《分布式锁》专题
-
使用argparse分析布尔值
我想使用argparse解析写为“--foo true”或“--foo false”的布尔命令行参数。例如: 但是,下面的测试代码并没有做我想做的事情: 遗憾的是,的计算结果为。即使我将更改为时也是如此,这是令人惊讶的,因为的计算结果为。 如何使argparse将、及其小写变体解析为?
-
随机化SearchCV采样分布
根据RandomizedSearchCV文件(重点是mine): param_distributions:字典或字典列表 使用参数名称 (str) 作为键的字典,以及要尝试的分布或参数列表。分布必须提供 rvs 方法进行采样(例如来自 scipy.stats.分布的方法)。如果给出了一个列表,则对其进行统一采样。如果给出了字典列表,则首先对字典进行统一采样,然后如上所述使用该字典对参数进行采样。
-
观察的分布(Distribution of Observations)
在我们在前一章中讨论的分类散点图中,该方法在它可以提供的关于每个类别中的值分布的信息中受到限制。 现在,进一步说,让我们看看什么可以促进我们与类别进行比较。 方块图 Boxplot是一种通过四分位数可视化数据分布的便捷方式。 箱形图通常具有从箱子延伸的垂直线,其被称为晶须。 这些晶须表明在上下四分位数之外的可变性,因此Box Plots也被称为box-and-whisker图和box-and-wh
-
概率论07 联合分布
我之前一直专注于单一的随机变量及其概率分布。我们自然的会想将以前的结论推广到多个随机变量。联合分布(joint distribution)描述了多个随机变量的概率分布,是对单一随机变量的自然拓展。联合分布的多个随机变量都定义在同一个样本空间中。 对于联合分布来说,最核心的依然是概率测度这一概念。 离散随机变量的联合分布 我们先从离散的情况出发,了解多个随机变量并存的含义。 之前说,一个随机变量是从
-
概率论06 连续分布
在随机变量中,我提到了连续随机变量。相对于离散随机变量,连续随机变量可以在一个连续区间内取值。比如一个均匀分布,从0到1的区间内取值。一个区间内包含了无穷多个实数,连续随机变量的取值就有无穷多个可能。 为了表示连续随机变量的概率分布,我们可以使用累积分布函数或者密度函数。密度函数是对累积分布函数的微分。连续随机变量在某个区间内的概率可以使用累积分布函数相减获得,即密度函数在相应区间的积分。 在随机
-
概率论05 离散分布
我们已经知道什么是离散随机变量。离散随机变量只能取有限的数个离散值,比如投掷一个撒子出现的点数为随机变量,可以取1,2,3,4,5,6。每个值对应有发生的概率,构成该离散随机变量的概率分布。 离散随机变量有很多种,但有一些经典的分布经常重复出现。对这些经典分布的研究,也占据了概率论相当的一部分篇幅。我们将了解一些离散随机变量的经典分布,了解它们的含义和特征。 伯努利分布 伯努利分布(Bernoul
-
发布一个本地分支
在你明确地决定将一个本地分支发布到远程仓库之前,这些在你本地计算机上创建的分支是不能被其他的团队成员看到的,它只是你的私有分支。这就意味着,你可以保留某些改动仅仅在你私有的本地分支上,而与其他团队成员分享一些其它分支上的改动。 现在让我们来分享 “contact-form” 分支(它直到现在还仅仅是个私有的本地分支)到 “origin” 远程上: $ git checkout contact-fo
-
Apache Kafka分区未使用RoundRobin分区器均匀分布
我正在使用Kafka Producer和RoundRobin分区器来处理一个有12个分区的主题。 代码可在此处找到https://github.com/apache/kafka/blob/2.8/clients/src/main/java/org/apache/kafka/clients/producer/RoundRobinPartitioner.java 我面临的问题是,这个分区程序让分区正确
-
 springboot 打包部署 共享依赖包(分布式开发集中式部署微服务)
springboot 打包部署 共享依赖包(分布式开发集中式部署微服务)本文向大家介绍springboot 打包部署 共享依赖包(分布式开发集中式部署微服务),包括了springboot 打包部署 共享依赖包(分布式开发集中式部署微服务)的使用技巧和注意事项,需要的朋友参考一下 1、此文初衷 平常我们在进行微服务开发完毕后,单个微服务理应部署单个虚机上(docker也可),然后服务集中发布到服务注册中心上,但是有些小的项目,这样做未免太过繁杂增加了部署难度,这里主要讲
-
详解SpringBoot基于Dubbo和Seata的分布式事务解决方案
本文向大家介绍详解SpringBoot基于Dubbo和Seata的分布式事务解决方案,包括了详解SpringBoot基于Dubbo和Seata的分布式事务解决方案的使用技巧和注意事项,需要的朋友参考一下 1. 分布式事务初探 一般来说,目前市面上的数据库都支持本地事务,也就是在你的应用程序中,在一个数据库连接下的操作,可以很容易的实现事务的操作。 但是目前,基于SOA的思想,大部分项目都采用微服务
-
Spring中使用atomikos+druid实现经典分布式事务的方法
本文向大家介绍Spring中使用atomikos+druid实现经典分布式事务的方法,包括了Spring中使用atomikos+druid实现经典分布式事务的方法的使用技巧和注意事项,需要的朋友参考一下 经典分布式事务,是相对互联网中的柔性分布式事务而言,其特性为ACID原则,包括原子性(Atomictiy)、一致性(Consistency)、隔离性(Isolation)、持久性(Durabili
-
2.3.7 分布式服务接口请求的顺序性如何保证?
面试题 分布式服务接口请求的顺序性如何保证? 面试官心理分析 其实分布式系统接口的调用顺序,也是个问题,一般来说是不用保证顺序的。但是有时候可能确实是需要严格的顺序保证。给大家举个例子,你服务 A 调用服务 B,先插入再删除。好,结果俩请求过去了,落在不同机器上,可能插入请求因为某些原因执行慢了一些,导致删除请求先执行了,此时因为没数据所以啥效果也没有;结果这个时候插入请求过来了,好,数据插入进去
-
详解spring cloud config整合gitlab搭建分布式的配置中心
本文向大家介绍详解spring cloud config整合gitlab搭建分布式的配置中心,包括了详解spring cloud config整合gitlab搭建分布式的配置中心的使用技巧和注意事项,需要的朋友参考一下 在前面的博客中,我们都是将配置文件放在各自的服务中,但是这样做有一个缺点,一旦配置修改了,那么我们就必须停机,然后修改配置文件后再进行上线,服务少的话,这样做还无可厚非,但是如果是
-
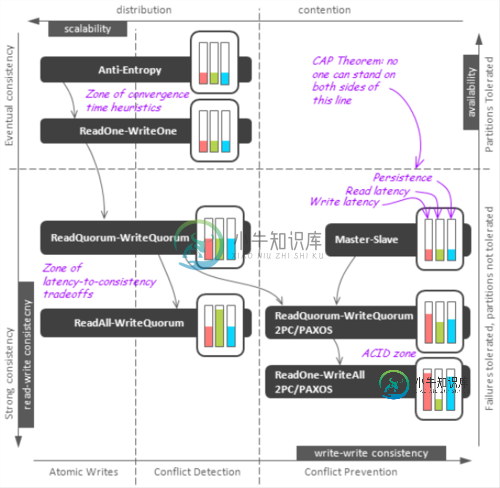 深入解析NoSQL数据库的分布式算法(图文详解)
深入解析NoSQL数据库的分布式算法(图文详解)本文向大家介绍深入解析NoSQL数据库的分布式算法(图文详解),包括了深入解析NoSQL数据库的分布式算法(图文详解)的使用技巧和注意事项,需要的朋友参考一下 尽管NoSQL运动并没有给分布式数据处理带来根本性的技术变革,但是依然引发了铺天盖地的关于各种协议和算法的研究以及实践。在这篇文章里,我将针对NoSQL数据库的分布式特点进行一些系统化的描述。 系统的可扩展性是推动NoSQL运动发展的的主要
-
用Hazelcast将单个节点转换为分布式java应用程序
基本上我们有2: 我们有2个,以便根据组的ID轻松地查询组,并知道哪些组属于我们的成员。 但是,根据文档,使用,应该可以只创建一个映射: null