《HPC高性能计算工程师》专题
-
Java如何计算时差
问题内容: 如果用户输入为2255,而我的输出应为10分钟,那么我如何计算24小时内的时差。我的想法是将输入分为2个部分,2位数字和2位数字。前2位数字是小时,将其乘以60使其变为分钟。然后再加上第二个2位数字,然后计算出差异。我不想使用任何日期日历数据类型或API来解决它。谢谢 问题答案: 如何在不使用String chartAt的情况下获取前两位数字。 最高两位数:数字/ 100最低两位数:数
-
JS函数计算补色?
问题内容: 有人知道吗,您很想知道一种用于计算十六进制值的互补色的Javascript解决方案? 网络上有许多颜色选择套件和调色板生成器,但是我还没有看到使用JS实时计算颜色的工具。 详细的提示或摘要将不胜感激。 问题答案:
-
计算golang中的行数
问题内容: 我想使用Go显示数据库中的行数。如何显示行数? 问题答案: 查询将在变量计数中返回一行。因此,下一个要做的就是读取该行,并使用函数将结果分配到新变量中。这就是它的工作方式。 最好的选择是使用,因为您希望只读取一行。代码将是。
-
Python,计算列表差异
问题内容: 在Python中,计算两个列表之间的差异的最佳方法是什么? 例 问题答案: 如果顺序无关紧要,则可以简单地计算出设定差:
-
如何计算JSON对象
问题内容: 这是我的JSON: 如何计算其中的对象数量? 问题答案: 那是一个数组。 您可以解析它(),然后使用该属性。
-
 android studio实现计算器
android studio实现计算器本文向大家介绍android studio实现计算器,包括了android studio实现计算器的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了android studio实现计算器的具体代码,供大家参考,具体内容如下 效果图: 资源文件: color.xml white.xml 设置input text的填充色为白色 selector.xml 点击按钮时产生阴影效果 equeal
-
使用Python计算N克
问题内容: 我需要为包含以下文本的文本文件计算Unigram,BiGrams和Trigrams: “囊性纤维化仅在美国就影响了30,000名儿童和年轻人。吸入盐水雾可以减少填充囊性纤维化患者气道的脓液和感染,尽管副作用包括令人讨厌的咳嗽症状和难闻的味道。这就是结论。发表在本周《新英格兰医学杂志》上的两项研究。 我从Python开始,并使用以下代码: http://www.daniweb.com/s
-
计算DISTINCT值的出现
问题内容: 我正在尝试找到一个MySQL查询,该查询将在特定字段中找到DISTINCT值,计算该值的出现次数,然后按计数顺序对结果进行排序。 示例数据库 预期结果 问题答案:
-
SpringSecurity/OAuth如何计算AuthenticationPrincipal
我有一个Spring项目,它使用sping-oaust2和sping-Security使用LDAP身份验证提供程序进行身份验证。 在控制器中,我可以使用< code > @ AuthenticationPrincipal 注释访问当前主体的< code>UserDetails。 然而,当我使用client_credential令牌到达endpoint时,是一个,它是OAuth客户端id。sprin
-
如何计算glFrustum参数?
我有这个代码: 我必须用glFrustum替换glOrtho函数并得到相同的结果。 我阅读了khronos上的opengl指南,理解了glOrtho和glFrustum之间的区别,但我不知道如何计算参数。 如何计算传递给glFrustum函数的参数?
-
PHPEXCEL公式计算问题
这个问题开始于一个非常复杂的工作表,但我把它简化为一个非常简单但仍然有同样的问题。 PHPExcel不是在计算公式,但是如果我改成一个简单的(code=b3/code>)它就能工作。 getvalue()返回的公式为 我的密码。 我在B3单元格处设置值8,在excel中这样做会在B8处计算相同的值。 C8有个'n'。 但是在phpexcel中,我总是得到它保存的值(2.1) 响应:2.1 在exc
-
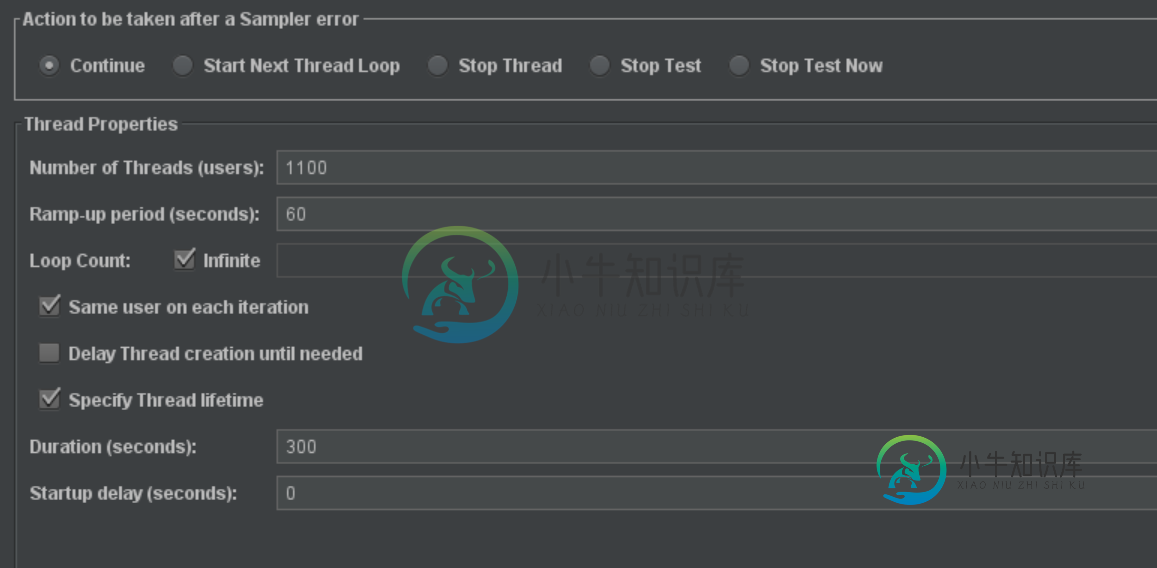 Jmeter-计算上升周期
Jmeter-计算上升周期我在配置中错过了什么? “无限”复选框需要勾选还是不勾选?
-
Java剩余天数计算
我已经实现了下面的代码来计算剩余的天数。我已经使用SimpleDateFormat将字符串转换为日期。如果输入10/02/1993(今天的日期)作为日期,则输出显示还剩0天。但如果我选择11/02/1993,它显示的输出与0天相同。但如果我改变月份,即1993年2月22日7月2日,它显示的是剩下160天,而不是原来的162天,这是原来的结果。我在这里做错了什么?非常感谢任何帮助。 更新:我已经更新
-
使用C计算行数
问题内容: 有没有一种方法可以使用C计算文件中的行数? 问题答案: 如果要以编程方式执行此操作,请以文本模式打开文件并执行fgetc()操作,直到到达文件末尾。记下调用fgetc的次数。
-
计算机网络 - 目录
概述 物理层 链路层 网络层 传输层 应用层 参考链接 计算机网络, 谢希仁 JamesF.Kurose, KeithW.Ross, 库罗斯, 等. 计算机网络: 自顶向下方法 [M]. 机械工业出版社, 2014. W.RichardStevens. TCP/IP 详解. 卷 1, 协议 [M]. 机械工业出版社, 2006. Active vs Passive FTP Mode: Which