《运筹优化》专题
-
MySQL:优化具有很多列的表
问题内容: 我的用户表有26列以上,这正常吗?当该用户表引起我注意时,数据库已被标准化为第3级。设计26列是否可以,或者在设计数据库时应该使用其他优化技术吗? 更多:对表进行分区是什么意思? 问题答案: 26列没有什么问题,但是如果很少使用它们,那就不一样了。 而不是使用26列,而是使用更少的列,并使用序列化字符串将它们分组。 将字段更改为文本字段,然后在代码中可以对它们进行反序列化并使用它们。如
-
提高jQuery性能优化的技巧
本文向大家介绍提高jQuery性能优化的技巧,包括了提高jQuery性能优化的技巧的使用技巧和注意事项,需要的朋友参考一下 下面把提高jQuery性能优化技巧给大家分享如下: 缓存变量 DOM遍历是昂贵的,所以尽量将会重用的元素缓存。 避免全局变量 jQuery与javascript一样,一般来说,最好确保你的变量在函数作用域内。 使用匈牙利命名法 在变量前加$前缀,便于识别出jQuery对象。
-
django-rest-swagger的优化使用方法
本文向大家介绍django-rest-swagger的优化使用方法,包括了django-rest-swagger的优化使用方法的使用技巧和注意事项,需要的朋友参考一下 如下所示: 参考英文文档: http://django-rest-swagger.readthedocs.io/en/latest/ 使用swagger工具结合Django-rest-framework进行restful API的管
-
SQL优化:Xml或定界字符串
问题内容: 希望这只是一个简单的问题,涉及到Sql 2008中的查询时的性能优化。 我曾为在其ETL流程以及一些网站中经常使用Stored Procs的公司工作。我已经看到了他们需要基于一组有限的键值来检索特定记录的情况。我已经看到它以3种不同的方式进行处理,下面的伪代码对此进行了说明。 动态SQL,它包含一个字符串并执行它。 使用用户定义的函数将定界字符串拆分为表 使用XML作为参数而不是带分隔
-
如何优化Elasticsearch的索引编制?
问题内容: 我试图了解如何在Elasticsearch上优化索引。让我澄清我的需求; 我现在有两个指标。可以这样说和(两个索引可以看到大致相同的大小) 我有6台专用于Elasticsearch的机器(我们可以说完全相同的硬件) 我的elasticsearch用法中最重要的部分是写作,因为我实时进行大量写作。 所以我的问题是,如何使用这6台机器优化写入操作? 我是否应该将机器分为两部分,例如3台机器
-
 mysql 8.0.18 安装配置优化教程
mysql 8.0.18 安装配置优化教程本文向大家介绍mysql 8.0.18 安装配置优化教程,包括了mysql 8.0.18 安装配置优化教程的使用技巧和注意事项,需要的朋友参考一下 Mysql安装、配置、优化,供大家参考,具体内容如下 Mysql下载 首先登入官网下载mysql的安装包,官网地址https://dev.mysql.com/下拉到最后选择downloads里的 MySQL Community Server 选择所需下
-
数据库Mysql性能优化详解
本文向大家介绍数据库Mysql性能优化详解,包括了数据库Mysql性能优化详解的使用技巧和注意事项,需要的朋友参考一下 在mysql数据库中,mysql key_buffer_size是对MyISAM表性能影响最大的一个参数(注意该参数对其他类型的表设置无效),下面就将对mysql Key_buffer_size参数的设置进行详细介绍下面为一台以MyISAM为主要存储引擎服务器的配置: 分配了51
-
 VMware虚拟机优化十招技巧
VMware虚拟机优化十招技巧本文向大家介绍VMware虚拟机优化十招技巧,包括了VMware虚拟机优化十招技巧的使用技巧和注意事项,需要的朋友参考一下 在VMware虚拟机(VMware Workstation或VMware Server)中我们可以同时运行多个Guest OS,当同时在同一Host OS中运行多台虚拟机时势必会严重影响到Host OS的运行效率和性能。那么我们如何对虚拟机进行优化以达到最佳的资源利用率呢?在
-
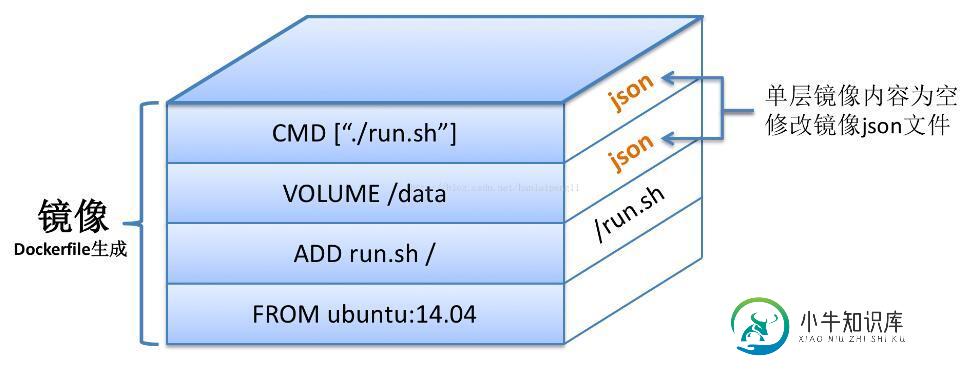 Docker镜像压缩与优化操作
Docker镜像压缩与优化操作本文向大家介绍Docker镜像压缩与优化操作,包括了Docker镜像压缩与优化操作的使用技巧和注意事项,需要的朋友参考一下 现如今docker如此受人追捧,主要是因为它的轻量化、可以快速部署以及资源的利用。但是一个docker images质量的好与坏,主要取决于Dockerfile编写的质量。同样功能的镜像,但是不同的Dockerfile build出来的镜像大小是不一样的,这是因为docker
-
JIT未优化涉及Integer.MAX_VALUE的循环
问题内容: 在写另一个问题的答案时,我注意到用于JIT优化的奇怪边框。 以下程序 不是 “ Microbenchmark”, 也不 旨在可靠地衡量执行时间(如对另一个问题的回答所指出)。它仅用作MCVE来重现此问题: 它基本上运行相同的循环,其中将限制一次设置为,将一次设置为。 当在Win7 / 64上使用JDK 1.7.0_21和 计时结果如下: 显然,对于JIT 的情况,JIT可以完成预期的工
-
简述Hbase性能优化的思路
本文向大家介绍简述Hbase性能优化的思路相关面试题,主要包含被问及简述Hbase性能优化的思路时的应答技巧和注意事项,需要的朋友参考一下 解答: 1、在库表设计的时候,尽量考虑rowkey和columnfamily的特性 2、进行hbase集群的调优
-
kafka producer如何优化打入速度?
本文向大家介绍kafka producer如何优化打入速度?相关面试题,主要包含被问及kafka producer如何优化打入速度?时的应答技巧和注意事项,需要的朋友参考一下 增加线程 提高 batch.size 增加更多 producer 实例 增加 partition 数 设置 acks=-1 时,如果延迟增大:可以增大 num.replica.fetchers(follower 同步数据的线
-
 Swift图像处理之优化照片
Swift图像处理之优化照片本文向大家介绍Swift图像处理之优化照片,包括了Swift图像处理之优化照片的使用技巧和注意事项,需要的朋友参考一下 Core Image能通过分析图片的各个属性,人脸的区域等进行自动优化图片。我们只需要调用autoAdjustmentFiltersWithOptions这个API方法获取各个自动增强滤镜来优化图片即可。不管是人物照片还是风景照均可增强效果。 (以前另外还有个叫autoAdjus
-
 浅谈React + Webpack 构建打包优化
浅谈React + Webpack 构建打包优化本文向大家介绍浅谈React + Webpack 构建打包优化,包括了浅谈React + Webpack 构建打包优化的使用技巧和注意事项,需要的朋友参考一下 本文介绍了React + Webpack 构建打包优化,分享给大家,具体如下: 使用 babel-react-optimize 对 React 代码进行优化 检查没有使用的库,去除 import 引用 按需打包所用的类库,比如 lodash
-
优化的最长公共子序列
我目前正在尝试为2个给定字符串查找和打印最长的公共子序列。我使用最常见的算法,没有递归。如果我保留整个数组,这是一项简单的任务,但我正在尝试对其进行一点优化,只使用2行,您可以在下面的代码中看到。有了这个更改,查找长度仍然很简单,工作正常,但恢复子序列不再那么容易了。我尝试了几种方法,但都不起作用。下面你可以看到我最后的尝试。虽然它适用于相同的情况,但也有失败的情况。经过长时间的思考,我开始相信没