
火花线的性能问题

我们正在尝试在纱线上运行我们的火花集群。我们有一些性能问题,尤其是与独立模式相比。
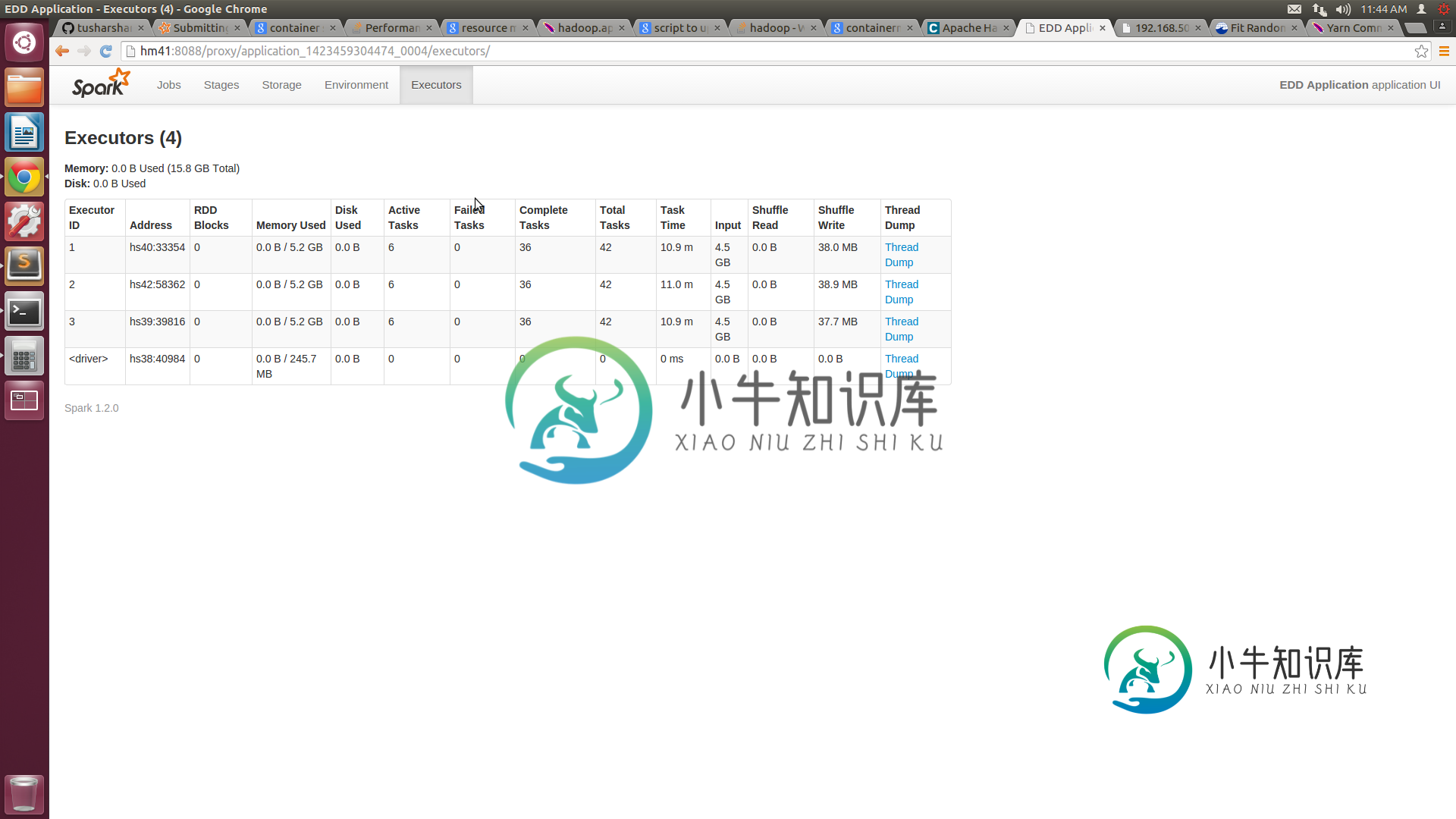
我们有一个由5个节点组成的集群,每个节点都有16GB的RAM和8个核心。我们已将纱线站点中的最小容器大小配置为3GB,最大为14GB。xml。向纱线集群提交作业时,我们提供的执行器数量=10,执行器内存=14 GB。根据我的理解,我们的工作应该分配4个14GB的容器。但spark UI仅显示3个容器,每个容器的容量为7.2GB。
我们无法确保集装箱编号和分配给它的资源。与独立模式相比,这会导致不利的性能。
关于如何优化纱线性能,你能给出任何建议吗?
这是我用于提交作业的命令:
$SPARK_HOME/bin/spark-submit --class "MyApp" --master yarn-cluster --num-executors 10 --executor-memory 14g target/scala-2.10/my-application_2.10-1.0.jar
讨论之后,我改变了我的纱线网站。xml文件以及spark submit命令。
这里是新的纱线网站。xml代码:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hm41</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>14336</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2560</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>13312</value>
</property>
火花提交的新命令是
$SPARK_HOME/bin/spark-submit --class "MyApp" --master yarn-cluster --num-executors 4 --executor-memory 10g --executor-cores 6 target/scala-2.10/my-application_2.10-1.0.jar
共有3个答案

仅仅因为YARN“认为”它有70GB(14GBx5),并不意味着在运行时集群上有70GB可用。您可以运行其他消耗内存的Hadoop组件(hive、HBase、flume、solr或您自己的应用程序等)。因此,纱线在运行时所做的决策是基于当前可用的数据,而您只有52GB(3x14GB)可用。顺便说一下,GB数字是近似值,因为它实际上是按每GB 1024MB计算的。。。所以你会看到小数。
使用nmon或top查看每个节点上还有哪些内存在使用。

- Withing纱线现场。xml检查
纱线。节点管理器。资源内存mb设置正确。据我所知,您的集群应该设置为14GB。此设置负责让纱线知道在该特定节点上可以使用多少内存 如果此设置正确,并且有5台服务器运行Thread NodeManager,则作业提交命令错误。首先,--num executors是要在集群上启动以执行的纱线容器的数量。您指定了10个容器,每个容器具有14GB RAM,但集群上没有这么多资源!其次,指定主纱线集群,这意味着Spark驱动程序将在需要单独容器的纱线应用程序主节点内运行- 在我看来,它显示了3个容器,因为在集群中的5个节点中,只有4个节点运行着YARN NodeManager,您请求为每个容器分配14GB,因此YARN首先启动Application Master,然后轮询NM以获取可用资源,并看到它只能启动3个容器。关于您看到的堆大小,启动Spark后,找到它的JVM容器并查看它们的启动参数-您应该在一行中有许多-Xmx标志-一个正确,一个错误,您应该在配置文件(Hadoop或Spark)中找到它的来源
- 在向群集提交应用程序之前,请使用相同的设置启动spark shell(将纱线群集替换为纱线客户端),并检查其启动方式,检查WebUI和JVM是否已启动

您在SparkUI中看到的内存(7.2GB)就是spark。存储memoryFraction,默认值为0.6。至于丢失的执行者,您应该查看纱线资源管理器日志。
-
我有两个大的Hive表,我想用spark.sql将它们连接起来。表格采用snappy格式,在Hive中存储为拼花文件。 我想加入它们并对某些列进行一些聚合,假设计算所有行和一列的平均值(例如 doubleColumn),同时使用两个条件进行过滤(假设在 col1,col2 上)。 注意:我在一台机器上进行测试安装(虽然功能非常强大)。我希望集群中的性能可能会有所不同。 我的第一个尝试是使用spar
-
我在Scala/Spark中有一个批处理作业,它根据一些输入动态创建Drools规则,然后评估规则。我还有一个与要插入到规则引擎的事实相对应的输入。 到目前为止,我正在一个接一个地插入事实,然后触发关于这个事实的所有规则。我正在使用执行此操作。 seqOp运算符的定义如下: 以下是生成的规则的示例: 对于同一RDD,该批次花了20分钟来评估3K规则,但花了10小时来评估10K规则! 我想知道根据事
-
我正在尝试 https://github.com/apache/spark/blob/v2.0.1/examples/src/main/scala/org/apache/spark/examples/sql/streaming/StructuredNetworkWordCountWindowed.scala 个例子。 但是,指定端口号处的输入应该是什么?
-
我有一些Spark经验,但刚开始使用Cassandra。我正在尝试进行非常简单的阅读,但性能非常差——不知道为什么。这是我正在使用的代码: 所有3个参数都是表上键的一部分: 主键(group\u id,epoch,group\u name,auto\u generated\u uuid\u field),聚类顺序为(epoch ASC,group\u name ASC,auto\u generat
-
嗨,我对Spark很陌生。我正在Apache Spark scala命令行上执行以下命令
-
我的 Spark 版本是 2.2.0,它在本地工作,但在具有相同版本的 EMR 上,它给出了以下异常。