《高通》专题
-
如何高效处理Spring Boot微服务?
我有一堆在唯一端口中运行的Spring启动微服务。我们如何在生产中处理这些微服务? 在生产中,我们只需要DNS,如何处理DNS映射。 例如:示例微服务-1(端口:8001) 示例微服务-2(端口:8002) 示例微服务-3(端口:8003) 示例微服务-4(端口:8004) 示例微服务-5(端口:8005) 我想要下面的东西, myprod。com/example-microservice-1 m
-
如何提高JScrollPane上的滚动速度?
我正在项目的中添加。 所有工作都很好,但在JPanel中使用鼠标滚轮滚动鼠标存在一个问题。滚动时速度很慢。如何让它更快? 我的代码是:
-
 在flex中以高度100%拟合图像
在flex中以高度100%拟合图像我有一个响应的背景图像在一个div。我想要一个两列柔性布局在它的顶部,其中左布局有图像的高度100%的父div与宽度自动缩放像响应图像。右边是以Flex为中心的两行文本。 这是目前为止我能得到的最接近的。但当浏览器调整大小时,flex不会拉伸以适应背景div图像,左侧图像也不会相应地缩放。 注意:代码中不应指定px的宽度和高度 null null
-
2图表高图打印成PDF格式
我有2个(或以上)海图,需要打印成PDF格式。我用PDf导出表单highchrt,它可以打印但只是打印1张图表。我的代码怎么了?或者有什么解决我问题的办法吗? 这是我的密码。 null null
-
JetBrains IDE中的自定义语法高亮
有没有办法将自定义语言语法高亮添加到JetBrains IDE? 在我的例子中,我想突出显示PyCharm中的MATLAB代码。IDE建议我使用“Mathematica”插件,但它不能正常工作。
-
PyCharm Professional 中的 JavaScript 语法高亮显示
我在专业版的PyCharm中使用sekizai来控制我的JavaScript代码在页面中的呈现位置。 在我的django模板代码中,这意味着我的JavaScript没有包含在通常的
-
 D3 Y刻度,Y与高度的关系?
D3 Y刻度,Y与高度的关系?我正在学习D3,我可以看到我用这两件事得到了相同的可视化: 使用height属性: 或设置Y: 其中任何一个都是正确的,如果是,为什么?
-
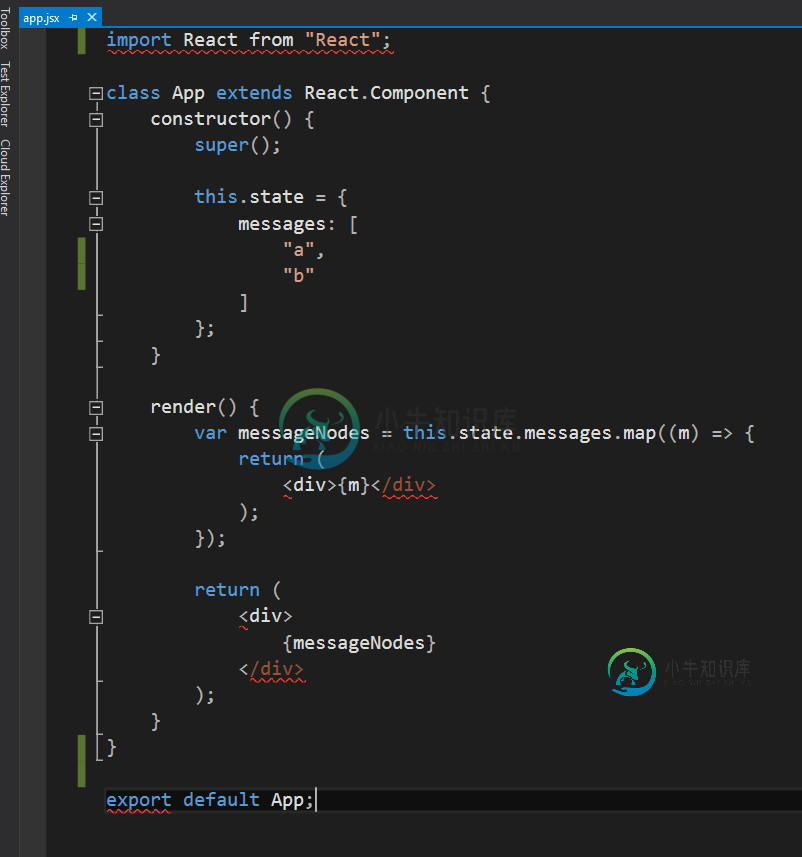 Visual Studio 2015 JSX/ES2015语法高亮显示
Visual Studio 2015 JSX/ES2015语法高亮显示如何使用ES2015代码在Visual Studio 2015 for JSX中获得正确的语法高亮显示? 我刚刚更新到Visual Studio 2015 Enterprise Update,但它仍然保持不变。
-
为什么冒泡排序效率不高?
我正在使用Node.js开发后端项目,并打算实现产品排序功能。我研究了一些文章,有几篇文章说泡泡排序不是有效的。泡泡排序在我以前的项目中使用,我很惊讶为什么它是不好的。有人能解释一下为什么效率低下吗?如果您能用c编程或汇编命令来解释,将不胜感激。
-
Postman中的(高度动态)环境变量
Postman支持设置环境变量,并在例如标题中使用它们。 考虑以下示例: 令牌endpoint需要基本标头: 所有其他endpoint都需要承载标头: 目前,我需要完成以下所有步骤,这非常烦人: 调用 从响应中手动复制令牌 转到<code>设置 是否有一种方法可以在每次调用时自动更新环境变量,或者至少始终显示当前环境变量的列表,以便我可以手动更新值,而无需转到
-
提高Spark反规范化/分区性能
我有一个非规范化用例——一个hiveavro事实表与14个较小的维度表连接,生成一个非规格化拼花输出表。输入事实表和输出表都以相同的方式进行分区(Category=TEST1,YearMonthId=202101)。我确实运行历史处理,这意味着一次处理并加载给定类别的几个月。 我使用的是Spark 2.4.0/pyspark数据帧,所有表连接的广播连接,动态分区插入,最后使用colasce来控制输
-
获取iOS 7中的NSString高度[重复]
我使用下面的代码从字符串长度计算标签的高度。我使用的是xcode 5.0,它在iOS 6模拟器中运行良好,但在iOS 7中运行不佳。 如果iOS 7有任何解决方案,请提供帮助。提前致谢
-
用线性类型降低高阶函数
我最近一直在试验线性类型,一直在想下面的转换是否可能。如果没有线性类型,它肯定是无效的。 目的是降低高阶函数参数。这应该是可以的,因为线性类型确保HOF只被调用一次,所以正好存在一个值。问题是如何避开lambda并观察
-
是可以提高一些字使用StringToWordVector
我正在使用StringToWordVector朴素贝叶斯和StringToWordVector对一些文本进行分类。我还使用TD/IDF对单词进行评分。 在训练过程中,有没有一种简单的方法来增加一些单词(我自己选择)的分数,从而增加这些单词在给定课程模型中的权重?因此,如果这些单词出现在一个新文档中,分类器就会知道该文档属于此类的可能性更大。 谢谢
-
Kafka-设置高linger.ms和batch.size没有帮助
我试图提高Kafka生产者的吞吐量,我们有CSV报告,正在得到过程和发布到Kafka主题。使用默认的Kafka设置,我们得到的平均Kafka吞吐量。为了提高吞吐量,我尝试测试了一些组合与和,但它没有帮助。 试图与 甚至试过用更少的玲珑。ms和batch。大小 但吞吐量仍在150-200kbps左右 但吞吐量正在下降到100-150kbps。 Kafka主题有12个分区。 欢迎提出任何建议。