《HPC高性能计算工程师》专题
-
 华为云计算一面
华为云计算一面算法:给一个数组,一个target,打印出所有的数组元素组合使其和恰好为target,不允许有重复 聊实习 内存与CPU问题如何排查处理 HashSet线程安全吗,原理
-
 北森云计算一面
北森云计算一面后端开发实习生 问的以下问题正常吗(本人的确准备得不太充分) - 数组和链表的区别 - HashMap的底层实现 - 为什么哈希冲突的链表操作从头插 → 尾插 - 前台线程和后台线程有什么区别 - 线程池开辟的是后台线程还是前台线程 - java 有哪些实现并发的方法 - mysql 索引有哪些层级 - mysql 最左匹配原则 - java 垃圾回收算法
-
算法题 - 一致性哈希算法
一致性哈希算法 tencent2012笔试题附加题 问题描述: 例如手机朋友网有n个服务器,为了方便用户的访问会在服务器上缓存数据,因此用户每次访问的时候最好能保持同一台服务器。 已有的做法是根据ServerIPIndex[QQNUM%n]得到请求的服务器,这种方法很方便将用户分到不同的服务器上去。但是如果一台服务器死掉了,那么n就变为了n-1,那么ServerIPIndex[QQNUM%n]与S
-
JavaScript高级程序设计(第三版)学习笔记1~5章
本文向大家介绍JavaScript高级程序设计(第三版)学习笔记1~5章,包括了JavaScript高级程序设计(第三版)学习笔记1~5章的使用技巧和注意事项,需要的朋友参考一下 第2章,在html中使用JavaScript Html引入外部js脚本 <script>标签有一个defer属性可以延迟脚本执行,但是并不保证会按脚本排列顺序执行 建议:将脚本引入放在<body>标签的所有内容之后,而不
-
JavaScript高级程序设计(第三版)学习笔记6、7章
本文向大家介绍JavaScript高级程序设计(第三版)学习笔记6、7章,包括了JavaScript高级程序设计(第三版)学习笔记6、7章的使用技巧和注意事项,需要的朋友参考一下 第6章,面向对象的程序设计 对象: 1、数据属性 configurable,表示能否通过delete删除属性从而重新定义属性,能否修改属性的特性,或能否把属性修改为访问器属性,默认为true enumerbale,表示
-
 美亚柏科信息 交互设计工程师 面试分享
美亚柏科信息 交互设计工程师 面试分享首先,面试官会让你做个自我介绍; 然后,我对自己所在院校和目前的研究方向,所学专业进行总体说明; 接着,面试官会问你在学校期间是否做过什么项目; 继而,我回答在校期间所参加工的项目和负责的项目内容。 面试官问的面试题: 1、自我介绍,哪里人,哪个学校的?专业是啥? 2、你期望的岗位和你在校期间的所做项目有没有联系? 3、项目有几个人合作,你们分工如何?成果如何? 4、对我们公司有什么了解? 5、对
-
RDSEED和RDRAND之间的性能差异可以忽略不计
最近的Intel芯片(Ivy Bridge及以上)有生成(伪)随机位的指令<代码>RDSEED输出从芯片上传感器收集的熵生成的“真实”随机位输出由真随机数生成器播种的伪随机数生成器生成的位。根据英特尔的文档,RDSEED速度较慢,因为收集熵的成本很高。因此,RDRAND作为一种更便宜的替代方案提供,其输出对于大多数加密应用程序来说是足够安全的。(这类似于Unix系统上的开发/随机(dev/rand
-
阶乘中的位数计数-输入/输出性能问题
我正在spoj平台上解决任务-计算阶乘中的位数。我找到了Kamenetsky公式并实现了它: 首先,我使用了注释代码(流),因为我认为它比实际代码(没有注释)慢,所以我做了更改,但仍然超过了时间限制。我怎样才能更快? 示例输入为(第一行是测试数): 和预期产出:
-
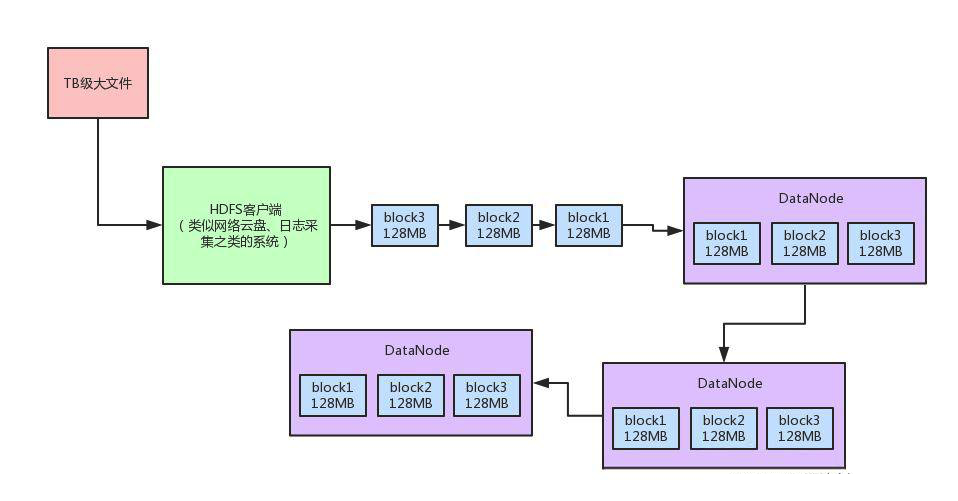 关于超大数据量的系统性能优化设计
关于超大数据量的系统性能优化设计主要内容:1、Chunk缓冲机制,2、Packet数据包机制,3、内存队列异步发送机制,总结:这篇文章,我们来聊一聊在十亿级的大数据量技术挑战下,世界上最优秀的大数据系统之一的Hadoop是如何将系统性能提升数十倍的? 首先一起来画个图,回顾一下Hadoop HDFS中的超大数据文件上传的原理。 其实说出来也很简单,比如有个十亿数据量级的超大数据文件,可能都达到TB级了,此时这个文件实在是太大了。 此时,HDFS客户端会给拆成很多block,一个block就128MB。 这个HDFS客户端
-
线程、进程、协程(面试高频)
需要先对 IO 的概念有一定的认识: IO在计算机中指Input/Output,也就是输入和输出。 并发:在操作系统中,某一时间段,几个程序在同一个CPU上运行,但在任意一个时间点上,只有一个程序在CPU上运行。 当有多个线程时,如果系统只有一个CPU,那么CPU不可能真正同时进行多个线程,CPU的运行时间会被划分成若干个时间段,每个时间段分配给各个线程去执行,一个时间段里某个线程运行时,其他线程
-
 百度提前批算法工程师一,二,主管面面经
百度提前批算法工程师一,二,主管面面经一面 1. 挖简历 2. python部分: list和tuple的区别 python的深浅拷贝使用场景,以及python为什么默认使用浅拷贝(不会) 3. 算法部分: CNN的pooling部分是怎么进行反向传播的:meanpooling将梯度值平均传播给上一层,maxpooling则在前向传播的时候记下max值的位置,反向的时候将梯度值传播到该位置,其他位置为0 如何缓解梯度消失 4. 手撕代
-
 科大讯飞 讯飞研究院 AI算法工程师 凉经
科大讯飞 讯飞研究院 AI算法工程师 凉经[toc] 科大讯飞 AI研究算法工程师-自然语言处理方向 提前批 简历投递 2022.06.27 投递时间:2022.06.27 一面 2022.06.30 简历还是蛮快的,没有笔试,直接邮件通知的一面 面试时间:1个小时 面试内容: 项目,三个项目都问到了,大概项目问了45分钟左右 基础知识 10分钟左右 SVM 多目标检测和位姿估计领域的研究现状 YOLO系列的区别、优缺点 反问 公司主要研
-
 万集科技(提前批)-- 算法工程师(苏州研究院)
万集科技(提前批)-- 算法工程师(苏州研究院)7.13 一面 专业问答环节 自我介绍 项目1介绍 数据标注中遇到的问题 团队分工以及具体职责 模型推理速度 基线的选择 训练设备以及部署设备 算法性能提升情况 项目2介绍 项目3介绍 聊天环节 薪资考虑 工作地考虑 读研期间工作时间安排 7.19 HR面 自我介绍 家庭情况 为什么选择XX大学 读研期间科研的整个过程 对象问题 职业规划 为什么选择苏州 为什么选择我们,不考虑一些大厂吗 对未来工
-
 秋招日寄——快手机器学习算法工程师-一面
秋招日寄——快手机器学习算法工程师-一面惯例:自我介绍+讲项目 考察问题: 介绍下transformer(语言组织不好,虽然知道原理但是讲的很乱) 为什么需要multi head attention 介绍下layernorm和batchnorm 为什么layernorm在NLP下有效,batchnorm则不是? pytorch的model.train()和model.eval()的区别 介绍一下集成学习 算法题:二维网格求左上到右下的最
-
 小红书:2022秋招提前批【RedStar】算法工程师 一面
小红书:2022秋招提前批【RedStar】算法工程师 一面小红书:2022秋招提前批【RedStar】算法工程师 一面 GNN 中 Transductive 和 Inductive 分别是什么 Transductive 考虑的是静态的图结构,如 GCN、GAT 等经典模型都是 Transductive GNN,基于静态的图结构学习节点表示进行节点分类等下游任务; Inductive 考虑的是动态的图结构,经典模型如 GraphSAGE 则是在基本的学