《优化》专题
-
在优先级队列中,哪个优先,比较器还是可比较的自然顺序?
如果我有一个PriorityQueue,它有一个Comparator,一个element类实现了Comparable类,以及它们的排序冲突,那么队列将如何处理排序?它是抛出异常还是忽略一个排序规则?
-
MySQL Explain计划中“选择经过优化的表”的含义
问题内容: MySQL Explain plan中的含义是什么? 注意:为便于阅读,已编辑输出。 问题答案: 这意味着您执行的查询只不过计算表中的行数而已,该表是MyISAM表。MyISAM表是用单独的行数存储的,因此,执行此查询MySQL根本不需要查看任何表行数据。而是立即返回预先计算的行数。因此,对表的访问被“优化了”,查询速度很快。 在MySQL中的其他存储引擎(例如InnoDB)上不会发生
-
my.ini优化mysql数据库性能的十个参数(推荐)
本文向大家介绍my.ini优化mysql数据库性能的十个参数(推荐),包括了my.ini优化mysql数据库性能的十个参数(推荐)的使用技巧和注意事项,需要的朋友参考一下 今天刚好需要配置mysql 5.5.45,因为数据库量挺大的,所以必须优化,要不mysql真的不快。 (1)、max_connections: 允许的同时客户的数量。增加该值增加 mysqld 要求的文件描述符的数量。这个数字应
-
Hibernate 4字节码增强不适用于脏检查优化
问题内容: 我正在使用Hibernate 4.3.6,并且使用了最新的Maven字节码增强功能来检测所有实体是否具有自我污染意识。 我添加了Maven插件: 而且我看到我的实体得到了增强: 调试时,我正在检查方法: 并且始终返回 false 。 这是因为始终为null,因此在设置任何属性时: 由于为null,将绕过trackChange,因此字节码增强功能将无法解析脏属性,并且将使用默认的深度比较
-
如何启用Hibernate HiLo实体标识符优化器策略
问题内容: 我正在通过类似的东西初始化没有任何XML的Hibernate 我的班级使用的ID如 所用的发电机,这似乎是更换为过时和和什么。它用 并且似乎允许通过配置 但这就是我所能找到的全部。我想我必须设置一些属性“ xxx.yyy.increment_size”或以其他方式将其传递给Hibernate,但是我看不到如何做。 我知道,但似乎被完全忽略了 问题答案: 我想您正在寻找如何为设置属性。
-
是否优化了Hibernate命名的HQL查询(在批注中)?
问题内容: 一位新同事刚刚建议在Hibernate中使用带有注释(即@NamedQuery)的命名HQL查询,而不是将HQL嵌入到我们的XxxxRepository类中。 我想知道的是,使用注释是否可以提供集中查询以外的任何优势? 特别是,是否有一些性能提升,例如因为查询仅在加载类时解析一次,而不是每次执行Repository方法时解析一次? 问题答案: 来自Pro EJB 3(Mike Keit
-
 iOS 9、10 CoreData:无法在路径上加载优化模型
iOS 9、10 CoreData:无法在路径上加载优化模型问题内容: 我创建了CoreData模型的新版本,并将现有版本迁移到该模型。应用程序在iOS 9+上运行时没有任何问题,但是对于iOS 9和10,我收到此错误: 2017-10-22 19:28:37.081 CafeManager [16654:1918728] CoreData:无法在路径’/ Users / dj-glock / Library / Developer / CoreSimul
-
Nginx服务器高性能优化的配置方法小结
本文向大家介绍Nginx服务器高性能优化的配置方法小结,包括了Nginx服务器高性能优化的配置方法小结的使用技巧和注意事项,需要的朋友参考一下 通常来说,一个优化良好的 Nginx Linux 服务器可以达到 500,000 – 600,000 次/秒 的请求处理性能,然而我的 Nginx 服务器可以稳定地达到 904,000 次/秒 的处理性能,并且我以此高负载测试超过 12 小时,服务器工作稳
-
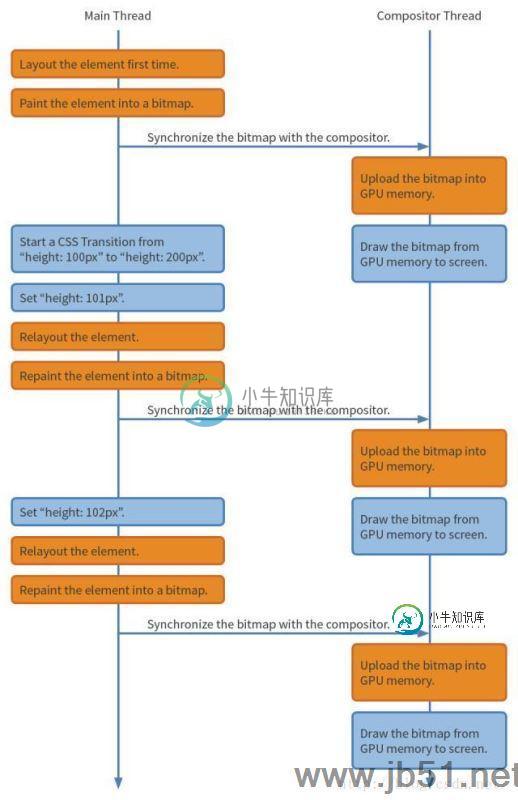 CSS3 动画卡顿性能优化的完美解决方案
CSS3 动画卡顿性能优化的完美解决方案本文向大家介绍CSS3 动画卡顿性能优化的完美解决方案,包括了CSS3 动画卡顿性能优化的完美解决方案的使用技巧和注意事项,需要的朋友参考一下 为什么会卡顿? 有一个前提必须要提,前端开发者们都知道,浏览器是单线程运行的。但是我们要明确以下几个概念:单线程,主线程和合成线程。 虽然说浏览器执行js是单线程执行(注意,是执行,并不是说浏览器只有1个线程,而是运行时,runing),但实际上浏览器的2
-
优化Python代码使其加快作用域内的查找
本文向大家介绍优化Python代码使其加快作用域内的查找,包括了优化Python代码使其加快作用域内的查找的使用技巧和注意事项,需要的朋友参考一下 我将示范微优化(micro optimization)如何提升python代码5%的执行速度。5%!同时也会触怒任何维护你代码的人。 但实际上,这篇文章只是解释一下你偶尔会在标准库或者其他人的代码中碰到的代码。我们先看一个标准库的例子,collecti
-
Mysql查询最近一条记录的sql语句(优化篇)
本文向大家介绍Mysql查询最近一条记录的sql语句(优化篇),包括了Mysql查询最近一条记录的sql语句(优化篇)的使用技巧和注意事项,需要的朋友参考一下 下策——查询出结果后将时间排序后取第一条 这样做虽然可以取出当前时间最近的一条记录,但是一次查询需要将表遍历一遍,对于百万以上数据查询将比较费时;limit是先取出全部结果,然后取第一条,相当于查询中占用了不必要的时间和空间;还有如果需要批
-
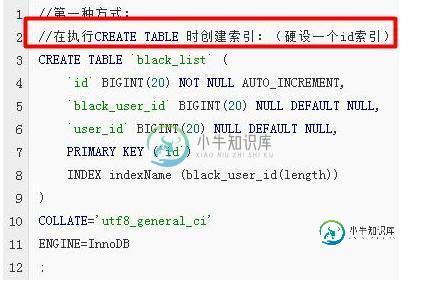 90%程序员面试会遇到的索引优化问题
90%程序员面试会遇到的索引优化问题本文向大家介绍90%程序员面试会遇到的索引优化问题,包括了90%程序员面试会遇到的索引优化问题的使用技巧和注意事项,需要的朋友参考一下 前言 本文给大家分享了90%程序员面试都用得上的索引优化,重点提一下,索引基本原理和创建索引的原则是重点,面试基本必问!大家可以收藏好多理解理解。下面来一起看看详细的介绍吧。 关于索引,分为以下几点来讲解(技术文): 索引的概述(什么是索引,索引的优缺点) 索引的
-
如何通过使用索引在InnoDB上优化COUNT(*)性能
问题内容: 我有一个小而狭窄的InnoDB表,大约有900万条记录。在桌子上或桌子上做的速度非常慢(超过6秒): 虽然该语句不是运行得太频繁,但对其进行优化将是不错的选择。根据http://www.cloudspace.com/blog/2009/08/06/fast- mysql-innodb-count-really- fast/, 这可以通过强制InnoDB使用索引来实现: 解释计划似乎很好
-
一个优化MySQL查询操作的具体案例分析
本文向大家介绍一个优化MySQL查询操作的具体案例分析,包括了一个优化MySQL查询操作的具体案例分析的使用技巧和注意事项,需要的朋友参考一下 问题描述 一个用户反映先线一个SQL语句执行时间慢得无法接受。SQL语句看上去很简单(本文描述中修改了表名和字段名): SELECT count(*) FROM a JOIN b ON a.`S` = b.`S` WHERE a.`L` > '2014-0
-
数据库一般会采取什么样的优化方法?
1、选取适合的字段属性 为了获取更好的性能,可以将表中的字段宽度设得尽可能小。 尽量把字段设置成not null 执行查询的时候,数据库不用去比较null值。 对某些省份或者性别字段,将他们定义为enum类型,enum类型被当做数值型数据来处理,而数值型数据被处理起来的速度要比文本类型块很多。 2、使用join连接代替子查询 3、使用联合union来代替手动创建的临时表 注意:union用法中,两