱动程序内存4G--num executors 4--executor cores 7--executor内存4G
根据我的理解(根据我所发现的信息),这意味着驱动程序将被分配4G,4个执行者将被启动,每个执行者都将使用4G。因此,粗略估计为5*4=20G(让我们用预期的内存储备将其设为21G),这应该很好,因为我们有22.5G用于应用程序。以下是hadoop发布后的UI截图:
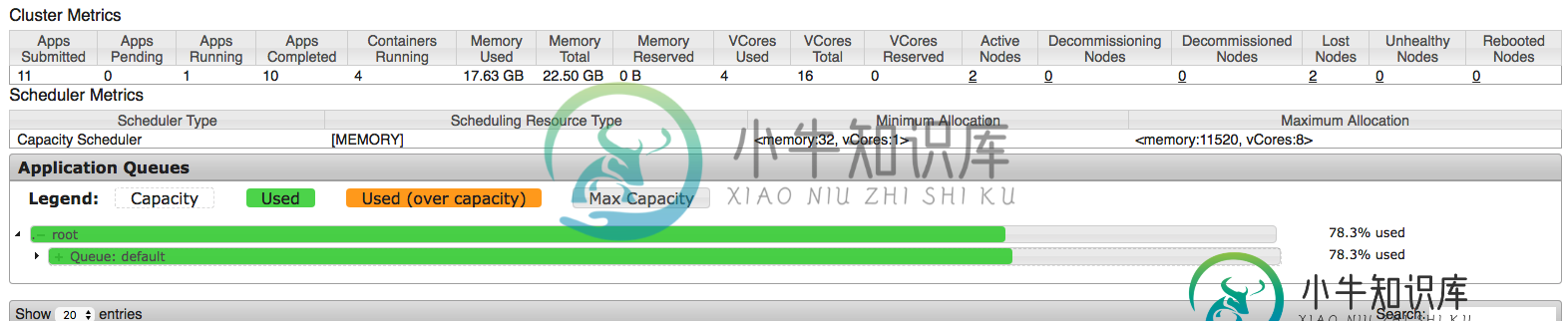
我们可以看到应用程序使用了17.63,但这比预期的~21G略少,这引发了第一个问题——这里发生了什么?
然后我转到spark UI的executors页面。更大的问题来了:
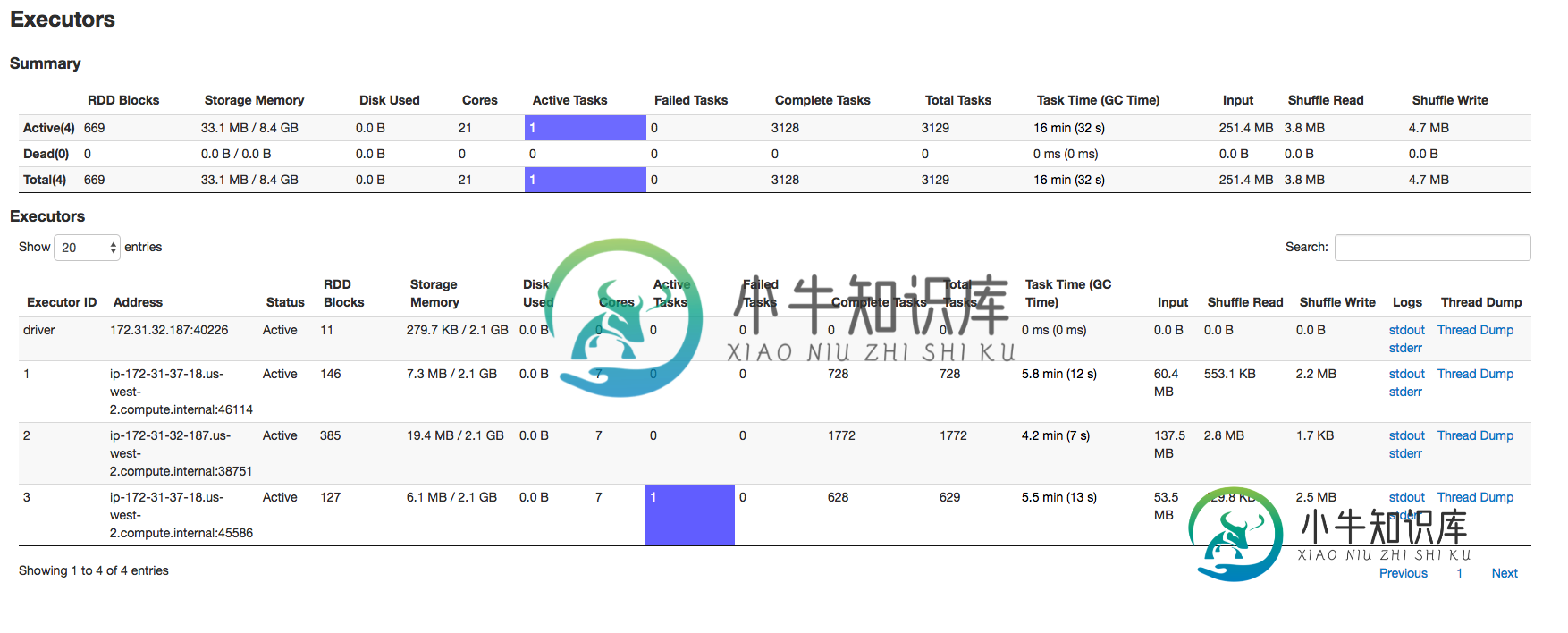
执行器是3个(不是4个),分配给它们的内存和驱动程序是2.1G(不是指定的4G)。因此hadoop纱线表示使用了17.63G,但spark表示分配了8.4G。那么,这里发生了什么?这是否与容量调度器有关(从文档中我无法得出这个结论)?
共有1个答案

你能检查一下是否有火花吗。动态定位。已启用。如果是这种情况,那么spark应用程序可能会在不再使用资源时将资源返回给集群。启动时要启动的执行器的最小数量将由spark决定。执行人。实例。
如果不是这样的话,spark应用程序的源是什么以及为此设置的分区大小是什么,spark会将分区大小映射到spark核心,如果源只有10个分区,并且当您尝试分配15个核心时,它只会使用10个核心,因为这是所需的。我想这可能是spark推出了3名执行者而不是4名执行者的原因。关于内存,我建议您重新访问,因为您需要4个执行器和1个4Gb驱动程序,每个4Gb大约等于22GB,并且您正在尝试用尽所有资源,您的操作系统和节点管理器运行的空间不多,这不是理想的方式。
-
我正在EMR EMR-4.3.0上运行一个spark应用程序,有1个主机和4个节点 它们每一个都有5GB内存和2个核心。 最后Yarn杀死了应用程序主人 错误ApplicationMaster:接收信号15:SIGTERM 1)我是否可以进一步改进num-executors和executor-core的spark-submit选项。
-
如果spark streaming在10秒的批处理间隔中获得50行消息,并且在40.5行消息之后,这10秒就结束了,剩下的时间落入另一个10秒的间隔中,前40.5行的文本是一个RDD被首先处理,在我的用例中,前40行是有意义的,但是下一个。5行没有意义,第二个RDD首先也是这样。5行,我的问题是否有效?。请提供建议如何处理这个问题?。 谢谢比尔。
-
我正在从我的开发机器上启动spark-submit。 根据在YARN文档上运行Spark,我应该在env var或上为hadoop集群配置提供一个路径。这就是它变得棘手的地方:如果我将任务发送到远程YARN服务,为什么这些文件夹必须存在于我的本地机器上?这是否意味着spark-submit必须位于集群内部,因此我不能远程启动spark任务?如果没有,我应该用什么填充这些文件夹?我应该从任务管理器服
-
首先,我想说的是我看到的解决这个问题的唯一方法是:Spark 1.6.1 SASL。但是,在为spark和yarn认证添加配置时,仍然不起作用。下面是我在Amazon's EMR的一个yarn集群上使用spark-submit对spark的配置: 注意,我用代码将spark.authenticate添加到了sparkContext的hadoop配置中,而不是core-site.xml(我假设我可以
-
我可以从IDE(远程)编程运行这个程序吗?我使用Scala-IDE。我寻找一些代码来遵循,但仍然没有找到合适的 我的环境:-Cloudera 5.8.2[OS redhat 7.2,kerberos 5,Spark2.1,scala 2.11]-Windows 7