《无人车规划算法实习》专题
-
 腾讯-青云计划- AI Lab-算法岗
腾讯-青云计划- AI Lab-算法岗记录下一面: 强化学习相关, 主要从在投的论文入手,问了如何实现的 之后问了项目,ppo,pg方法,rlhf等 transformer和lstm区别以及应用场景 问了下目前的实习 手撕: 岛屿问题 子数组求和
-
秘密圣诞老人计划
我们被要求创建一个程序,可以用于游戏"秘密圣诞老人": 这是我开发的程序。到目前为止,如果我输入3个人(例如Bob、Ben、Bill),它将返回“Ben为Bill购买”,而没有人为Ben或Bob购买。我目前正试图让它输出“Bob为Ben买东西,Ben为Bill买东西,Bill为Bob买东西”,但到目前为止还没有成功。如果有人能给我一个提示/设置这个的基础,我将不胜感激。另外,如果我的代码中有任何错
-
算法规范-数据结构介绍
本文向大家介绍算法规范-数据结构介绍,包括了算法规范-数据结构介绍的使用技巧和注意事项,需要的朋友参考一下 算法定义为一组有限的指令,如果遵循这些指令,它们将执行特定的任务。所有算法必须满足以下条件 输入。一种算法具有零个或多个输入,这些输入是从一组指定的对象中获取或收集的。 输出。一种算法具有一个或多个与输入具有特定关系的输出。 确定性。必须明确定义每个步骤;每条指令必须清晰明确。 有限。该算法
-
 极氪规控 小米控制算法
极氪规控 小米控制算法极氪:面试官做规划的都聊的规划,项目 为什么用frenet坐标系,lattice planner的cost有什么,单例模式,面向对象,怎么debug,用什么工具分析数据,一道dp 小米:面试官做控制的,项目,mpc怎么提高速度(面试官说了一个热启动,查了一下是用上一时刻的最优值当下一时刻的初始值加速收敛,apollo的lqr为什么需要前馈,pid的i为什么能减小稳态误差,定位信息不准控制算法能做什
-
 javascript - 百度地图js API 3.0 如何获取多个驾车行驶路线规划?
javascript - 百度地图js API 3.0 如何获取多个驾车行驶路线规划?我需要获取起点坐标和终点坐标之间的多个线路规划,也就是期望是获取多个坐标数组。作为自定义路线轨迹绘制的依据数据 通过以下代码,随便选择北京三环区域左右内的两个坐标进行测试,始终只获取了一个线路规划,也就是plan.getNumRoutes()获取的数值都是1, //测试终点和起点的两点坐标截图 debug截图 我是不是测试坐标选的有问题导致获取的只有一个线路,还是onSearchComplete里
-
 纯jquery实现模仿淘宝购物车结算
纯jquery实现模仿淘宝购物车结算本文向大家介绍纯jquery实现模仿淘宝购物车结算,包括了纯jquery实现模仿淘宝购物车结算的使用技巧和注意事项,需要的朋友参考一下 这篇文章里,将会提到购物车里的所有功能。包括全选、单选金额改变。在增加数量时金额也会相应改变。 效果图展示: 说下大致的思路吧: 1、首先是计算一行的价格。这个功能在上篇博客里有提到,这里就不列举出来了。 2、遍历选中的几行,将每行的数值相加。 3、将值赋给总金额
-
 车300java实习面试
车300java实习面试#后端Java##面试# 1.自我介绍 2.介绍一下自己的项目和在项目中负责哪些模块 3.在项目中怎么判断用户是否登录 4.项目怎么实现统一的鉴权 5.假如在项目中加一个管理员,怎么实现将普通用户踢出会话 6.对面向对象特性的理解,在项目中哪些体现了 7.AOP的使用场景有哪些 8.怎么实现异步通信,不使用中间件 9.怎么处理异常,将异常信息以json抛出 10.怎么在项目中获得用户的ID
-
ReactorKafka制作人-无法重试
我已经使用reactor-kafka(kafka的一个功能性Java API)创建了一个KafkaProducer(reactor.kafka.sender.KafkaSender)。使用以下生产者配置, 当我试图发布一个记录到一个无效的主题我得到超时异常 正如所料。但我已经为没有发生的重试进行了配置。我假设在/已过期,每次直到或
-
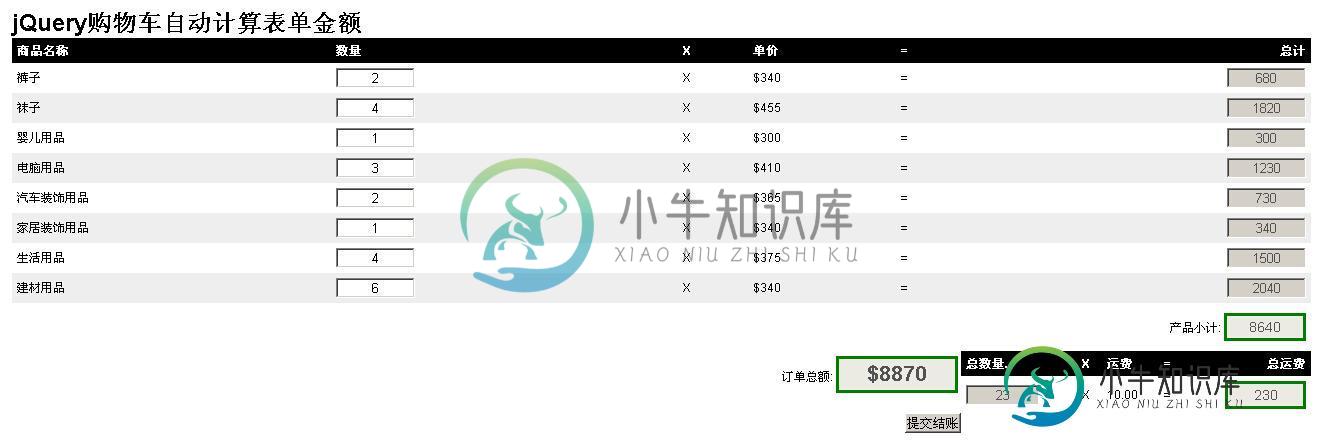 jQuery实现购物车表单自动结算效果实例
jQuery实现购物车表单自动结算效果实例本文向大家介绍jQuery实现购物车表单自动结算效果实例,包括了jQuery实现购物车表单自动结算效果实例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了jQuery实现购物车表单自动结算效果。分享给大家供大家参考。具体如下: 这里jQuery实现购物车表单自动结算,只要用户把所购商品的数量输入进去,就可以适时计算出商品总额,金额+运费,类似淘宝的购物车结算功能,计算过程是适时的,用jqu
-
 B站 算法实习生(推荐算法)面经
B站 算法实习生(推荐算法)面经一面: 自我介绍; 面试官粗略地看了一下项目说:“你这个简历好像更适合NLP组啊,跟我们组的业务好像关系不是很大,感觉不是很合适啊。” 一阵简短的沉默; 我:“。。。。。。我也投了NLP算法组,但是被推荐算法组先捞上来了,您看要不跟HR反馈一下让她把简历转过去?“ 面试官:”那倒不用,我们先面着吧。” 面试问题分界线 ----------------------------------------
-
SMO算法实现?
本文向大家介绍SMO算法实现?相关面试题,主要包含被问及SMO算法实现?时的应答技巧和注意事项,需要的朋友参考一下 选择原凸二次规划的两个变量,其他变量保持不变,根据这两个变量构建一个新的二次规划问题,这样将原问题划分为更小的子问题可以大大加快计算速度,而选择变量的方式是: 其中一个是严重违反KKT条件的一个变量 另一个变量是根据自由约束确定的
-
硬算法实现
我无法实现SJF(最短作业优先)算法。 SJF就是这样工作的 如果进程到达0时间,它将工作到下一个进程到达,算法必须检查到达1的到达(进程/进程)是否比当前剩余时间短 示例:P0执行了1,还有2要完成,现在我们有P0,P1,P2,P3,P4 in 1算法将执行最短的一个P3,之后是P0,然后是P4,然后是P1,依此类推。问题是我必须保存所有进程的开始和结束时间执行,以及等待时间。 这是我的最新算法
-
算法和实现
朴素贝叶斯算法 给定数据集$$T={(x{(1)},y{(1)}),(x{(2)},y{(2)}),...,(x{(m)},y{(m)})}$$,其中$$x\in \mathcal{X}\subseteq R^n$$,$$y\in \mathcal{Y}={c_1, c_2,...,c_K}$$,$$X$$是定义在输入空间$$\mathcal{X}$$上的随机向量,$$Y$$是定义在输出空间$$\
-
算法python实现
线性回归python实现 1.算法python代码 包含Normal Equations,批量梯度下降和随机梯度下降,这里的代码跟Logistic回归的代码类似 # -*- coding: utf-8 -*- import matplotlib.pyplot as plt import numpy as np class LinearRegression(object): def _
-
算法python实现
Logistic回归python实现 1.算法python代码 # -*- coding: utf-8 -*- import matplotlib.pyplot as plt import numpy as np class Logistic(object): def __init__(self): self._history_w = [] self.