《优化》专题
-
Oracle JDBC优化:在spring boot应用程序中启用PreparedStatement缓存
我有一个连接到Oracle数据库的spring boot REST应用程序。我们正在使用JDBCTemplate来使用JDBC。Oracle数据库属性通过以下3个应用程序获得。属性设置: 此应用程序正在使用Hikaricp。从HikariCP网站上,我了解到这个池不缓存PreparedStatement,因为JDBC驱动程序是最好的。 现在,我将在什么地方和什么地方具体说明以确保这些: > Ora
-
为什么GCC不能优化“x”中的逻辑/按位AND对
以下是我声称执行完全相同操作的两个函数: 从逻辑上讲,它们做同样的事情,为了100%确定,我编写了一个测试,通过它们运行了所有40亿个可能的输入,并且它们匹配。( 花费了2.9秒,使用< code>slow()花费了3.8秒。如果我使用一个全零的向量,这两个函数的性能没有明显的差别。 其他编译器: 主线clang 3.7及更高版本甚至对
-
如何优化VBO/IBO以最大限度地利用GPU缓存
我正在使用CUDA上运行的Marching Cubes算法从体积数据生成网格。 我尝试过保存网格并以3种方式渲染它。 将一组粗略的三角形保存为顶点数据的连续数组。我估计第一次通过时的大小,创建一个OpenGL VBO,将其映射到CUDA,并以下面的格式将顶点数据写入其中 并使用绘制它。 VBO中的冗余顶点,每个立方体的冗余顶点,无索引。 VBO中没有冗余顶点,生成索引。 VBO中的冗余顶点,每个立
-
编译器优化可能会导致整数溢出。可以吗?
我有一个。为简单起见,假设 s 占据范围 -2^31 到 2^31-1。我想计算。我允许 是任何值 0 一种解决方案是计算< code>2*(x-1) 1。比我想要的多了一个减法,但是这个不应该溢出来。但是,编译器会将其优化为< code>2*x-1。这是源代码的问题吗?这是可执行文件的问题吗? 以下是 的弩线输出: 以下是 的闩线输出:
-
什么样的GHC优化负责复制大小写表达式?
给定以下代码: GHC在使用优化进行编译时生成此核心(重命名以便于阅读): 请注意GHC如何总共生成4个不同的代码路径。通常,代码路径的数量随着条件的数量呈指数增长。 什么样的GHC优化导致了这种行为?是否有控制此优化的标志?在我的例子中,这会产生巨大的代码膨胀,并且由于深度嵌套的case表达式,使得核心转储非常难以读取。
-
MySQL count(*)、count(1) 和count(字段)的区别以及优化手段
主要内容:1 几种count查询的区别,2 优化COUNT()查询MySQL的count(*)、count(1) 和count(字段)的区别以及count()查询优化手段。 1 几种count查询的区别 count()是一个聚合函数,对于返回的结果集,一行行地判断,如果count函数的参数不是NULL,累计值就加1,否则不加。最后返回累计值。 count(*)、count(主键id)和count(1) 都表示返回满足条件的结果集的总行数;而count(字段),则
-
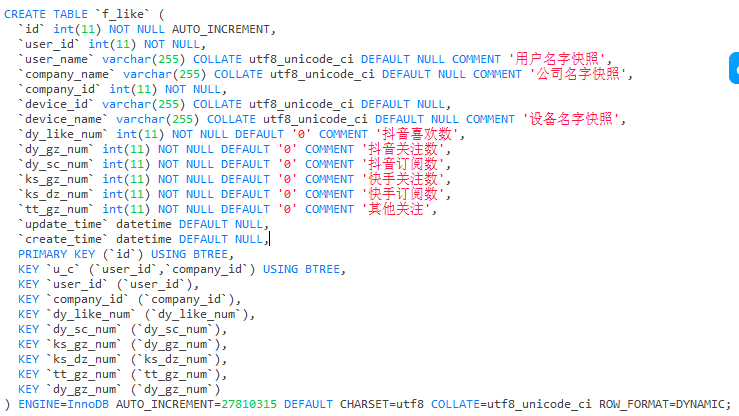 mysql sum多个字段千万级数据如何查询优化?
mysql sum多个字段千万级数据如何查询优化?统计数据表中多个sum千万级数据超时。由于业务需要实时 所以做不来快照表 我加了索引似乎也不管用 后来为了不联表 我直接把快照写入进去了
-
Java 9 Cleaner是否应优先于定稿?
问题内容: 在Java中,重载该方法会产生不良的说唱效果,尽管我不明白为什么。诸如此类的类在Java 8和Java 10中都使用它来确保被调用。但是,引入了Java 9 ,它使用PhantomReference机制而不是GC终结。起初,我认为这只是将终结处理添加到第三方类中的一种方法。但是,其javadoc中给出的示例显示了一个用例,可以很容易地用终结器重写。 是否应该按照Cleaner 重写所有
-
为什么接口优先于抽象类?
问题内容: 我最近参加了一次采访,他们问我一个问题:“为什么接口比抽象类更受青睐?” 我尝试给出一些答案,例如: 我们只能获得一种扩展功能 他们是100%抽象 实现不是硬编码的 他们要求我使用您使用的任何JDBC API。“它们为什么是接口?”。 我可以为此得到更好的答案吗? 问题答案: 该面试问题反映出提出该问题的人的某种信念。我相信这个人是错的,因此您可以选择两个方向之一。 给他们他们想要的答
-
Hibernate vs JPA vs JDO-各自的优缺点
问题内容: 我对ORM这个概念很熟悉,几年前甚至在n.ibernate项目中使用nHibernate。但是,我没有跟上Java中ORM的话题,也没有机会使用任何这些工具。 但是,现在我可能有机会开始为我们的一个应用程序使用一些ORM工具,以尝试摆脱一系列旧式Web服务。 我很难说出JPA规范之间的区别,您从Hibernate库本身得到的东西以及JDO必须提供的东西。 因此,我知道这个问题有点开放,
-
Java:前置,后缀运算符优先级
问题内容: 关于Java中的运算符优先级,我有两个类似的问题。 第一: 根据Oracle教程: postfix(expr ,expr–)运算符的优先级高于前缀( expr,-expr) 因此,我假设该评估顺序为: 但是Java似乎忽略了PRE / POST排序,而是将它们放在一个级别上。所以真正的顺序: 是什么导致答案为(10 * 12 * 12)= 1440。 第二个: 这个问题的例子: 可接受
-
继续-优雅地处理多个错误?
问题内容: 有没有办法清理此(IMO)恐怖代码? 具体来说,我在谈论错误处理。能够一次性处理所有错误将是很好的。 问题答案:
-
Python-如何优雅地处理SIGTERM信号?
问题内容: 假设我们有一个用python编写的琐碎守护程序: 我们将它守护起来,默认使用它发送信号–。 假设当前执行的步骤是。此时此刻,我们正在发送TERM信号。 发生的情况是执行立即终止。 我发现我可以使用处理信号事件,但事实是它仍然会中断当前执行并将控制权传递给。 因此,我的问题是-是否可以不中断当前执行,而是TERM在单独的线程(?)中处理信号,以便能够进行设置,从而有机会优雅地停止运行?
-
Redis类型及其各自的优缺点
问题内容: 我了解Redis会列出,设置和散列 每种类型的优点/缺点是什么,以及在列表上使用集合的地方,或在集合上使用哈希的例子,等等 问题答案: 您要考虑的主要问题是您将要对其进行哪种操作……这比性能要重要。因为,如果没有可用的操作,它将无法正常工作。 首先,查看Redis命令文档,并确保可以找到可用的命令集。我在这里使用的大多数推理在通用编程中也是如此。例如,为什么要在Python中使用字典而
-
Hibernate命名查询及其性能优势?
问题内容: 就像hibernate文档所说的那样,命名查询的目的是将HQL从项目中的不同位置清除到某个xml中的单个位置(在声明方法的情况下),这意味着在查询修改的情况下不需要重新编译,而是重新加载会话工厂这是必需的,这意味着在大多数情况下,由于查询对象被缓存,服务器将启动。但是在注释的情况下,我需要在实体级别定义命名查询。因此,这里再次需要编译。我的问题是命名查询在性能上是否也有帮助。这是我的理