《无人车规划算法实习》专题
-
 【实习】字节-算法-CMPT
【实习】字节-算法-CMPT上一周字节hr突然打电话捞人面试,没仔细问什么岗位然后就开始面了,最后反问才知道是广告,做cv的cv的简历一下被挂,只有面些其他岗位。 1.自我介绍 2.项目背景,最终是否落地? 3.项目过程当中做的比较好的有哪些? 4.inpainting模型的原理,如何用的mask实现 5.图像擦除如何实现,对商品图擦除 6.图像当中比较常见的损失函数,分类,cross entropy,triplet los
-
Android-无法隐藏'TextInputLayout`/'TextInputItemText'下划线
我目前试图隐藏的下划线的当它被禁用。以下是当前实现的外观。我想要同样的样子,但不要下划线。以下是当前的XML: 自定义样式: 到目前为止,我所尝试的: 将的主题设置为自定义样式 重写背景的和/或是一个纯色绘图 大多数在线解决方案建议使用自定义样式和设置颜色控制正常,但这似乎对我来说并不管用。提前感谢
-
 理想汽车-算法优化工程师一面
理想汽车-算法优化工程师一面10-8 面试官懂的太多了,秋招以来第一次面试被问麻了。 手撕 简单dp题,到右下角的最短路径 面试官说可以把边界条件拿出来做,这样会更清晰点 Pytorch DDP了解过吗 不了解 CV的发展路径 从AlexNet开始说,因为想不起来具体改进,就总结了说是各种架构和激活函数的改进 NLP的发展路径 RNN-》LSTM-》Transformer 不清楚是不是这个发展 RNN和Transformer
-
 滴滴打车 秋储算法工程师一面
滴滴打车 秋储算法工程师一面面试官很帅人很nice,但是本人巨菜估计已凉 大概持续30min 让我自己讲一个项目,扯了一个运筹相关的毕设(特别坑,自己都没完全整明白),面试官不是做运筹的,但是也讨论了下三要素(目标、变量、约束),感觉他没听太懂目标... 然后就问了机器学习的项目,我选的课程项目比较水,一些简单问题有准备但背的不熟,后来被面试官发现在念稿,要求视线注视屏幕就开始口齿不清,一定要自己多读多背八股!! 一些基础问
-
 无关规则破坏ANTLR4文法
无关规则破坏ANTLR4文法我正在构建一个ANTLR4语法来解析数据源中的字符串--类似于StringTemplate(如果不是非常相似的话),只是我不喜欢这种语法,所以我正在编写自己的语法(也只是为了好玩和学习,因为这是我第一次使用/ANTLR)。我的语法现在看起来像这样(这是从我的实际情况中简化出来的,但我已经验证了它是一个“好例子”,并且展示了我所问的相同的问题): 这个语法工作得很好,允许我执行替换,例如: 结果是:
-
 歌尔精英计划 图像算法一面
歌尔精英计划 图像算法一面感觉一面像hr面一样,hr和面试官一起进 会议,时长大概30min。 1.自我介绍 2.项目介绍,论文的创新点是什么 3.实习过程当中自己的优势是什么 4.做得不好的方面有哪些 5.遇到困难如何解决 6.职业规划,如何考虑 7.觉得自己是不是刨根问底的人,以及会更加注重深度还是做更多的项目 8.认为实习的时候团队对自己的评价如何 9.最后反问
-
关联规则挖掘算法apriori原理?
本文向大家介绍关联规则挖掘算法apriori原理?相关面试题,主要包含被问及关联规则挖掘算法apriori原理?时的应答技巧和注意事项,需要的朋友参考一下 一个频繁项集的子集也是频繁项集,针对数据得出每个产品的支持数列表,过滤支持数小于预设值的项,对剩下的项进行全排列,重新计算支持数,再次过滤,重复至全排列结束,可得到频繁项和对应的支持数。 作者:@小黑 以下是自己的理解,如果有不对的地方希望各位
-
 一种硬币交换变量的动态规划解法
一种硬币交换变量的动态规划解法我正在练习动态规划。我的重点是硬币交换问题的以下变体: 让成为一组整数面值的常量。设为可通过中的硬币获得的正整数金额。考虑两个人<代码> A<代码>代码> B<代码>。我可以用多少种不同的方式将分为和,这样每个人都可以得到相同数量的硬币(不考虑每个人得到的实际金额)? 实例 每个人可以分成4种不同的方式: 人得到{2,2},人得到{1,1}。 人得到{2,1},人得到{2,1}。 人得到{1,1}
-
算法题:名人问题,给出最优解法
本文向大家介绍算法题:名人问题,给出最优解法相关面试题,主要包含被问及算法题:名人问题,给出最优解法时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 问题描述: 有n个人他们之间认识与否用邻接矩阵表示(1表示认识,0表示不认识),并A认识B并不意味着B认识A,也就意味着是个有向图。如果一个人是名人,他必须满足两个条件,一个是他不认识任何人,另一个是所有人必须都认识他。 解决问题: 用一个数组
-
实时划分
问题内容: 我正在尝试用Java编写一个小程序,将华氏温度转换为摄氏温度。它涉及减去32并乘以5/9。所以我做到了。 但是由于某种原因5/9返回零,这甚至毁了一切 返回零,我不知道为什么。我发现自己可以做到的唯一方法是声明所有内容并逐步进行。 谁能告诉我为什么发生这种情况,我认为至少将其声明为double会返回值。如果有人知道,那就可以解决。 问题答案: 默认情况下,Java中的数字是。因此,当您
-
Kie-Maven-Plugin无法工作,无法编译规则工件
我正在使用drools Version6.0.0.Final做一个示例hello world maven项目。下面是我的pom文件的构建,我已经指定了kie-maven-plugin,但是我可以注意到这个插件不能被执行。我是不是漏掉了什么。
-
第五章 动态规划 - 5.10 本章习题
本章动态规划的习题 1.子序列个数 子序列的定义:对于一个序列a=a[1],a[2],……a[n],则非空序列a’=a[p1],a[p2]……a[pm]为a的一个子序列 其中1<=p1<p2<…..<pm<=n。 例如:4,14,2,3和14,1,2,3都为4,13,14,1,2,3的子序列。 对于给出序列a,有些子序列可能是相同的,这里只算做1个。 要求输出a的不同子序列的数量。 2.数塔取数问
-
强化学习(实践):多臂老虎机,动态规划,时序差分
在多臂老虎机(Multi-Armed Bandit,MAB)问题中,有一个拥有 K 根拉杆的老虎机,每一个拉杆都对应一个关于奖励的概率分布 R。我们每次拉下其中一根拉杆,就可以获得一个从该拉杆对应的奖励概率分布中获得一个奖励 r。我们的目标是: 在各个拉杆奖励的概率分布未知的情况下,从头开始尝试,并在操作 T 次拉杆后,获得尽可能多的累积奖励。由于奖励的分布是未知的,我们就需要在“探索拉杆的获奖概率”和“根据经验选择获奖最多的拉杆”中进行权衡。
-
使用Getters和Setters问题的汽车计划
对于这个程序,实例变量的创建和模型需要是一个字符串,价格需要是我已经有的两倍,但不确定如何处理需要是int类型的年份,大于1900。然后我需要用参数做一个构造函数,我也做了,但是toString需要用setter和getters方法返回Car对象的字符串表示。所以我在试图为setter想出一些东西时遇到了问题,如果我做对了这一部分。 这部分是Cartest驱动程序,我不确定我这样做是否正确。我必须
-
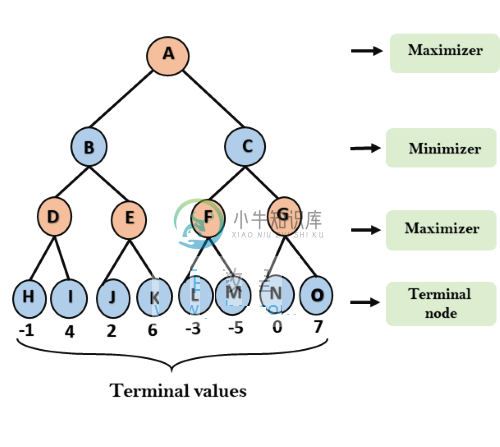 人工智能的最小最大算法
人工智能的最小最大算法主要内容:Min-Max算法的工作人工智能中的最小最大算法: Mini-max算法是一种递归或回溯算法,用于决策和博弈论。它为玩家提供了一个最佳的动作,假设对手也在玩最佳状态。 Mini-Max算法使用递归来搜索游戏树。 Min-Max算法主要用于AI中的游戏。如Chess,Checkers,tic-tac-toe,go和各种拖车玩家游戏。该算法计算当前状态的最小极大决策。 在该算法中,两个玩家玩游戏,一个叫做MAX,另一个叫做M