
无关规则破坏ANTLR4文法

我正在构建一个ANTLR4语法来解析数据源中的字符串--类似于StringTemplate(如果不是非常相似的话),只是我不喜欢这种语法,所以我正在编写自己的语法(也只是为了好玩和学习,因为这是我第一次使用/ANTLR)。我的语法现在看起来像这样(这是从我的实际情况中简化出来的,但我已经验证了它是一个“好例子”,并且展示了我所问的相同的问题):
grammar Combined1;
file:
.*? (repToken .*?)+
| .*?
;
foreach: '@foreach' WS* '(' WS* repvar WS* ')' WS* '{' content=file '}' ;
with: '@with' WS* '(' WS* repvar WS* ')' WS* '{' content=file '}' ;
// withx: '@withx' WS* '(' WS* repvar WS* ')' WS* '{' content=file '}' ;
repvar: '@' (
'$'
| '(' nestedIdentifier ')'
| nestedIdentifier
) ;
repToken:
foreach
| with
// | withx
| repvar
;
nestedIdentifier: Identifier ('.' Identifier)* ;
Identifier: [A-Za-z_] [A-Za-z0-9_]* ;
WS: [ \t\r\n] ;
Other: ( . ) ;
这个语法工作得很好,允许我执行替换,例如:
string template = "Test: @foreach(@list){@$}";
Process(template, new { list = new [] { "A", "B", "C" } });
结果是:
Test: ABC
-
null
我完全不明白为什么添加一个与我的输入无关的解析器规则会导致解析器失败。救命啊!?
编辑3/17/2014:JavaMan在每个场景中都要求一个解析树来澄清上面的描述。我不知道如何生成他所做的html" target="_blank">解析树图形,但以下是Visual Studio调试器的两张截图,说明了两者的区别······请注意,在这些图像中,我使用了更长的名称--特别地,ReplacementTokenContext用于RepToken。
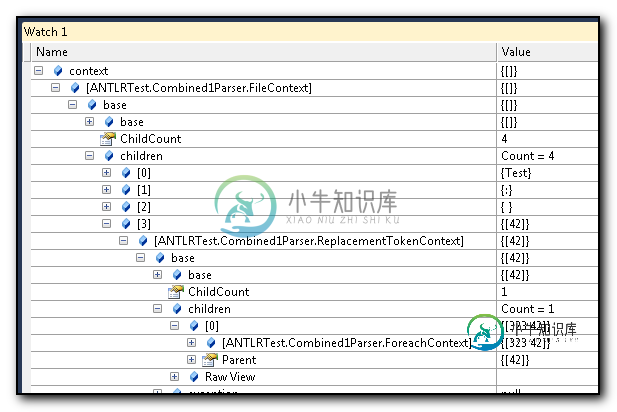
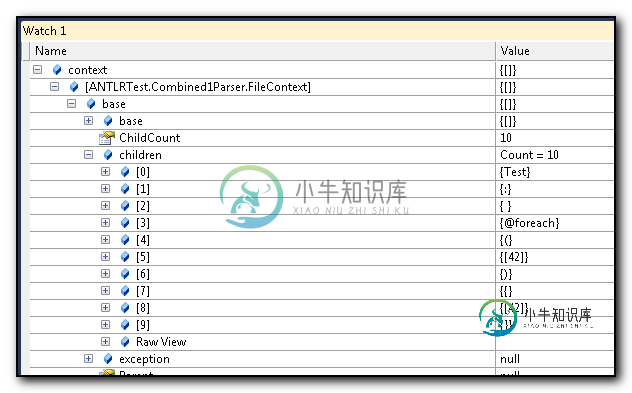
共有1个答案

在我看来,这是一个正确的解析。这是你想要的吗?会不会是你的访客代码有问题?您得到了相同的解析树吗?如果您能在这里发布解析树,那就更好了。
顺便问一下,将所有空白空间发送到隐藏通道并从解析器规则中删除所有WS令牌怎么样?
编辑:
java org.antlr.v4.runtime.misc.TestRig Combine1 file -tree in.cpp > treeres.txt
(file string template = " Test : (repToken (foreach @foreach ( (repvar @ (nestedIdentifier list)) ) { (file (repToken (repvar @ $))) })) " ; \r \n Process ( template , new { list = new [ ] { " A " , " B " , " C " } } ) ;)
-
我正在为用ANTLR4编写的Decaf编程语言创建解析器和lexer规则。我试图解析一个测试文件,但不断地得到一个错误,一定是语法有问题,但我无法理解。 我的测试文件如下所示: 错误是:第2行:8不匹配的输入“10”应为INT_LITERAL 下面是完整的decaf.g4语法文件
-
我的语法允许以下操作: 我从其他语法中抓了几个东西来玩。我的主要问题是我的expr规则。给定以下输入:,我期望解析树会找到..规则,但它将解释0。并不正确解析其余部分。 如果在我的0后面加上一个空格,就可以了: 谢了!
-
null null 以下是我的(不完整和不成功的)尝试: 如果不能在lexer中解决这个问题,我可以使用标记、、、、、和自行编写解析器规则。
-
我刚刚开始学习ANTLR4 lexer规则。我的目标是为Java属性文件创建一个简单的语法。以下是我目前掌握的信息:
-
运行命令时,出现错误 运行上述命令时会创建以下文件:- 运行grun工具:我尝试了不同的解析器规则,但得到了相同的错误。