
说一下gbdt的全部算法过程

参考回答:
GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一种用于回归的机器学习算法,该算法由多棵回归决策树组成,所有树的结论累加起来做最终答案。当把目标函数做变换后,该算法亦可用于分类或排序。
1)明确损失函数是误差最小
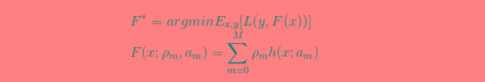
2)构建第一棵回归树
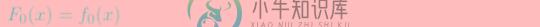
3)学习多棵回归树

迭代:计算梯度/残差gm(如果是均方误差为损失函数即为残差)
步长/缩放因子p,用 a single Newton-Raphson step 去近似求解下降方向步长,通常的实现中 Step3 被省略,采用 shrinkage 的策略通过参数设置步长,避免过拟合
第m棵树fm=p*gm
模型Fm=Fm-1+p*gm
4)F(x)等于所有树结果累加

-
本文向大家介绍请你说一说洗牌算法?相关面试题,主要包含被问及请你说一说洗牌算法?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 考察点: 公司:腾讯 1、Fisher-Yates Shuffle算法 最早提出这个洗牌方法的是 Ronald A. Fisher 和 Frank Yates,即 Fisher–Yates Shuffle,其基本思想就是从原始数组中随机取一个之前没取过的数字到新的
-
本文向大家介绍说一下类装载的执行过程?相关面试题,主要包含被问及说一下类装载的执行过程?时的应答技巧和注意事项,需要的朋友参考一下 类装载分为以下 5 个步骤: 加载:根据查找路径找到相应的 class 文件然后导入; 检查:检查加载的 class 文件的正确性; 准备:给类中的静态变量分配内存空间; 解析:虚拟机将常量池中的符号引用替换成直接引用的过程。符号引用就理解为一个标示,而在直接引用直接
-
本文向大家介绍说一下小顶堆的调整过程?相关面试题,主要包含被问及说一下小顶堆的调整过程?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 堆排序的步骤分为三步: 1)建堆;2)交换数据;3)向下调整。 假设我们现在要对数组arr[]={8,5,0,3,7,1,2}进行排序(降序): 首先要先建小堆: 堆建好了下来就要开始排序了: 现在这个数组就已经是有序的了。
-
当程序主动使用某个类时,如果该类还未被加载到内存中,JVM会通过加载、连接、初始化3个步骤对该类进行类加载。 1、加载 加载指的是将类的class文件读入到内存中,并为之创建一个java.lang.Class对象。 类的加载由类加载器完成,类加载器由JVM提供,开发者也可以通过继承ClassLoader基类来创建自己的类加载器。 通过使用不同的类加载器可以从不同来源加载类的二进制数据,通常有如下几
-
本文向大家介绍简单说一下hadoop和spark的shuffle过程相关面试题,主要包含被问及简单说一下hadoop和spark的shuffle过程时的应答技巧和注意事项,需要的朋友参考一下 hadoop:map端保存分片数据,通过网络收集到reduce端 spark:spark的shuffle是在DAGSchedular划分Stage的时候产生的,TaskSchedule要分发Stage到各个w
-
GBDT on Spark on Angel GBDT(Gradient Boosting Decision Tree):梯度提升决策树 是一种集成使用多个弱分类器(决策树)来提升分类效果的机器学习算法,在很多分类和回归的场景中,都有不错的效果。 1. 算法介绍 如图1所示,这是是对一群消费者的消费力进行预测的例子。简单来说,处理流程为: 在第一棵树中,根节点选取的特征是年龄,年龄小于30的被分为