
ANTLR4文法中的优先级问题

我在这里开发了一个小语法,我有一个问题:
grammar test;
term : above_term | below_term;
above_term :
<assoc=right> 'forall' binders ',' forall_term
| <assoc=right> above_term '->' above_term
| <assoc=right> above_term '->' below_term
| <assoc=right> below_term '->' above_term
| <assoc=right> below_term '->' below_term
;
below_term :
<assoc = right> below_term arg (arg)*
| '@' qualid (term)*
| below_term '%' IDENT
| qualid
| sort
| '(' term ')'
;
forall_term : term;
arg : term| '(' IDENT ':=' term ')';
binders : binder (binder)*;
binder : name |<assoc=right>name (name)* ':' term | '(' name (name)* ':' term ')' |<assoc=right> name (':' term)? ':=' term;
name : IDENT | '_';
qualid : IDENT | qualid ACCESS_IDENT;
sort : 'Prop' | 'Set' | 'Type' ;
/**************************************
* LEXER RULES
**************************************/
/*
* STRINGS
*/
STRING : '"' (~["])* '"';
/*
* IDENTIFIER AND ACCESS IDENTIFIER
*/
ACCESS_IDENT : '.' IDENT;
IDENT : FIRST_LETTER (SUBSEQUENT_LETTER)*;
fragment FIRST_LETTER : [a-z] | [A-Z] | '_' | UNICODE_LETTER;
fragment SUBSEQUENT_LETTER : [a-z] | [A-Z] | DIGIT | '_' | '"' | UNICODE_LETTER | UNICODE_ID_PART;
fragment UNICODE_LETTER : '\\' 'u' HEX HEX HEX HEX;
fragment UNICODE_ID_PART : '\\' 'u' HEX HEX HEX HEX;
fragment HEX : [0-9a-fA-F];
/*
* NATURAL NUMBERS AND INTEGERS
*/
NUM : DIGIT (DIGIT)*;
INTEGER : ('-')? NUM;
fragment DIGIT : [0-9];
WS : [ \n\t\r] -> skip;
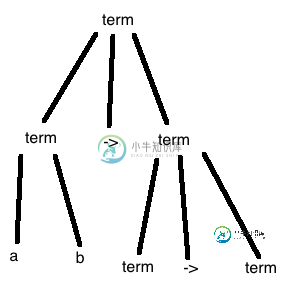
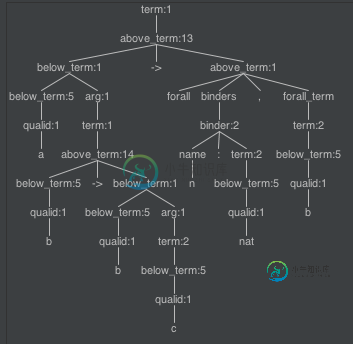
为什么解析器没有在解析树的顶部看到(->)规则?这是优先级问题吗?
共有1个答案

通过在(arg)规则中将term更改为below_term,我们可以修复arg:below_term'('IDENT':='term')';的问题。
让我们以这个表达式为例:A b C。一旦解析器看到模式a b匹配此规则:below_term arg(arg)*,他将a作为below_term并trys将b与arg规则匹配。但是,由于arg现在指向below_term规则,所以除了brabed以外,不会取消above_term。这解决了我的问题。
术语a b->a b c->n:nat,n现在可以这样解析:
-
有人能帮我找到我的PQ的问题吗?
-
我需要一个优先级队列,它首先获得具有最高优先级值的项目。我当前正在使用队列库中的PriorityQueue类。但是,这个函数只先返回值最小的项。我尝试了一些很难看的解决方案,比如(sys.maxint-priority)作为优先级,但我只是想知道是否存在更优雅的解决方案。
-
根据优先表,一元后缀递增和递减运算符比关系运算符有更多的优先级,那么为什么在这样的表达式(x++>=10)中,关系运算符首先计算,然后变量递增呢?
-
要求:我需要我的消息驱动bean(MDB)能够从四个不同的JMS队列中读取消息,MDB应该根据队列的优先级读取消息。 我有4个JMS队列A、B、C和D,优先级分别为8(最高)、7、6和5。因此,如果队列C中有500条消息,而队列A和B是空的。我的MDB应该使用来自队列C的消息。但是当我在高优先级队列(A或B)中收到消息时,我的MDB应该停止从C读取消息,并从高优先级队列中消耗消息(直到队列是空的)
-
这是我写的Dijkstra算法的代码: 在这方面我不能理解的工作 这涉及到: < code>()运算符在这里有什么用?我是说它在这段代码中是如何运作的? 还有为什么我们使用
-
我有一个(我希望)简单的问题要问那些有就餐交响乐经验的人。 基于注释的调度允许设置优先级。如果我为此使用了SchduleParameters.FIRST_PRIORITY和SchduleParameters.LAST_PRIORITY参数,如果每个代理在每个滴答处执行这些方法,则整体调度程序如何解释这一点? > 首先,所有代理都使用ScheduleParameters执行该方法。首先是优先级,然后