《分布式锁》专题
-
正态分布( Normal Distribution)
在来自独立来源的随机数据集中,通常观察到数据的分布是正常的。 这意味着,在绘制具有水平轴中变量值的图形和垂直轴中的值的计数时,我们得到钟形曲线。 曲线的中心表示数据集的平均值。 在图中,百分之五十的值位于均值的左侧,另外百分之五十位于图的右侧。 这在统计学中称为正态分布。 R有四个内置函数来生成正态分布。 它们如下所述。 dnorm(x, mean, sd) pnorm(x, mean, sd)
-
比较memcache,redis和ehcache作为分布式缓存框架
问题内容: 我需要做出的决定之一是在系统中使用哪种缓存框架。有这么多选择,我目前正在研究redis,ehcache和memcached。 谁能指出这三个特定框架的性能基准?还概述了它们的功能-我对缺点特别感兴趣,即。在一种情况下您会使用另一种情况。 问题答案: 这里有一个小的功能比较:http : //toddrobinson.com/appfabric/appfabric-cache-featu
-
有关.NET分布式缓存解决方案的建议
问题内容: 我们的生产Web服务器有一台运行Windows Server 2003的服务器。我们的网站具有不同的模块,每个模块都在其自己的应用程序池中运行。由于每个模块都有自己的缓存,而且经常有多个模块缓存相同的项目,因此这使缓存有点问题。问题是,当在一个模块中更改了缓存中的项目时,无法轻松地刷新缓存同一项目的另一个模块。 我们的网站是用ASP.NET 4.0编写的,我们使用标准的HttpRunt
-
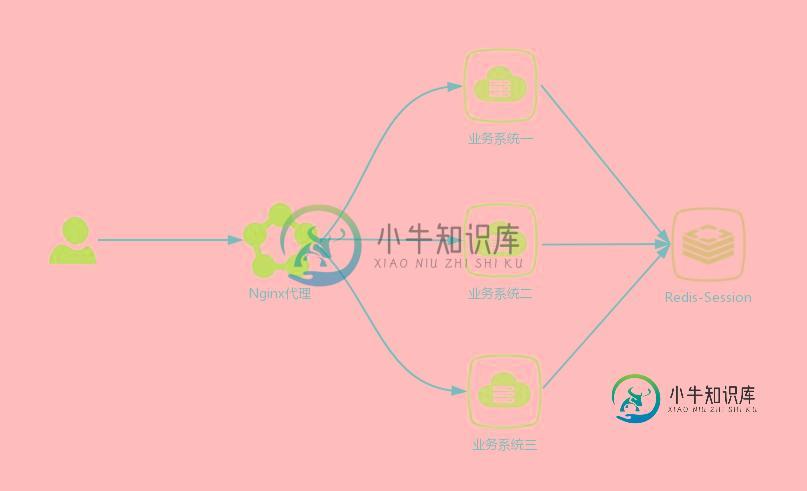 SpringBoot开发案例 分布式集群共享Session详解
SpringBoot开发案例 分布式集群共享Session详解本文向大家介绍SpringBoot开发案例 分布式集群共享Session详解,包括了SpringBoot开发案例 分布式集群共享Session详解的使用技巧和注意事项,需要的朋友参考一下 前言 在分布式系统中,为了提升系统性能,通常会对单体项目进行拆分,分解成多个基于功能的微服务,如果有条件,可能还会对单个微服务进行水平扩展,保证服务高可用。 那么问题来了,如果使用传统管理 Session 的方式
-
Springboot-dubbo-fescar 阿里分布式事务的实现方法
本文向大家介绍Springboot-dubbo-fescar 阿里分布式事务的实现方法,包括了Springboot-dubbo-fescar 阿里分布式事务的实现方法的使用技巧和注意事项,需要的朋友参考一下 大家可以自行百度下阿里分布式事务,在这里我就不啰嗦了。下面是阿里分布式事务开源框架的一些资料,本文是springboot+dubbo+fescar的集成。 快速开始 https://githu
-
2.6.1 集群部署时的分布式 Session 如何实现?
面试题 集群部署时的分布式 session 如何实现? 面试官心理分析 面试官问了你一堆 dubbo 是怎么玩儿的,你会玩儿 dubbo 就可以把单块系统弄成分布式系统,然后分布式之后接踵而来的就是一堆问题,最大的问题就是分布式事务、接口幂等性、分布式锁,还有最后一个就是分布式 session。 当然了,分布式系统中的问题何止这么一点,非常之多,复杂度很高,这里只是说一下常见的几个问题,也是面试的
-
相关软件介绍/HBase/HBase分布式安装手册
一、安装准备 1、下载HBASE 0.20.5版本:http://www.apache.org/dist/hbase/hbase-0.20.5/ 2、JDK版本:jdk-6u20-linux-i586.bin 3、操作系统:Linux s132 2.6.9-78.8AXS2smp #1 SMP Tue Dec 16 02:42:55 EST 2008 x86_64 x86_64 x86_64 GN
-
 基于Redis实现分布式应用限流的方法
基于Redis实现分布式应用限流的方法本文向大家介绍基于Redis实现分布式应用限流的方法,包括了基于Redis实现分布式应用限流的方法的使用技巧和注意事项,需要的朋友参考一下 限流的目的是通过对并发访问/请求进行限速或者一个时间窗口内的的请求进行限速来保护系统,一旦达到限制速率则可以拒绝服务。 前几天在DD的公众号,看了一篇关于使用 瓜娃 实现单应用限流的方案 --》原文,参考《redis in action》 实现了一个jedis
-
 基于CentOS的Hadoop分布式环境的搭建开发
基于CentOS的Hadoop分布式环境的搭建开发本文向大家介绍基于CentOS的Hadoop分布式环境的搭建开发,包括了基于CentOS的Hadoop分布式环境的搭建开发的使用技巧和注意事项,需要的朋友参考一下 首先,要说明的一点的是,我不想重复发明轮子。如果想要搭建Hadoop环境,网上有很多详细的步骤和命令代码,我不想再重复记录。 其次,我要说的是我也是新手,对于Hadoop也不是很熟悉。但是就是想实际搭建好环境,看看他的庐山真面目,还好,
-
Tensorflow:在分布式培训中使用参数服务器
问题内容: 尚不清楚参数服务器如何知道分布式张量流训练中的操作。 例如,在此SO问题中,以下代码用于配置参数服务器和工作程序任务: 如何指示给定的任务应该是参数服务器?参数是一种默认的任务行为吗?您还能/应该告诉参数服务任务做什么? 编辑 :这个SO问题解决了我的一些问题:“逻辑确保将Variable对象均匀分配给充当参数服务器的工作程序。” 但是参数服务器如何知道它是参数服务器?是否足够? 问题
-
Hadoop 2.x伪分布式环境搭建详细步骤
本文向大家介绍Hadoop 2.x伪分布式环境搭建详细步骤,包括了Hadoop 2.x伪分布式环境搭建详细步骤的使用技巧和注意事项,需要的朋友参考一下 本文以图文结合的方式详细介绍了Hadoop 2.x伪分布式环境搭建的全过程,供大家参考,具体内容如下 1、修改hadoop-env.sh、yarn-env.sh、mapred-env.sh 方法:使用notepad++(beifeng用户)打开这三
-
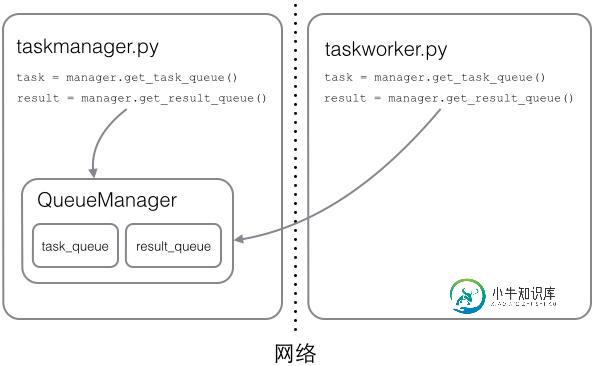 在Python程序中实现分布式进程的教程
在Python程序中实现分布式进程的教程本文向大家介绍在Python程序中实现分布式进程的教程,包括了在Python程序中实现分布式进程的教程的使用技巧和注意事项,需要的朋友参考一下 在Thread和Process中,应当优选Process,因为Process更稳定,而且,Process可以分布到多台机器上,而Thread最多只能分布到同一台机器的多个CPU上。 Python的multiprocessing模块不但支持多进程,其中man
-
基于Spring批处理和AMQP的分布式批处理
我想分散加工大批量。这个想法是使用Spring Batch在云中激发一堆AMQP消费者,然后加载廉价的任务(如项目ID)并将它们提交给AMQP交换。结果的书写将由消费者自己完成。 null
-
Hadoop伪分布式java.net.ConnectException:在虚拟框上拒绝连接
我已经在ubuntu上安装了hadoop,它运行在VirtualBox上。当我第一次安装hadoop时,我可以毫无问题地启动hdfs和创建目录。 但是当我重新启动虚拟机后,当尝试在HDFS上运行ls命令时,我得到了“拒绝连接”的错误。然后,我根据Hadoop集群设置在sshd_config中添加了“端口9000”-java.net.connectException:Connection Relec
-
Karaf中的分布式OSGI消费者服务未启动
我刚刚开始使用动物园管理员在卡拉夫的DOSGi。我在Karaf的一个实例中提供服务,在另一个实例中提供消费者。服务端运行良好。一旦发布,我可以在安装了Zookeeper服务器的Karaf控制台中使用log:display命令查看它,并且我也可以通过浏览器访问wsdl。问题出在消费端。当服务启动时,它应该写一条消息(下面的ref代码),但是它从来没有发生。消费者代码: 和component.xml: