《优化》专题
-
索引优先级队列的混乱
我已经有了优先级队列的概念,但是当涉及到索引优先级队列时,我对change(int k,Item Item)和delete(int I)等方法的实现有点困惑。 change(int k,Item Item)是将k关联的项目改为Item delete(int i)是删除k及其关联项
-
Cassandra 中的一致性级别调优
想象一个电子商务应用程序: 假设我有三个并且我的一致性级别(CL)很弱:即 我有一个产品表,例如 这是跨三个节点同步的初始数据 > 现在,客户端A从N1读取信息,客户端B从N2读取信息 客户端1看到1台计算机可用 客户端 2 看到 1 台计算机可用 他们现在都去购买客户A先下订单。所以N1,表格如下所示: 现在客户端 2 下订单,因此在 N2 处,表将如下所示: 但实际上客户2的订单不应该被处理。
-
有向图的深度优先遍历
我有一个任务,我必须写一个方法,执行有向图的DFT。以下是有向边: 节点2-->节点4 节点3-->节点5 节点4-->节点5
-
使用RabbitMQ DLX队列的优先级
我有2个RabbitMQ队列: = 正如您对其名称所设想的那样,队列使用死信交换功能,这意味着当消息过期时,它将被重新调用到我的。 我试图实现的是在每次处理失败并将消息推送到DLX队列时增加消息的。 问题是,即使消息过期,当它不在队列的底部(头部)时,它也不会请求我的。因此,如果DLX队列中有到期时间为7天的消息,并且我们将到期时间为5秒的新消息加入队列,则该消息将仅在7天5秒后请求到。... 我
-
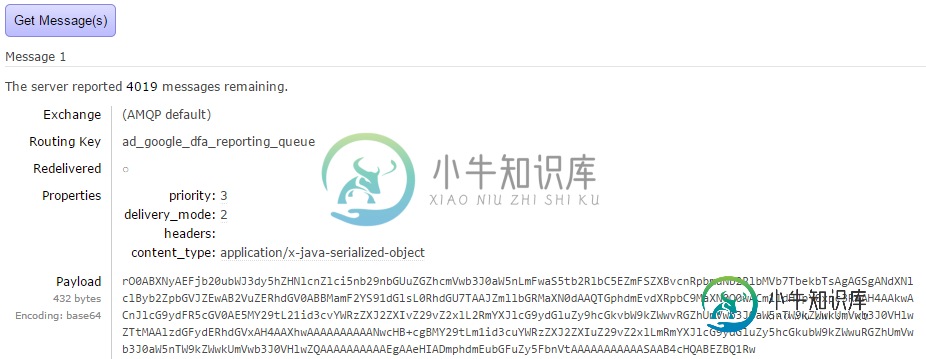 Spring AMQP RabbitMQ实现优先级队列
Spring AMQP RabbitMQ实现优先级队列在谷歌搜索了几天之后,我相信我完全迷路了。我想实现一种优先级队列,它大约有3个队列: 高优先级队列(每日),需要先处理 中等优先级队列(每周),如果队列#1中没有项目,将进行处理。(此队列中的ok消息根本不处理) 低优先级队列(每月),如果队列#1中没有项目,将进行处理 最初,我有以下流程,让消费者使用所有三个队列中的消息,并检查队列#1、#2和#3中是否有任何项目。然后我意识到这是错误的,因为:
-
最优子结构与贪婪选择
我在读关于贪婪问题的两个属性,我试图理解以下两者之间的区别 最优子结构性质:最优全局解包含其所有子问题的最优解 贪婪选择性质:通过贪婪地选择局部最优选择,可以获得全局最优解 两者不是等价的吗?这两者似乎是一回事;能不能举个例子,最优子结构满足,贪婪选择不满足?以及一个贪婪选择得到满足而最优子结构没有得到满足的例子?
-
Spring Bean容器中的优先顺序
所以我的问题是: 总是设置优先级的setter注入,还是有某个属性定义它。 为什么Setter注入优先于构造函数注入
-
在优步登登上注册活动
我正在做一个使用优步Cadence Java客户端的项目。如何从代码中获取注册活动的列表? 谢谢你。
-
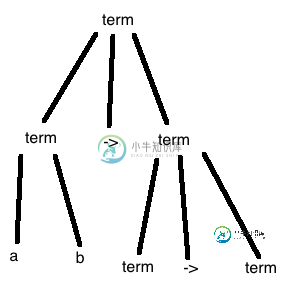 ANTLR4文法中的优先级问题
ANTLR4文法中的优先级问题我在这里开发了一个小语法,我有一个问题: 为什么解析器没有在解析树的顶部看到(->)规则?这是优先级问题吗?
-
极大极小算法的优缺点
极小极大算法的一个缺点是每个板状态必须被访问两次:一次查找其子级,第二次评估启发式值。 极小极大算法还有其他缺点或优点吗?对于像象棋这样的游戏,还有更好的选择吗?(当然是带有α-β修剪的极小极大算法,但还有其他吗?)
-
Maven多模块优于简单依赖
我有一些年的maven项目的经验,即使是多模块项目(这让我讨厌maven的多模块特性(所以免责声明现在已经完成了)),即使我真的喜欢maven,我也无法得到一个明确的答案: 多模块maven项目的典型用途是什么?与简单的依赖关系和父pom相比,这样的结构有什么附加值? 我已经看到了很多多模块项目的配置,但是所有这些都可以通过创建一个简单的依赖库结构来解决,这些依赖库作为交付品(即使有一个父pom,
-
如何结合localStorage和sessionStorage的优点
我希望在浏览器选项卡之间共享身份验证令牌,建议使用HTML5。但是,我不希望在浏览器关闭时,与身份验证相关的任何内容都留在我的存储中,这建议使用HTML5。 与本主题相关的参考资料1(点击): 其他网站是如何解决这个看似简单的问题的。
-
jOOQ、Pojos和数据库优先设计
我正在创建一个应用程序,对jOOQ的当前状态有点困惑。这是我第一次使用jOOQ处理所有东西,包括CRUD,所以我可能会遗漏一些东西。 我知道DAO和POJO可能会被弃用,但是,我不知道如何在数据库优先的设计中处理这个问题。 我能做的最简单的事情就是创建我自己的Pojos,但是我们又回到了通常的JPA实体文件,如果数据库发生了变化,这些文件将无法正确地与记录映射。 1)弃用生成pojos是否意味着我
-
弹性搜索-优先排序索引
假设我有三个指数:城市、博物馆和景点。 现在我正在查询一个术语的所有索引(),例如“维也纳” 作为结果,我得到: 维也纳:维也纳艺术博物馆 有没有办法优先考虑指数,这样我就可以得到第一个城市,而不是景点,最后是博物馆,就像这样: 维也纳 维也纳的Riesenrad 维也纳:维也纳艺术博物馆 维也纳:维也纳历史博物馆
-
时间序列的最优Cassandra模式
或者,如果有一个更好的方式或存储事件的时间序列数据。