《顺丰机器学习》专题
-
 阿里 高德 机器学习算法实习 一面面经
阿里 高德 机器学习算法实习 一面面经全程50分钟,这次是女面试官,人很好,不怎么拷打,开始时先介绍了面试流程 1.自我介绍 2.介绍第一个项目,我的是一个RAG的项目,吟唱完让我说一下项目的两个亮点,我就介绍了语义感知的文本切分和缓解幻觉的两个点,又提问了一些问题 3.介绍第二个项目,我的是一个论文项目,我直接共享桌面对着模型图讲了一遍,当然中间也穿插着提问,殊不知这次共享有几率让我寄掉 4.问一个基础问题,面试官问了我transf
-
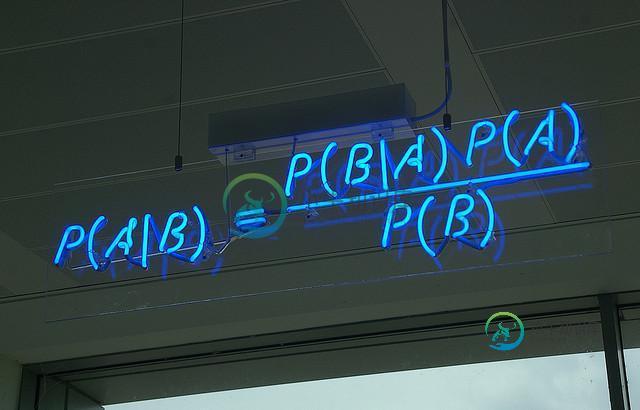 用Python从零实现贝叶斯分类器的机器学习的教程
用Python从零实现贝叶斯分类器的机器学习的教程本文向大家介绍用Python从零实现贝叶斯分类器的机器学习的教程,包括了用Python从零实现贝叶斯分类器的机器学习的教程的使用技巧和注意事项,需要的朋友参考一下 朴素贝叶斯算法简单高效,在处理分类问题上,是应该首先考虑的方法之一。 通过本教程,你将学到朴素贝叶斯算法的原理和Python版本的逐步实现。 更新:查看后续的关于朴素贝叶斯使用技巧的文章“Better Naive Bayes: 12 T
-
随机森林和 GBDT 的学习
参考文献:http://www.zilhua.com/629.html http://www.tuicool.com/articles/JvMJve http://blog.sina.com.cn/s/blog_573085f70101ivj5.html 我的数据挖掘算法:https://github.com/linyiqun/DataMiningAlgorithm 我的算法库:https://g
-
数学随机范围负
如果我做:Math.random() * 4-2 这会让我得到一个范围(-2,2),2是排他性的吗?我认为这是正确的,但我很少得到正数(是的,我知道这是一个随机算法,我们必须无限随机地生成它才能感觉到,但我只是想确保) 新问题 如果我想要所有从-1到1的随机有理数,两个边界都包括在内,那么这条线是否有效:Math.random() * 2.00000000000000001 - 1; 我查了一下,
-
 顺丰科技 测试开发工程师(09.08一面,已过)
顺丰科技 测试开发工程师(09.08一面,已过)自我介绍。 1. 你为什么找测试开发? 2. 测试开发通常比较繁琐,需要经常修改开发提交过来的bug,你怎么看? 3. 测试的基本流程你了解吗? 4. 测试有哪些基本的方法?哪些框架?(随便说了几个,没深究) 5. 讲一个你的项目(挑了一个最近的) 反问: 1. 你为什么不问我基础?(面试官:我看了你的博客,觉得你基本上没什么问题,啊啊啊啊啊,激动!!!) 2. 测试开发有什么需要注意学习的技术栈
-
 顺丰 9.7 java笔试编程题第二题 构造试卷
顺丰 9.7 java笔试编程题第二题 构造试卷考完就突然会写了,真是麻了 题目:有n种题型,每种题型的数量各异,出一份试卷需要由m道题型各不相同的题构成 输入:第一个数是n,第二个数是m,下面的一行是每种题型的数量 5 3 8 5 4 7 2 输出 8 思路: 整体思路就是将每种题型根据数量排序,然后每次将前m多的题型扣掉第m多的题型的数量 然后再排序再扣除,直至剩余题型不足m种,循环结束 #顺丰笔试#
-
 Android实现仿美团、顺丰快递数据加载效果
Android实现仿美团、顺丰快递数据加载效果本文向大家介绍Android实现仿美团、顺丰快递数据加载效果,包括了Android实现仿美团、顺丰快递数据加载效果的使用技巧和注意事项,需要的朋友参考一下 我们都知道在Android中,常见的动画模式有两种:一种是帧动画(Frame Animation),一种是补间动画(Tween Animation)。帧动画是提供了一种逐帧播放图片的动画方式,播放事先做好的图像,与gif图片原理类似,就像是在放
-
 23届春招 顺丰科技Java开发5.16三面凉经
23届春招 顺丰科技Java开发5.16三面凉经面试时间下午3点-3点半,赛码网面试平台。鼠人薪资要高了,感觉寄了。 首先做了自我介绍。 问有其他offer没有。 为啥考虑深圳,不去上海杭州。 问为啥不找本专业的。 问一二面考察的重点和你觉得有哪些不足。 问项目。 问期望薪资,说要高了,其他同学没有要的这么高的。#23届春招##顺丰科技校招##java春招#
-
 23届春招 顺丰科技Java开发5.15二面凉经
23届春招 顺丰科技Java开发5.15二面凉经面试时间下午14:30 - 15:00,用的赛码网面试平台,一个面试官,面试官人挺好的。鼠人许愿能进三面吧。 首先问了在哪个校区,问了考不考虑深圳,气候啥的。。。 然后让我做了自我介绍。 问了java的序列化与反序列化,对象数据转换成二进制字符串便于保存和传输,二进制字符串转换成对象数据。 问了接口与抽象类的区别,规范代码格式,实现代码复用。 问了异常的分类,编译时异常和运行时异常。 问了try,
-
机器学习中有哪些不同的梯度下降算法?
本文向大家介绍机器学习中有哪些不同的梯度下降算法?,包括了机器学习中有哪些不同的梯度下降算法?的使用技巧和注意事项,需要的朋友参考一下 使用梯度下降的背后思想是在各种机器学习算法中将损失降至最低。从数学上讲,可以获得函数的局部最小值。 为了实现这一点,定义了一组参数,并且需要将它们最小化。给参数分配系数后,就可以计算误差或损失。接下来,权重被更新以确保误差最小化。除了参数,弱学习者可以是用户,例如
-
简要说说一个完整机器学习项目的流程?
本文向大家介绍简要说说一个完整机器学习项目的流程?相关面试题,主要包含被问及简要说说一个完整机器学习项目的流程?时的应答技巧和注意事项,需要的朋友参考一下 抽象成数学问题(确定是一个分类问题、回归问题还是聚类问题,明确可以获得什么样的数据) 获取数据(数据要具有代表性,对数据的量级也要有一个评估,多少样本,多少特征,对内存的消耗,考虑内存是否能放得下,如果放不下考虑降维或者改进算法,如果数据量太大
-
哪些机器学习算法不需要做归一化处理?
本文向大家介绍哪些机器学习算法不需要做归一化处理?相关面试题,主要包含被问及哪些机器学习算法不需要做归一化处理?时的应答技巧和注意事项,需要的朋友参考一下 概率模型不需要归一化,因为他们不关心变量的值,而是关心变量的分布和变量之间的条件概率,如决策树、RF。而像Adaboost、GBDT、SVM、LR、KNN、KMeans之类的最优化问题就需要归一化
-
在机器学习中,为何要经常对数据归一化?
本文向大家介绍在机器学习中,为何要经常对数据归一化?相关面试题,主要包含被问及在机器学习中,为何要经常对数据归一化?时的应答技巧和注意事项,需要的朋友参考一下 归一化可以: 归一化后加快了梯度下降求最优解的速度(两个特征量纲不同,差距较大时,等高线较尖,根据梯度下降可能走之字形,而归一化后比较圆走直线) 归一化有可能提高精度 (一些分类器需要计算样本之间的距离,如果一个特征值域范围非常大,那么距离
-
如何在Azure机器学习笔记本上安装Jupyter扩展?
我在Azure machine Learning上创建了一个虚拟机,我正在运行一个简单的jupyter笔记本。我想安装jupyter扩展,因为我真的需要可折叠的标题,但它似乎不起作用。我尝试了pip安装,它已经安装,但菜单没有出现。。。
-
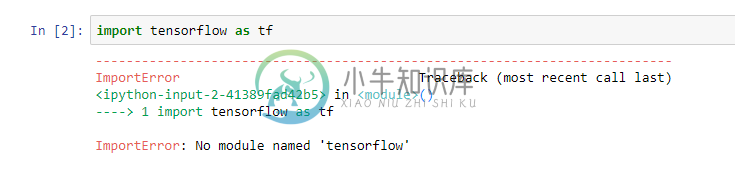 iPython Azure机器学习中缺失的模块拉伸流(经典)
iPython Azure机器学习中缺失的模块拉伸流(经典)昨天,我从Azure机器学习工作室(经典版)的iPython笔记本安装了tensorflow模块。使用(!pip install tensorflow)安装模块后,导入工作正常。但是今天,当我尝试导入这个模块时,出现了“缺少模块”错误,当我尝试重新安装模块时,它运行良好。我有什么遗漏吗?在使用之前,我是否每天都需要安装模块?有人能解释一下吗?