《顺丰机器学习》专题
-
 秋招日寄——快手机器学习算法工程师-一面
秋招日寄——快手机器学习算法工程师-一面惯例:自我介绍+讲项目 考察问题: 介绍下transformer(语言组织不好,虽然知道原理但是讲的很乱) 为什么需要multi head attention 介绍下layernorm和batchnorm 为什么layernorm在NLP下有效,batchnorm则不是? pytorch的model.train()和model.eval()的区别 介绍一下集成学习 算法题:二维网格求左上到右下的最
-
 美团 机器学习/数据挖掘算法工程师hr面
美团 机器学习/数据挖掘算法工程师hr面到这里为止,所有流程都走完了。 9月8日 一面,当天出结果 9月12日 二面,当天出结果 9月14日 三面,次日出结果 9月19日 hr面 1. hr上来先介绍了一下这个岗位未来具体做的事情,介绍的很详细。 2. 让我自己讲讲对这个岗位的理解 3. 自我介绍 4. 聊天 ①职业规划 ②你说你是美团的忠实用户,你可以聊聊你自己对美团的印象吗 (本人是究极吃货+旅游爱好者,出去旅游几乎全靠美团订酒店+
-
 美团 机器学习/数据挖掘算法工程师 三面
美团 机器学习/数据挖掘算法工程师 三面9月8日 一面,当天出结果 9月12日 二面,当天出结果 1. 自我介绍 2. 项目介绍,围绕项目出发询问一些相关的问题。这个过程在15分钟左右。 3. :你前面写题了吗 我:一面写了,二面没写 4. 在我以为要出题的时候,没有了……进入反问环节 我:啊!怎么这么快 :因为我们这个三轮的技术面是一个综合的评估,有些问题前两面面过了,就没必要再问了 后续流程:说本次面试的结果很快就会出。还剩最后一轮
-
 美团 机器学习/数据挖掘算法工程师 二面
美团 机器学习/数据挖掘算法工程师 二面9月8日 一面,当天出结果 9月12日 二面 1. 自我介绍 2. 项目介绍,围绕项目出发询问一些相关的问题,一定量的八股,还有这个模型为什么不能用在这方面,以及有什么优化方案之类的想法 3. 学校问题 :我看你这个是两年制的啊 答:其实是三年制的,一般是第一二年上课,第三年做论文。我第一年就把课全上完了所以可以直接进入论文阶段了 :哦?那你这样时间不会很赶吗 答:对比三年的同学可能是有点吧,但我
-
 美团 机器学习/数据挖掘算法工程师 一面
美团 机器学习/数据挖掘算法工程师 一面说在前面:感谢团子面试官帮我缓解了面试焦虑症。团子面试官人很好,很亲切,还让我不要紧张谢谢团子,可惜人太菜了 8月7日 笔试 4道a了3道 8月22日 收到了 (一志愿)到店-自然语言处理算法工程师 的面试邀请,无奈当时那周实在是太太太忙了,又要搬家又要坐高铁,实在是抽不出时间。于是反馈希望可以安排到下一周,结果上官网一看流程,直接挂了 9月5日 接到 (二志愿)机器学习/数据挖掘算法工程师 电话
-
 微步在线 机器学习算法工程师 二面面经
微步在线 机器学习算法工程师 二面面经地狱一样的理论问询,今年秋招最难的一场…… 数学问了中心极限定理,大数定理,Γ分布和κ分布关系…… 机器学习问了特征选择,特征归一化,马尔科夫链,gibbs采样,集成学习,选择性偏差,决策树并行计算,xgboost和adaboost样本权重…… 深度学习问了卷积原理,梯度传播稳定性,BN本质,torch和tensorflow的图理论…… 大模型问了很多工程上的问题,出现loss spike啦,波峰
-
 快手机器学习算法暑期实习oc,来还愿了
快手机器学习算法暑期实习oc,来还愿了牛客许愿果然灵! 今天太累了,暑期实习终于告一段落了,按之前所说分享一下快手的面经吧~有什么问题欢迎评论区提问! timeline 3.31投递 4.8一面 4.10二面 4.11 HR面 4.15 oc
-
随机顺序和分页Elasticsearch
问题内容: 在此问题中, 有一个功能要求,要求使用可选种子进行订购,以允许随机订购。 我需要能够对随机排序的结果进行分页。用Elasticsearch 0.19.1怎么做? 谢谢。 问题答案: 您可以使用唯一字段(例如id)和随机盐的哈希函数进行排序。根据结果的真实程度,您可以执行以下原始操作: 或像 第二个示例将产生更多随机结果,但速度会稍慢。 为了使这种方法起作用,必须存储字段。否则,查询
-
在中学脱机后无法选择小学
我有一个副本设置与1个仲裁器和3个Mongo数据库。 其中2个数据库(db1和db2)我给出了成为主数据库的同等优先级,第三个数据库(db3)我给出了0优先级。 我是不是漏掉了什么??
-
 顺丰科技(大数据平台开发工程师专业一面,实习)
顺丰科技(大数据平台开发工程师专业一面,实习)暑期实习(投得算是比较早),来和大家分享一下面经~😀 流程:顺丰流程个人感觉挺高效,体验也非常不错。 投递完之后就测评 4-15 显示简历通过安排面试 4-24 一面结束 代码是手写单例模式 4-25 二面结束 HR面 4-29 邮件offer (以下面试问题不是按照时间顺序,是按照个人回忆的顺序😅😅)我的技术栈是Spark方面的。 1.自我介绍,详细介绍一个个人的关于分布式系统开发的项目
-
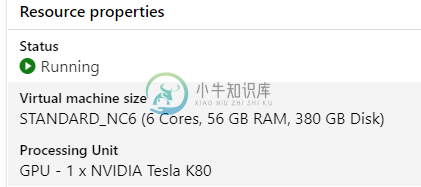 Tensorflow图形处理器似乎无法在Azure机器学习GPU计算上工作
Tensorflow图形处理器似乎无法在Azure机器学习GPU计算上工作我是Azure机器学习的新手,所以我希望我做的一切都很好。我用GPU类型的新计算实例创建了新的Jupyter笔记本 但是跑步的时候 从tensorflow文档中,我得到了数字0——当检查我有什么设备时,它只是一些CPU 你知道这是为什么吗?在这里做什么? 看起来有了PyTorch,一切都很好,正在运行 返回True 软件包版本是: tensorflow 2.4。0
-
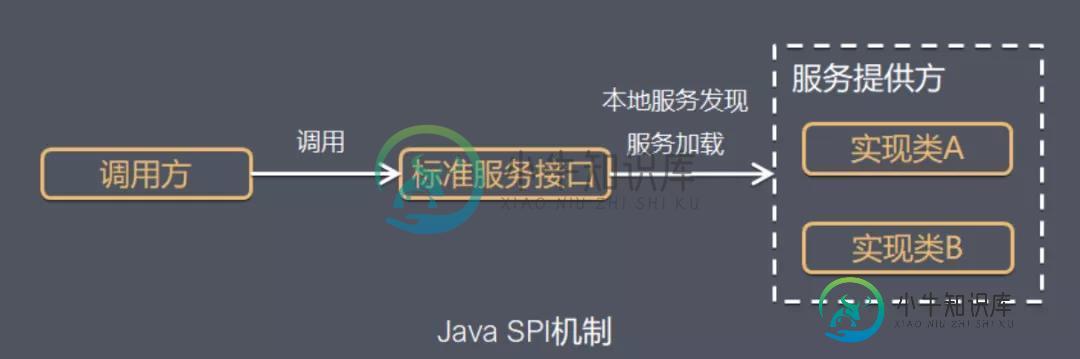 深入学习Java中的SPI机制
深入学习Java中的SPI机制本文向大家介绍深入学习Java中的SPI机制,包括了深入学习Java中的SPI机制的使用技巧和注意事项,需要的朋友参考一下 概述 SPI(Service Provider Interface),是JDK内置的一种服务提供发现机制,可以用来启用框架扩展和替换组件,主要是被框架的开发人员使用,比如java.sql.Driver接口,其他不同厂商可以针对同一接口做出不同的实现,MySQL和Postgre
-
七、集成学习和随机森林
假设你去随机问很多人一个很复杂的问题,然后把它们的答案合并起来。通常情况下你会发现这个合并的答案比一个专家的答案要好。这就叫做群体智慧。同样的,如果你合并了一组分类器的预测(像分类或者回归),你也会得到一个比单一分类器更好的预测结果。这一组分类器就叫做集成;因此,这个技术就叫做集成学习,一个集成学习算法就叫做集成方法。 例如,你可以训练一组决策树分类器,每一个都在一个随机的训练集上。为了去做预测,
-
七、集成学习和随机森林
假设你去随机问很多人一个很复杂的问题,然后把它们的答案合并起来。通常情况下你会发现这个合并的答案比一个专家的答案要好。这就叫做群体智慧。同样的,如果你合并了一组分类器的预测(像分类或者回归),你也会得到一个比单一分类器更好的预测结果。这一组分类器就叫做集成;因此,这个技术就叫做集成学习,一个集成学习算法就叫做集成方法。 例如,你可以训练一组决策树分类器,每一个都在一个随机的训练集上。为了去做预测,
-
机器学习资料集 Datasets - Ex 3: The iris 鸢尾花资料集
机器学习资料集/ 范例三: The iris dataset http://scikit-learn.org/stable/auto_examples/datasets/plot_iris_dataset.html 这个范例目的是介绍机器学习范例资料集中的iris 鸢尾花资料集 (一)引入函式库及内建手写数字资料库 #这行是在ipython notebook的介面裏专用,如果在其他介面则可以拿掉