《优化》专题
-
为我的Java棋盘游戏优化我的“捕获”算法
棋盘游戏是一个11x11矩阵 ex)白板左边的白板,然后黑板直接移动到白板的右边,这将是一个捕获 到目前为止,我有一个 11 x 11矩阵 (int)0=空,1=白,2=黑,3=白 到目前为止,我的算法是基本的,检查上/下/左/右,如果是对立面,然后检查旁边的那块是否是友好的,如果是,那么抓取。 但我不能简单地这么做,因为如果工件位于两个边缘外的行或列上,使用上述算法,我会得到一个ArrayOut
-
优化内存密集型数据流管道的GCP成本
我们希望提高在GCP数据流中运行特定Apache Beam管道(Python SDK)的成本。 我们已经构建了一个内存密集型Apache Beam管道,这需要在每个执行器上运行大约8.5 GB的内存。一个大型机器学习模型目前加载在转换方法中,因此我们可以为数百万用户预先计算建议。 现有的GCP计算引擎机器类型的内存/vCPU比率低于我们的要求(每个vCPU高达8GB RAM)或更高的比例(每个vC
-
 针对相同颜色的大面积优化图像模糊
针对相同颜色的大面积优化图像模糊我正在努力为一个实心(但不是矩形)对象生成一个投影。输入是表示对象不透明度的灰度图像。然后,我想模糊它,给它上色,然后在物体后面画它。 最常见的情况是,这张图像将具有相同色调的大连续区域,这意味着如果我使用标准模糊算法,我将浪费图像绝大多数的周期。考虑下面的输入和输出: 所有的模糊工作都需要在边缘进行,但是在大平面区域上的工作只是浪费了,并且代表了90%以上的像素。 有没有比模糊任意输入图像更快的
-
使用lambda比较初始化优先级队列的方法
我试图初始化一个自定义优先级队列,它作为成员对象存在于类中。它接受一个元组并使用lambda函数作为比较器。 我尝试了一些不同的方法来设置这个问题,但似乎在不同的协议下都失败了, 在我拥有的文件: 这给了: 错误:“”不是类型 如果我只是做
-
从模板化堆继承的模板化优先级队列
我试图为我的编程类写一个优先级队列,但继续得到以下错误:PriorityQueue.cpp: 7:1:错误:“PriorityQueue::PriorityQueue”命名构造函数,而不是类型PriorityQueue.cpp: 7:1:错误:和PriorityQueue没有模板构造函数 我已经做了几个小时了,不知道出了什么问题。以下是它所指的代码:
-
x86-64汇编对齐和分支预测的性能优化
我目前正在编写一些C99标准库字符串函数的高度优化版本,如< code>strlen()、< code>memset()等,使用带有SSE-2指令的x86-64汇编。 到目前为止,我已经设法在性能方面取得了出色的成绩,但是当我试图进一步优化时,我有时会遇到奇怪的行为。 例如,添加甚至删除一些简单的指令,或者简单地重组一些与跳转一起使用的本地标签会完全降低整体性能。而且在代码方面绝对没有理由。 所以
-
查找字符串中的所有字母表如何优化
给定一个字符串s和一个非空字符串p,在s中找到p的字母表的所有起始索引。 null
-
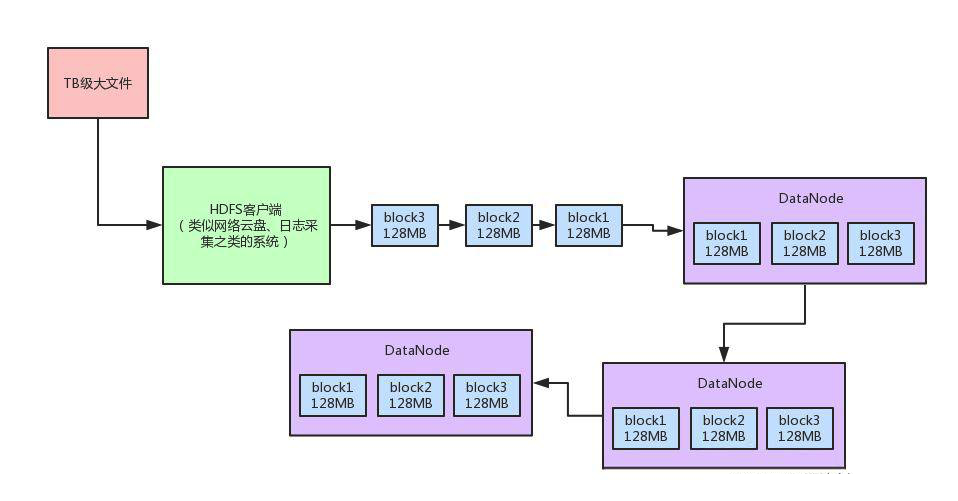 关于超大数据量的系统性能优化设计
关于超大数据量的系统性能优化设计主要内容:1、Chunk缓冲机制,2、Packet数据包机制,3、内存队列异步发送机制,总结:这篇文章,我们来聊一聊在十亿级的大数据量技术挑战下,世界上最优秀的大数据系统之一的Hadoop是如何将系统性能提升数十倍的? 首先一起来画个图,回顾一下Hadoop HDFS中的超大数据文件上传的原理。 其实说出来也很简单,比如有个十亿数据量级的超大数据文件,可能都达到TB级了,此时这个文件实在是太大了。 此时,HDFS客户端会给拆成很多block,一个block就128MB。 这个HDFS客户端
-
javascript - 如何优化基于浏览器的 token 验证频率?
我用 react 写了几个页面,其中有几个页面是需要登录后才能够使用,我当前的判断方式是将获取到的 token 保存在浏览器的 localStorage 里,然后访问这些页面的时候,读取浏览器里是否有 token,然后将 token 发送到服务器验证。 我想请问,每次访问这些需要登录的页面,都会发一次到服务器做验证,这样的方式是不是太频繁了?还有其他更优越的方式吗?
-
性能优化 - Chromium浏览器在RK3568上CPU占用过高?
CPU:RK3568 内核:4.19 系统:debian 11 ,浏览器chromium 91.044 打开网页CPU从30%,随着时间不断增长,CPU占用率一直增长从30%增长到100%为止。 请各位高手给指点一下。 解决文字
-
php - 单服务器视频网站cpu wa高,如何优化?
我是一名内网视频网站管理员。目前我们的网站在局域网内部署,向用户提供在线视频服务。在访问量大时,整体网站访问速度很慢。 服务器环境是centos7 apache mysql php,使用海洋cms作为内容管理系统。 在访问量大时(80端口连接数大约1200),使用top命令查看发现load average达到上百(cpu仅有8核心),并且大部分cpu使用都是wa状态。 由于服务器使用的是挂载的网络
-
 mysql - 一个有关大表分组查询优化的问题?
mysql - 一个有关大表分组查询优化的问题?有ci_trail表,字段为:id, uid(用户id), address(地址), create_time 记录人的定位轨迹,此表大概有100w条数据。想查询每个人最新的一条地址信息。使用如下sql: 查询计划如下图: 可见进行了全表扫描,查询效率很低,请问这种情况应该如何优化sql? 已解决 方案1: 方案2: 先将子查询中的id查询出来,然后将id的结果集逗号隔开填充到in中。因为in的内容
-
具有更改优先级特性的优先级队列,该特性使元素保持有序
我正在寻找一种通过优先级和先到先服务(FCFS)调度线程的方法,如果两个线程具有相同的优先级。我在考虑使用一堆队列或类似的东西。问题是,即使我实现了自己的优先级队列,更改优先级的能力也会破坏插入到该队列的顺序。
-
在任何低优先级工作流之前执行所有高优先级节奏工作流
在https://cadenceworkflow.io/docs/03_concepts/02_activities#activity-task-routing-through-task-lists的留档中,它提到通过每个优先级有一个任务列表和每个优先级有一个工作池来支持多个优先级。在这种实现下,可能仍然有低优先级的工作流在高优先级工作流之前执行。 是否可以实现一个优先级系统,以便在流向高优先级工
-
 MySQL的id关联和索引使用的实际优化案例
MySQL的id关联和索引使用的实际优化案例本文向大家介绍MySQL的id关联和索引使用的实际优化案例,包括了MySQL的id关联和索引使用的实际优化案例的使用技巧和注意事项,需要的朋友参考一下 昨晚收到客服MM电话,一用户反馈数据库响应非常慢,手机收到load异常报警,登上主机后发现大量sql执行非常慢,有的执行时间超过了10s 优化点一: 表结构为: 执行计划: 分析该sql的执行计划,由于tran_id是表的主键,所以查询根据主键降序