《运筹优化》专题
-
分区表场景下的 SQL 优化
本文向大家介绍分区表场景下的 SQL 优化,包括了分区表场景下的 SQL 优化的使用技巧和注意事项,需要的朋友参考一下 导读 有个表做了分区,每天一个分区。 该表上有个查询,经常只查询表中某一天数据,但每次都几乎要扫描整个分区的所有数据,有什么办法进行优化吗? 待优化场景 有一个大表,每天产生的数据量约100万,所以就采用表分区方案,每天一个分区。 下面是该表的DDL: 该表上经常发生下面的慢查询
-
优化多列的空检查方式
问题内容: 假设我有一个包含三列的表,并且我想采用其中至少一个列值不为null的所有行,现在我正在使用以下方式进行null检查,并且工作正常 预期的输出,这给了我我的查询 我想知道还有没有更好的方法来执行此null检查 问题答案: 您可以通过三种方式检查行中是否为非NULL值: 您可以使用Microsoft SQL Server Management Studio来比较多个查询。 比较结果: 对比
-
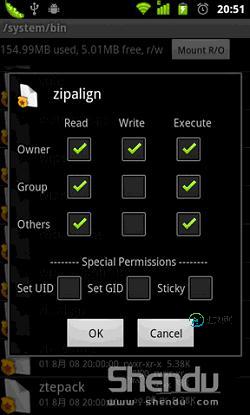 Android Zipalign工具优化Android APK应用
Android Zipalign工具优化Android APK应用本文向大家介绍Android Zipalign工具优化Android APK应用,包括了Android Zipalign工具优化Android APK应用的使用技巧和注意事项,需要的朋友参考一下 生成的Android应用APK文件最好进行优化,因为APK包的本质是一个zip压缩文档,经过优化能使包内未压缩的数据有序的排列,从而减少应用程序运行时的内存消耗。我们可以使用Zipalign
-
 浅谈react性能优化的方法
浅谈react性能优化的方法本文向大家介绍浅谈react性能优化的方法,包括了浅谈react性能优化的方法的使用技巧和注意事项,需要的朋友参考一下 React性能优化思路 软件的性能优化思路就像生活中去看病,大致是这样的: 使用工具来分析性能瓶颈(找病根) 尝试使用优化技巧解决这些问题(服药) 使用工具测试性能是否确实有提升(疗效确认) 初识react只是为了尽快完成项目,后期进行代码审查时候发现有很多地方需要优化,因此做了
-
Django的性能优化实现解析
本文向大家介绍Django的性能优化实现解析,包括了Django的性能优化实现解析的使用技巧和注意事项,需要的朋友参考一下 一 利用标准数据库优化技术 传统数据库优化技术博大精深,不同的数据库有不同的优化技巧,但重心还是有规则的。在这里算是题外话,挑两点通用的说说: 索引,给关键的字段添加索引,性能能更上一层楼,如给表的关联字段,搜索频率高的字段加上索引等。Django建立实体的时候,支持给字段添
-
Node.js尾部调用优化:可能吗?
问题内容: 到目前为止,我一直喜欢JavaScript,并决定使用Node.js作为我的引擎,它声称Node.js提供了TCO。但是,当我尝试使用Node.js运行此(显然是尾部调用)代码时,会导致堆栈溢出: 现在,我做了一些挖掘,发现了这一点。在这里,看来我应该这样写: 但是,这给了我语法错误。我试过它的各种排列,但在所有的情况下,Node.js的似乎不满 的东西 。 本质上,我想了解以下内容:
-
优化Objectmapper[Java8]的字符串解析
我实现了我试图实现的目标,然而,我不满足于不必要的(?)字符串解析来达到我的目标。 null null 我的汽车类:
-
优化apache beam/cloud数据流启动
我用apache-beam做了几个测试,使用了自动缩放工作人员和1个工作人员,每次我看到启动时间大约为2分钟。是否有可能缩短启动时间,如果有,建议哪些最佳做法来缩短启动时间?
-
java - 树结构递归如何优化?
翻到祖师爷代码,发现树结构的数据是后端通过递归去生成的,效率非常低,请问有什么方法可以优化吗?
-
第 25 章:性能剖析与优化
Haskell 是一门高级编程语言,一门真正的高级编程语言。 我们可以一直使用抽象概念、 幺半群、函子、以及多态进行编程,而不必与任何特定的硬件模型打交道。 Haskell 在语言规范方面下了很大的功夫,力求语言可以不受制于某个特定的求值模型。 这几层抽象使得我们可以把 Haskell 作为计算本身的记号, 让编程人员关心他们问题的关键点,而不用操心低层次的实现细节, 使得人们可以心无旁骛地进行编
-
Spark性能优化指南——高级篇
1 数据倾斜调优 1.1 调优概述 有的时候,我们可能会遇到大数据计算中一个最棘手的问题——数据倾斜,此时Spark作业的性能会比期望差很多。数据倾斜调优,就是使用各种技术方案解决不同类型的数据倾斜问题,以保证Spark作业的性能。 2.2 数据倾斜发生时的现象 绝大多数task执行得都非常快,但个别task执行极慢。比如,总共有1000个task,997个task都在1分钟之内执行完了,但是
-
Spark性能优化指南——基础篇
1 前言 在大数据计算领域,Spark已经成为了越来越流行、越来越受欢迎的计算平台之一。Spark的功能涵盖了大数据领域的离线批处理、SQL类处理、流式/实时计算、机器学习、图计算等各种不同类型的计算操作,应用范围与前景非常广泛。大多数同学(包括笔者在内),最初开始尝试使用Spark的原因很简单,主要就是为了让大数据计算作业的执行速度更快、性能更高。 然而,通过Spark开发出高性能的大数
-
浅谈React组件之性能优化
本文向大家介绍浅谈React组件之性能优化,包括了浅谈React组件之性能优化的使用技巧和注意事项,需要的朋友参考一下 高德纳: "我们应该忘记忽略很小的性能优化,可以说97%的情况下,过早的优化是万恶之源,而我们应该关心对性能影响最关键的另外3%的代码。" 不要将性能优化的精力浪费在对整体性能提高不大的代码上,而对性能有关键影响的部分,优化并不嫌早。因为,对性能影响最关键的部分,往往涉及解决方案
-
 mysql优化之like和=性能详析
mysql优化之like和=性能详析本文向大家介绍mysql优化之like和=性能详析,包括了mysql优化之like和=性能详析的使用技巧和注意事项,需要的朋友参考一下 引言 那使用过数据库的人大部分都知道,like和=号在功能上的相同点和不同点,那我在这里简单的总结下: 1,不同点:like可以用作模糊查询,而'='不支持此功能;如下面的例子,查询info表中字段id第一个字母为1的数据: 2,相同点:like和"="都可以进行
-
php+mysql查询优化简单实例
本文向大家介绍php+mysql查询优化简单实例,包括了php+mysql查询优化简单实例的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了php+mysql查询优化的方法。分享给大家供大家参考。具体分析如下: PHP+Mysql是一个最经常使用的黄金搭档,它们俩配合使用,能够发挥出最佳性能,当然,如果配合Apache使用,就更加Perfect了. 因此,需要做好对mysql的查询优化,下面