《分布式锁》专题
-
如何生成服从正态分布模式的随机数?
我将需要初始化一个'n'数量的类,将有一个随机值附加到他们从1到100。 我知道如何创建一个介于1和100之间的随机值,但我如何使所有的值都落在一个正态分布模式?
-
 百度 | 分布式计算研发工程师 | 一面(凉经)
百度 | 分布式计算研发工程师 | 一面(凉经)前言 被百度从人才库里捞出来面试,职位是上海-分布式计算研发工程师,面试形式:电话 一面(12月23日,45min) 自我介绍 实习项目(10min) 介绍一下实习期间做的项目? 简历项目(5min) 介绍一下简历上的第一个项目? 为什么要用Redis分布式锁解决超卖和一人一单? Redis分布式锁是否设置了超时时间? 介绍一下简历上的第二个项目? Java基础 String转Integer的方法
-
本地分布式开发环境搭建(使用Vagrant和Virtualbox)
注意:本文停止更新,请直接转到kubernetes-vagrant-centos-cluster仓库浏览最新版本。 当我们需要在本地开发时,更希望能够有一个开箱即用又可以方便定制的分布式开发环境,这样才能对Kubernetes本身和应用进行更好的测试。现在我们使用Vagrant和VirtualBox来创建一个这样的环境。 部署时需要使用的配置文件和vagrantfile请见:https://git
-
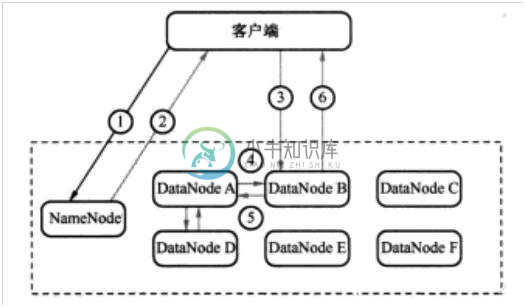 Hadoop分布式文件系统HDFS的工作原理详述
Hadoop分布式文件系统HDFS的工作原理详述Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。它能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。要理解HDFS的内部工作原理,首先要理解什么是分布式文件系统。 1.分布式文件系统 多台计算机联网协同工作(有时也称为一个集群)就像单台系统一样解决某种问题,这样的系统我们称之为分布式系统。 分布
-
原理分析之预发布灰度发布
SOP网关采用自定义负载均衡策略来实现对预发布/灰度发布服务器实例的选择。 spring cloud gateway默认的负载均衡实现类在:org.springframework.cloud.gateway.filter.LoadBalancerClientFilter.java中 这个类主要做了几件事情: 解析出请求路径中的scheme 如果scheme不是以lb协议开头直接跳过 如果schem
-
Log4j2模式布局时间戳格式
我想指定特定格式的日志记录时间戳%d{YYYY-MM-dd HH: mm: ss. SSS},但是我操作模式,时间戳显示为2015-10-19 00:47:15,423。 指定%d{ISO8601}或%d{ABSOLUTE}正在生效。我想知道当指定自定义模式时,如何选择时间戳格式。 如果我想将逗号分隔符改为句号,有没有办法做到这一点?
-
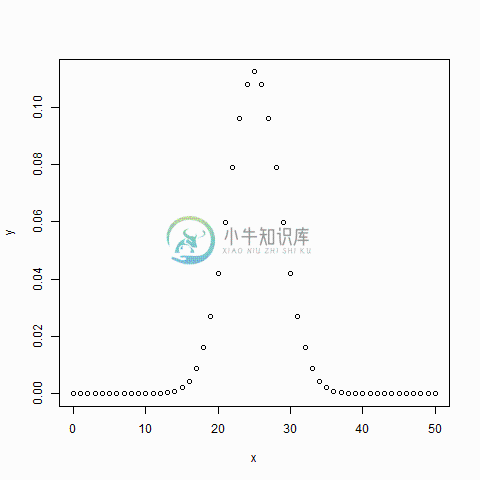 R语言二项分布
R语言二项分布主要内容:1.dbinom()函数,2.pbinom()函数,3.qbinom()函数,4.rbinom()函数二项分布模型用来处理在一系列实验中只发现两个可能结果的事件的成功概率。 例如,掷硬币总是两种结果:正面或反面。使用二项式分布估算在重复抛掷硬币次时正好准确地找到次是正面的概率。 R具有四个内置函数来生成二项分布,它们在下面描述。 以下是使用的参数的描述 - x - 是数字的向量。 p - 是概率向量。 n - 是观察次数。 size - 是试验的次数。 prob - 是每次试验成功的概
-
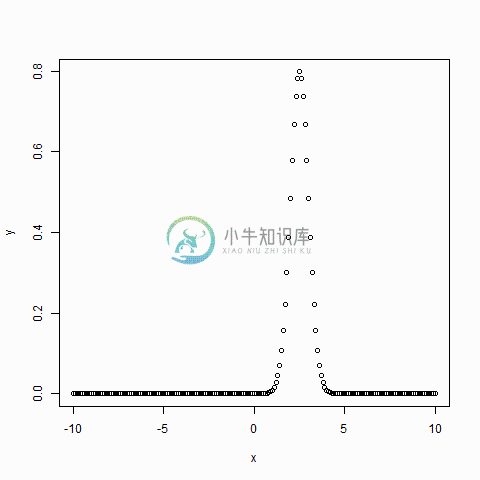 R语言正态分布
R语言正态分布在随机收集来自独立来源的数据中,通常观察到数据的分布是正常的。 这意味着,在绘制水平轴上的变量的值和垂直轴中的值的计数时,我们得到一个钟形曲线。 曲线的中心代表数据集的平均值。 在图中,百分之五十的值位于平均值的左侧,另外五十分之一位于图的右侧。 统称为正态分布。 R有四个内置函数来生成正态分布。它们在下面描述 - 以下是上述函数中使用的参数的描述 - x - 是数字的向量。 p - 是概率向量。
-
1.23 多元高斯分布
多元高斯分布 介绍 我们称一个概率密度函数是一个均值为$\mu\in R^n$,协方差矩阵为$\Sigma\in S_{++}^n$的$^1$一个多元正态分布(或高斯分布)(multivariate normal (or Gaussian) distribution), 其随机变量是向量值$X=[X_1\dots X_n]^T$,该概率密度函数$^2$可以通过下式表达: 上一小段上标1,2的说明(
-
1.3.2.15 地域分布(按省)
地域分布(按省) 关键参数 报告 method metrics(指标, 数据单位) 其他参数 地域分布 visit/district/a (按省) pv_count (浏览量(PV)) pv_ratio (浏览量占比,%) visit_count (访问次数) visitor_count (访客数(UV)) new_visitor_count (新访客数) new_visitor_ratio (新
-
倾斜的正态分布
问题内容: 有谁知道如何用scipy绘制偏态正态分布?我认为可以使用stats.norm类,但我不知道如何使用。此外,如何估计描述一维数据集偏斜正态分布的参数? 问题答案: 根据Wikipedia的描述, 如果你想找到一个数据集的使用规模,位置和形状参数,例如使用,并且, 应该给你类似的东西,
-
JavaScript 高斯分布随机
本文向大家介绍JavaScript 高斯分布随机,包括了JavaScript 高斯分布随机的使用技巧和注意事项,需要的朋友参考一下 示例 该函数应提供标准偏差接近0的随机数。从一副纸牌中拾取或模拟骰子掷骰时,这就是我们想要的。Math.random() 但是在大多数情况下,这是不现实的。在现实世界中,随机性倾向于聚集在一个共同的正常值附近。如果将其绘制在图形上,则会得到经典的钟形曲线或高斯分布。
-
Cassandra多重写入分布
我安装了一个3节点Cassandra (2.0.3)群集,这是我的表格: 我用datastax java驱动 这是我创建的用户对象: 我创建了其中的10k - i是我的用户数组中的用户的索引。我不想使用批量插入,而是模拟插入多个记录的压力。这是我的代码: < li >计算记录数量时(使用cqlsh),我从未超过4k(10k中) < li >只有一台服务器进行写入(使用opscenter写入请求/所
-
Jmeter分布配置设置
完成以下步骤:主机>编辑jmeter文件,并将远程主机ip=10.21.4.199和从机启动JMeter-Server,所有机器都是相同的子网,使用相同的java和jmeter版本。问题是:1>不运行从机。可以提供一步一步的步骤,Plz不添加jmeter分发pdf的通用pdf。2>脚本在没有远程主机的情况下运行,请为空。3>必须在主机上运行脚本? 你能解释其他一点吗?意思是:
-
20. 连续分布的熵
离散概率集的熵已经定义为: 。 对于一个概率密度函数为的连续分布,可以采用类似方式,将它的熵定义为: 。 对于一个n维分布,有: 。 如果有两个参数和(它们本身可能是多维的),则的联合熵和条件熵分别为: 和 其中: 。 连续分布的熵具有离散分布的大多数性质(但不是全部性质)。具体来说,有: 如果限定于其空间中的一个特定空间,则为最大值,当在其空间内为常数时,等于。 对于任意两个变量,有: 当(且仅