《同花顺2024春招》专题
-
 24届秋招|顺丰笔试
24届秋招|顺丰笔试投递:产品经理岗位 题库:SHL 题库 题型:图形推理题,计算题,排序题,日程安排题(好像就是这几类,记不太清了) 特点:题量较大,难度中等,时间紧 一点心得: 1. 在开始前,认真做给出的练习题。一方面熟悉题型和答题方式,因为这个题库和北森牛客的答题方式差距还蛮大的;另一方面对题的难度有个大概的了解,测试题会比练习题难一点点,但没有很多。 2. 注意把控时间,我记得是36道题38分钟,差不多平均
-
 秋招顺丰测开123面
秋招顺丰测开123面timeline: 8.24投8.29笔9.4一面9.11线下二面后通知hr面 一面, 是个女面试官温温柔柔的,无手撕, http了解多少, sql了解多少 为什么选择测试, 大部分都是我直接开始吟唱八股, 反问了base业务和培养机制,认真回答了之后 又问了一下我的职业规划, 然后就结束了,一共12min。。。。。。。我都以为是KPI了没抱希望 二面 签到时会给你一个号码,对应一个大屋子里的10
-
 顺丰测开社招面经
顺丰测开社招面经时间线: 2024年1月9日 一面内容: 一面就面了25分钟,是不是凉了? 1、自我介绍 2、接口自动化怎么做的? 3、UI自动化怎么做的? 4、开发的测试提效平台的使用效果?讲解一下原理和背景? 5、所有工具能力建设的goodcase举例说一下 6、为什么离职? 7、反问 第一次面试时间这么短,但是整体聊得过程中没有磕绊,也很愉快。#顺丰##社招##测试开发工程师#
-
多个RDD的火花联合
问题内容: 在我的猪代码中,我这样做: 我想用spark做同样的事情。但是,不幸的是,我看到我必须成对进行: 是否有联合运算符可以让我一次对多个rdds进行操作: 例如 这是一个方便的问题。 问题答案: 如果这些是RDD,则可以使用方法: 没有等效项,但这只是一个简单的问题: 如果要在RDD上大量使用和重新创建,可能是避免与准备执行计划的成本相关的问题的更好选择:
-
如果还在火花流中
谢谢。
-
火花工和执行器芯
我有一个Spark集群运行在hdfs之上的纱线模式。我启动了一个带有2个内核和2G内存的worker。然后我提交了一个具有3个核心的1个执行器动态配置的作业。不过,我的工作还能运转。有人能解释启动worker的内核数量和为执行者请求的内核数量之间的差异吗。我的理解是,由于执行者在工人内部运行,他们无法获得比工人可用的资源更多的资源。
-
火花流和高可用性
我正在构建作用于多个流的Apache Spark应用程序。 我确实阅读了文档中的性能调优部分:http://spark.apache.org/docs/latest/streaming-programming-guide.html#performan-tuning 我没有得到的是: 1)流媒体接收器是位于多个工作节点上,还是位于驱动程序机器上? 2)如果接收数据的节点之一失败(断电/重新启动)会发
-
用TTL节省Cassandra的火花
我正在使用Spark-Cassandra连接器1.1.0和Cassandra 2.0.12。 谢谢, 沙伊
-
 Java实现雪花算法(snowflake)
Java实现雪花算法(snowflake)本文向大家介绍Java实现雪花算法(snowflake),包括了Java实现雪花算法(snowflake)的使用技巧和注意事项,需要的朋友参考一下 本文主要介绍了Java实现雪花算法(snowflake),分享给大家,具体如下: 简单描述 最高位是符号位,始终为0,不可用。 41位的时间序列,精确到毫秒级,41位的长度可以使用69年。时间位还有一个很重要的作用是可以根据时间进行排序。注意,41位时
-
扩展Node.js类时花括号
问题内容: 为什么在扩展Node.js类时将变量包装在大括号内,例如? 例如,Trevor Burnham在他的事件驱动CoffeeScript 教程中,通过以下方式扩展了Node的EventEmitter: 问题答案: 这个: 等效于以下JavaScript: 当您使用模块的导出返回一个对象时,这些导出之一就是“类”。使用只是退出返回对象的惯用快捷方式。您也可以这样说: 若你宁可。当您要提取对象
-
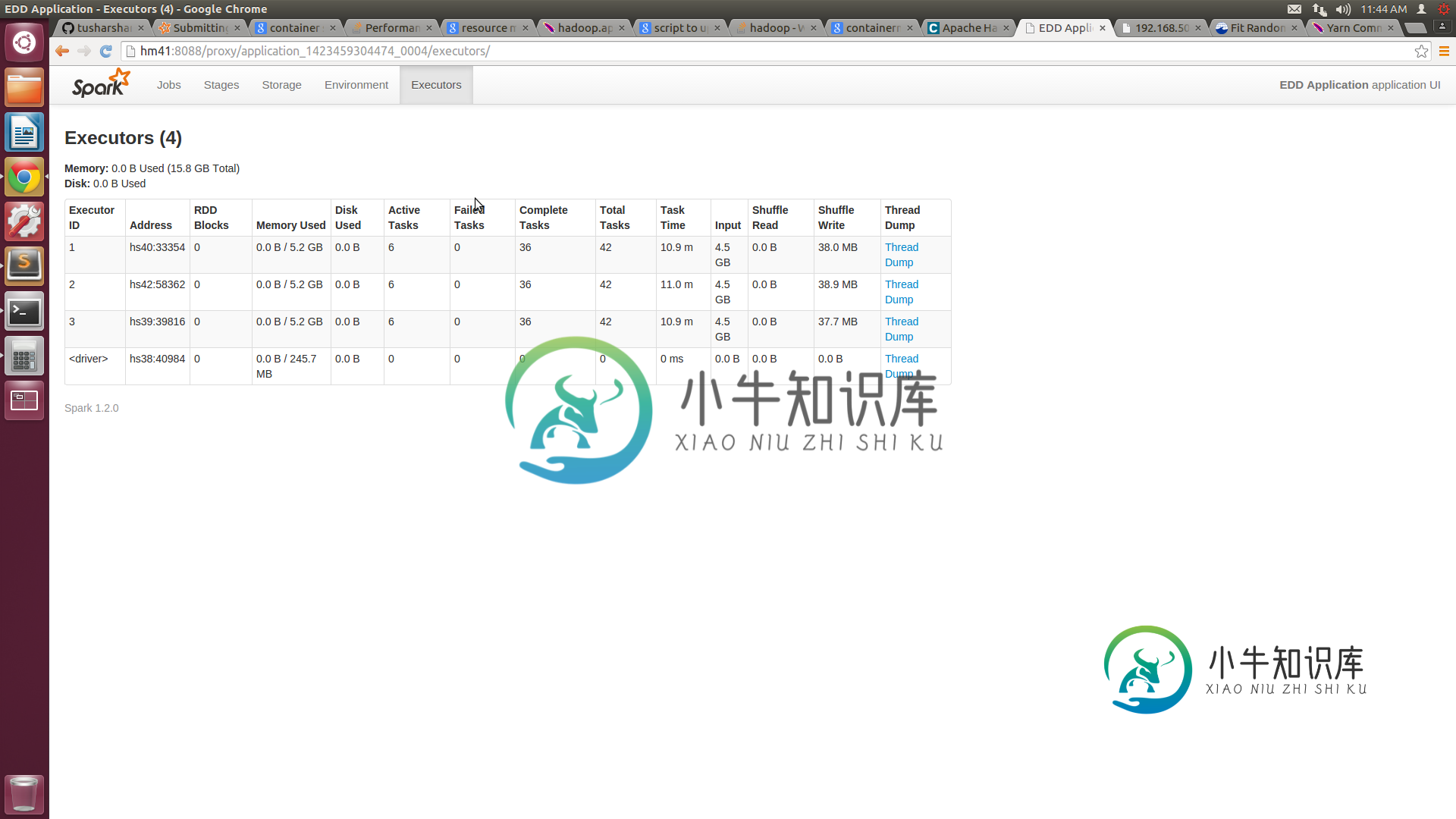 火花线的性能问题
火花线的性能问题我们正在尝试在纱线上运行我们的火花集群。我们有一些性能问题,尤其是与独立模式相比。 我们有一个由5个节点组成的集群,每个节点都有16GB的RAM和8个核心。我们已将纱线站点中的最小容器大小配置为3GB,最大为14GB。xml。向纱线集群提交作业时,我们提供的执行器数量=10,执行器内存=14 GB。根据我的理解,我们的工作应该分配4个14GB的容器。但spark UI仅显示3个容器,每个容器的容量
-
JS实现放烟花效果
本文向大家介绍JS实现放烟花效果,包括了JS实现放烟花效果的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了JS实现放烟花效果的具体代码,供大家参考,具体内容如下 move.js 更多JavaScript精彩特效分享给大家: Javascript菜单特效大全 javascript仿QQ特效汇总 JavaScript时钟特效汇总 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大
-
Kafka连接S3-JSON到拼花
Kafka是否将S3支持从JSON连接到Parquet?感谢使用Kafka Connect S3提供的可用和替代建议
-
引发异常的火花sortby
我正在尝试按键对JavaPairRDD进行排序。 块引号
-
Spark dataframe CSV vs拼花地板
我是Spark的初学者,试图理解Spark数据帧的机制。当从csv和parquet加载数据时,我比较了spark sql dataframe上sql查询的性能。我的理解是,一旦数据加载到spark数据框中,数据的来源(csv或parquet)应该无关紧要。然而,我看到了两者之间的显著性能差异。我使用以下命令加载数据,并对其编写查询。 请解释差异的原因。