《运筹优化》专题
-
10-SpringBoot定制和优化内嵌Tomcat
10.1 配置日志 10.1.1 在配置文件中配置 在application.properties中添加 server.tomcat.accesslog.enabled=true server.tomcat.accesslog.directory=d:/temp/logs 10.2 EmbeddedServletContainerCustomizer接口,通过代码配置tomcat package
-
25. 循环优化(所有处理器)
分析程序你经常会看到大部分时间都花费在最内层的循环上面。 提高速度的方法就是认真地用汇编优化最花时间的循环。 其它的部分仍然用高级语言完成。 下面所有的例子都假定数据全在1级cache内。 如果数据cache失效是瓶颈,那么没有理由去对指令进行优化。 而应该把注意力集中在组织你的数据,尽量减少cache失效次数(第七章)。 25.1 PPlain和PMMX上的循环 循环通常包括一个控制叠代次数的计
-
微信 iOS SQLite 源码优化实践
前言 随着微信iOS客户端业务的增长,在数据库上遇到的性能瓶颈也逐渐凸显。在微信的卡顿监控系统上,数据库相关的卡顿不断上升。而在用户侧也逐渐能感知到这种卡顿,尤其是有大量群聊、联系人和消息收发的重度用户。 我们在对SQLite进行优化的过程中发现,靠单纯地修改SQLite的参数配置,已经不能彻底解决问题。因此从6.3.16版本开始,我们合入了SQLite的源码,并开始进行源码层的优化。 本文将分享
-
常见问题 - 系统内核优化
ulimit 设置系统打开文件数设置,解决高并发下 too many open files 问题。此选项直接影响单个进程容纳的客户端连接数。 Soft open files 是Linux系统参数,影响系统单个进程能够打开最大的文件句柄数量,这个值会影响到长连接应用如聊天中单个进程能够维持的用户连接数, 运行ulimit -n能看到这个参数值,如果是1024,就是代表单个进程只能同时最多只能维持10
-
After Effects Roto 笔刷和优化遮罩
使前景对象(如演员)与背景分开是许多视觉效果和合成工作流中的关键步骤。在您已经创建用于隔离对象的遮罩后,您可以替换背景、有选择地对前景应用效果,以及执行其他更多操作。 Roto 笔刷和优化边缘工具 Roto 笔刷工具和优化边缘工具针对遮罩分段和创建操作提供了另一种更快的工作流。A. Roto 笔刷 B. 优化边缘 Roto 笔刷 使用此工具可创建初始遮罩,以将物体从其背景中分离。使用 Roto
-
如何优化前端应用性能
我开始写前端应用的时候,并不知道一个 Web 应用需要优化那么多的东西。编写应用的时候,运行在本地的机器上,没有网络问题,也没有多少的性能问题。可当我把自己写的博客部署到服务器上时,我才发现原来我的应用在生产环境上这么脆弱。 我的第一个真正意义上的 Web 应用——开发完应用,并可供全世界访问,是我的博客。它运行在一个共享 256 M 内存的 VPS 服务器上,并且服务器是在国外,受限于网络没有备
-
非随机行为和代码优化
语言的实现是一个很复杂的过程,这个复杂并非说它很难,虽然的确有一些难点,但总的来说并不是那么难以理解,复杂和简单相对,是指细节很多,很多事情需要具体到情况来讨论,比如龙书讲优化的部分,很多都是小的优化点;还有一些可能矛盾的地方,需要多种方案配合处理,比如前述静态类型推导,虽然纯粹的静态和动态类型都很容易实现,但要想各取所长就很麻烦了 幸运的是,至少在计算机领域,很多东西是非随机性的,语言也不例外,
-
 虹软科技 算法优化 笔试
虹软科技 算法优化 笔试#24届软开秋招面试经验大赏# 投递岗位:算法优化工程师 笔试时间:8.20 120min 双机位 笔试题型:20个不定项选择、2个编程、1个数据结构论述题、1个4选1的论述题 笔试考察知识点: 选择题涉及概率分布、贝叶斯概率计算、排列组合、函数求极限、机器学习、矩阵奇异值分解、C/C++基础知识、图像处理方法、HOG特征、SIFT特征、进程与线程、算法时间复杂度计算等等。 编程有点难度,第1题5
-
 ES性能优化原理大揭秘
ES性能优化原理大揭秘主要内容:1、一道面试题的引入:,2、性能优化的杀手锏:Filesystem Cache,3、数据预热,4、冷热分离,5、ES中的关联查询,6、Document 模型设计,7、分页性能优化1、一道面试题的引入: 如果面试的时候碰到这样一个面试题:ElasticSearch(以下简称ES) 在数据量很大的情况下(数十亿级别)如何提高查询效率? 这个问题说白了,就是看你有没有实际用过 ES,因为啥?其实 ES 性能并没有你想象中那么好的。 很多时候数据量大了,特别是有几亿条数据的时候,可能你会懵逼的
-
Java性能优化的七个方向
主要内容:文章目录,1.复用优化,2.计算优化,2.3 惰性加载,3.结果集优化,4.资源冲突优化,5.算法优化,6.高效实现,7.jvm 优化,8.总结复用优化 结束集优化 高效实现 算法优化 计算优化 资源冲突优化 jvm 优化 1.复用优化 编码逻辑上的优化: 重复的代码可以提取出来,做成公共的方法。 数据复用: 缓存和缓存 : 常见于对数据的暂存,然后批量传输或者写入。多使用顺序方式,用来缓解不同设备之间频繁地、缓慢地随机写,缓冲主要针对的是。 : 常见于对已读取数据的复用,通过将它们缓
-
 Api接口优化的几个方法
Api接口优化的几个方法主要内容:1.哪些问题会引起接口性能问题,2.问题解决1.哪些问题会引起接口性能问题 数据库慢查询 深度分页问题 未加索引 索引失效 join过多 子查询过多 in中的值太多 单纯的数据量过大 业务逻辑复杂 循环调用 顺序调用 线程池设计不合理 锁设计不合理 机器问题(fullGC,机器重启,线程打满) 2.问题解决 2.1 慢查询(基于mysql) 深度分页 当分页所以深度不大的时候当然没问题,随着分页的深入 这个时候,mysql会查出来10000
-
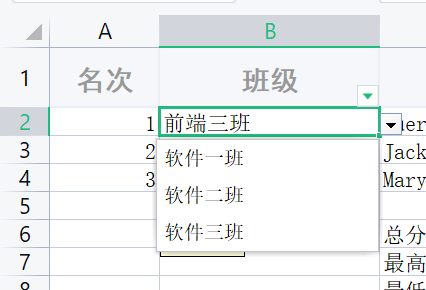 前端 - 设置excel下拉框优化?
前端 - 设置excel下拉框优化?背景: 技术栈:项目: vue3 + vite 场景: 希望导出的excel的某一列填充下拉框内容,例如 尝试: 相关代码如下 上述代码一次只能给某一个单元格加下拉框,所以要达到使B列单元格都加上下拉框的目的,就要给一个很大的终止值,去循环遍历。 有没有什么更好的方法去优化?
-
java - mysql sql语句优化的问题?
我有个商品表里面有30多万的数据,商品标题是中文,系统模糊查询的时候老是会显示慢,同时我在这个字段创建了一个普通索引;但是查询还是会慢?请教高手要如何进行优化? select * from goods_name where title_name like "%电器%"
-
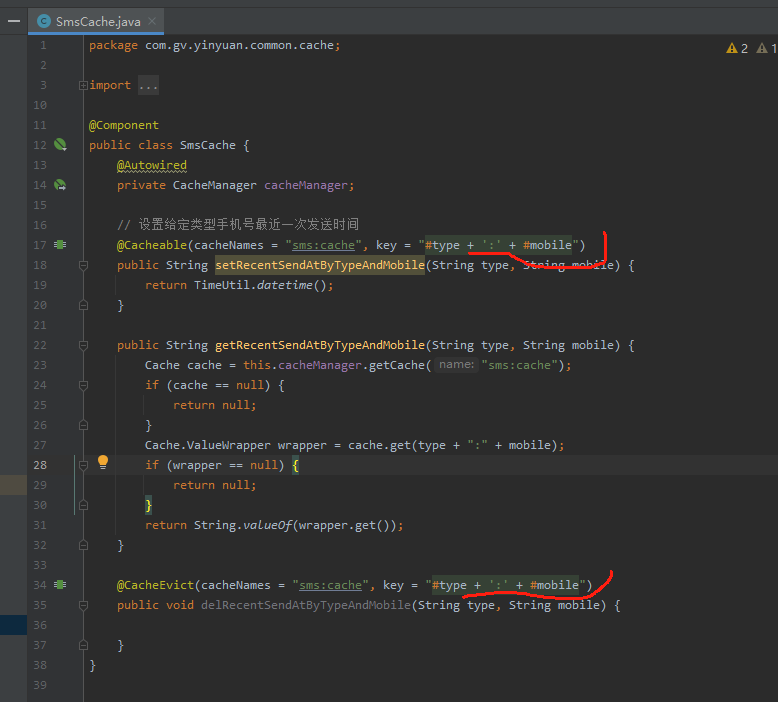 spring - Spring Cache如何简化和优化?
spring - Spring Cache如何简化和优化?关于spring缓存的问题: 类似我通过注解方式定义的缓存,我定义了设置缓存,获取缓存、删除缓存三个方法,但我感觉其中设置、删除缓存方法都很奇怪,设置缓存居然要提供返回值才能实际设置;删除缓存又是一个空的方法体。缓存是通过这种方式使用的吗?我感觉很奇怪 我在 application.yml 中配置了缓存的 cache-names;然后使用 @Cachable 注解IDE还是会提示要提供 name,
-
javascript - useWindowSize如何加上防抖优化?
useWindowResize的代码如下,如何加防抖,优化效率,减少触发次数