《算法工程师》专题
-
Demo 工程
介绍 Rokid Mobile SDK Demo 主要提供 Rokid Mobile SDK API 使用示例,并提供了 Swift 和 OC 版本,请开发者各取所需。 GitHub 地址: https://github.com/Rokid/RokidMobileSDKiOSDemo
-
python常见排序算法基础教程
本文向大家介绍python常见排序算法基础教程,包括了python常见排序算法基础教程的使用技巧和注意事项,需要的朋友参考一下 前言:前两天腾讯笔试受到1万点暴击,感觉浪费我两天时间去牛客网做题……这篇博客介绍几种简单/常见的排序算法,算是整理下。 时间复杂度 (1)时间频度一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道。但我们不可能也没有必要对每个算法都上机测试,只需
-
Python常用算法学习基础教程
本文向大家介绍Python常用算法学习基础教程,包括了Python常用算法学习基础教程的使用技巧和注意事项,需要的朋友参考一下 本节内容 算法定义 时间复杂度 空间复杂度 常用算法实例 1.算法定义 算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出。如果一
-
PHP抽奖算法程序代码分享
本文向大家介绍PHP抽奖算法程序代码分享,包括了PHP抽奖算法程序代码分享的使用技巧和注意事项,需要的朋友参考一下 抽奖算法需要满足的需求如下: 1.可以控制中奖的概率 2.具有随机性 3.最好可以控制奖品的数量 4.根据用户ID或者ip、手机号、QQ号等条件限制抽奖次数 初期就这些需求,然后根据网上的资料,采用了一种阶段式抽取的方法,大家下面看一下整体的程序: 该程序是在ThinkPHP框架下完
-
第二章 程序的灵魂之算法
一个程序应包括: 对数据的描述。在程序中要指定数据的类型和数据的组织形式,即数据结构(data structure)。 对操作的描述。即操作步骤,也就是算法(algorithm)。 Nikiklaus Wirth提出的公式: 数据结构 + 算法 = 程序 教材认为: 程序 = 算法 + 数据结构 + 程序设计方法 + 语言工具和环境 这4个方面是一个程序涉及人员所应具备的知识。 本课程的目的是使同
-
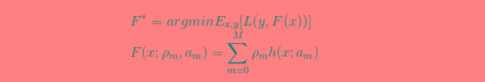 说一下gbdt的全部算法过程
说一下gbdt的全部算法过程本文向大家介绍说一下gbdt的全部算法过程相关面试题,主要包含被问及说一下gbdt的全部算法过程时的应答技巧和注意事项,需要的朋友参考一下 参考回答: GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一种用于回归的机器学习算法,该算法由多棵回归决策树组成,所有树的结论累加起来做最终答
-
分析算法-递推方程(河内塔)
我在维基百科上看到这个求解河内塔的递归算法。谁能给我解释一下我是怎么得到这个算法的递推方程的? null 将N-1个光盘从A移动到B,这将使光盘n单独位于peg A上 将磁盘n从A移动到C 将N-1个光盘从B移动到C,使它们位于光盘N上 上面是一个递归算法,为了执行步骤1和3,对n-1再次应用相同的算法。整个过程是一个有限的步骤,因为在某一点上,算法将需要n=1。这一步,将单个光盘从pega移动到
-
 携程5.13推荐算法暑期一面
携程5.13推荐算法暑期一面自我介绍 八股(可能遗漏): 1. 讲讲推荐系统流程 2. Transformer 位置编码是什么 3. QKV 注意力公式为什么除以根号 d 4. 简单讲讲 GCN 5. 简单讲讲 RNN 6. RNN 里的参数是什么样的(答:参数共享) 7. Dropout 是怎么做的?有什么作用?推理和训练时 Dropout 的区别?如果推理也用 dropout 会怎么样? 8. 讲讲 BN?BN 训练和推
-
程序员 - 这道算法题怎么解?
有一个由 n x n 个格子组成的正方形,除了其中一个格子是空外,其余格子都放置了一个数字,数字从 1 到 n x n - 1,然后通过移动数字,让数字从左到右从上到下按顺序排列,空的格子会在右下角。 求实现目标的最小步骤数,并列出所有步骤。一个步骤中在一个方向上可以移动多个数字,步骤格式使用 [空格子位置, 移动方向, 移动数字个数] 表示 移动方向有 rtl, ltr, ttb, btt 四种
-
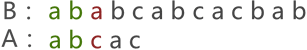 BF算法(串模式匹配算法)
BF算法(串模式匹配算法)主要内容:BF算法原理,BF算法实现,BF算法时间复杂度,总结串的模式匹配算法,通俗地理解,是一种用来判断两个串之间是否具有"主串与子串"关系的算法。 主串与子串:如果串 A(如 "shujujiegou")中包含有串 B(如 "ju"),则称串 A 为主串,串 B 为子串。主串与子串之间的关系可简单理解为一个串 "包含" 另一个串的关系。 实现串的模式匹配的算法主要有以下两种: 普通的模式匹配算法; 快速模式匹配算法; 本节,先来学习 普通模式匹配(BF)
-
算法题 - 一致性哈希算法
一致性哈希算法 tencent2012笔试题附加题 问题描述: 例如手机朋友网有n个服务器,为了方便用户的访问会在服务器上缓存数据,因此用户每次访问的时候最好能保持同一台服务器。 已有的做法是根据ServerIPIndex[QQNUM%n]得到请求的服务器,这种方法很方便将用户分到不同的服务器上去。但是如果一台服务器死掉了,那么n就变为了n-1,那么ServerIPIndex[QQNUM%n]与S
-
数据结构与算法 - KMP算法
KMP算法解决的问题是字符匹配,这个算法把字符匹配的时间复杂度缩小到O(m+n),而空间复杂度也只有O(m),n是target的长度,m是pattern的长度。 部分匹配表(Next数组):表的作用是 让算法无需多次匹配S中的任何字符。能够实现线性时间搜索的关键是 在不错过任何潜在匹配的情况下,我们”预搜索”这个模式串本身并将其译成一个包含所有可能失配的位置对应可以绕过最多无效字符的列表。 Nex
-
 美团-工程效能组-开发工程师实习生(工程基建方向)-一面
美团-工程效能组-开发工程师实习生(工程基建方向)-一面项目 介绍网页音视频项目 项目代码量多少?是一个人完成的吗? 介绍SaaS视频项目 Spring Spring框架有什么特性?(❌不知道这个问题要问什么,答的扩展性、封装性啥的) 控制反转了解吗?原理呢?(❌简单说了下,原理不知道) AOP了解吗?项目用过吗?(❌简单说了下,项目里没用过) Java 线程池的七个参数? 拒绝策略有哪些?(❌漏了一个静默丢弃) 阻塞队列的长度怎么设置?(❌不会) J
-
 JVM的垃圾回收算法工作原理详解
JVM的垃圾回收算法工作原理详解本文向大家介绍JVM的垃圾回收算法工作原理详解,包括了JVM的垃圾回收算法工作原理详解的使用技巧和注意事项,需要的朋友参考一下 怎么判断对象是否可以被回收? 共有2种方法,引用计数法和可达性分析 1.引用计数法 所谓引用计数法就是给每一个对象设置一个引用计数器,每当有一个地方引用这个对象时,就将计数器加一,引用失效时,计数器就减一。当一个对象的引用计数器为零时,说明此对象没有被引用,也就是“死对象
-
外部合并排序算法是如何工作的?
我正在尝试理解外部合并排序算法是如何工作的(我看到了相同问题的一些答案,但没有找到我需要的东西)。我正在阅读Jeffrey McConnell的《算法分析》一书,我正在尝试实现那里描述的算法。 例如,我有输入数据:,我只能将4个数字加载到内存中。 我的第一步是以4个数字块读取输入文件,在内存中对它们进行排序,然后将其中一个写入文件A和文件B。 我得到: 现在我的问题是,如果这些文件中的块不适合内存