《顺丰机器学习》专题
-
 顺丰-it项目管理 终面面经(许愿oc)
顺丰-it项目管理 终面面经(许愿oc)上周四下午二面后,这周一约的今天下午 4.17约面 4.18终面 很棒!!!顺丰的面试官都特别好!!!疯狂打call!!!我这次的发挥也很不错(三次中最好的),刚开始还有点紧张,后面我的逻辑捋顺了后,问答也是行云流水,逻辑完整,虽然提前预备的问题一个也没问。 大家也是,其实没必要非得提前准备,简单了解一下可能会问的方面就行了,我这两天疯狂刷顺丰it项目管理的面经,好几个帖子都能背下来了,结果人家面
-
 顺丰冷链仓配运营储备初面面经
顺丰冷链仓配运营储备初面面经本来投递的不是仓储,原本投的岗一直没有推进,就在牛客上投了下仓储,请HR帮忙推进我原本的岗的进度,然后被告知,卡着一直没动,她就帮我把简历要去仓储推进了。 11月7日HR张告诉我把我简历要过去了 11月8日下午2点打电话+发邮件通知我当天下午6点面试 面试: 2v1业务+HR 总共40分钟左右 ①自我介绍 ②挖简历 先问的我大一做的一个快递相关问题的调研 再问我简历上的一段实习 做了什么(没有问我
-
 顺丰科技2023届暑期实习生面经-产品运营
顺丰科技2023届暑期实习生面经-产品运营一面-技术面36min-04/22 自我介绍 你认为的产品运营?需要具备的能力? 有自学过运营方面的知识吗? 最有成就感的事情 大学报考初衷?为什么不从事技术相关岗位? 看重实习的点(薪资、待遇、企业文化)? 假如需要去到物流中转站线下实习,你能接受吗? 对顺丰科技的了解? 大学(目前)的规划? 反问:本场面试的不足?部门具体业务?结果通知? 面完感觉又要感谢信+1辽,积累面试经验吧,不过还是希望
-
 Python语言描述机器学习之Logistic回归算法
Python语言描述机器学习之Logistic回归算法本文向大家介绍Python语言描述机器学习之Logistic回归算法,包括了Python语言描述机器学习之Logistic回归算法的使用技巧和注意事项,需要的朋友参考一下 本文介绍机器学习中的Logistic回归算法,我们使用这个算法来给数据进行分类。Logistic回归算法同样是需要通过样本空间学习的监督学习算法,并且适用于数值型和标称型数据,例如,我们需要根据输入数据的特征值(数值型)的大小来
-
将图像转换为CVPixelBuffer以进行机器学习Swift
问题内容: 我正在尝试让Apple的示例核心ML模型在2017年WWDC上演示以正常运行。我正在使用GoogLeNet尝试对图像进行分类(请参阅Apple机器学习页面)。该模型将CVPixelBuffer作为输入。我有一个用于本演示的名为imageSample.jpg的图像。我的代码如下: 我总是在输出而不是图像分类中遇到意外的运行时错误。我的转换图像的代码如下: 我从以前的帖子中获得了此代码。我
-
 附答案 | 最强Python面试题之机器学习篇
附答案 | 最强Python面试题之机器学习篇写在之前 大家好呀,我是帅蛋。 今天来更新机器学习篇面试,这一部分一共 32 道题。Python 面试八股文尽在帅蛋的【最强Python面试题】,大家一定要记得点赞收藏呀!!! 欢迎和帅蛋聊一聊~扣扣2群:609771600,获取最新秋招信息 & 内推进度,日常聊聊迷茫吹吹牛皮,抱团取暖 顺便提一句,我所有和面试相关的内容都会放在#帅蛋的面试空间# 中,大家可以关注下这个话题~ 我会尽我最大的努力
-
 Python机器学习之决策树算法实例详解
Python机器学习之决策树算法实例详解本文向大家介绍Python机器学习之决策树算法实例详解,包括了Python机器学习之决策树算法实例详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python机器学习之决策树算法。分享给大家供大家参考,具体如下: 决策树学习是应用最广泛的归纳推理算法之一,是一种逼近离散值目标函数的方法,在这种方法中学习到的函数被表示为一棵决策树。决策树可以使用不熟悉的数据集合,并从中提取出一系列规则,
-
“特征提取”是机器学习的核心任务吗?
我一直在和一个朋友争论“特征提取”。他说,ML的主要任务是提取特征。但我不同意。一般来说,特征提取不是一项ML任务。如果我们认为wx b是表示ML的最简单的方法,那么ML的任务就是找到最好的w和b。x是特征。ML试图找出给定x的最佳w和b值,它与训练数据匹配,从而学习如何找到w和b。 我的朋友说提取特征是ML的核心任务。但据我所知,特征提取主要是一项数据预处理任务。
-
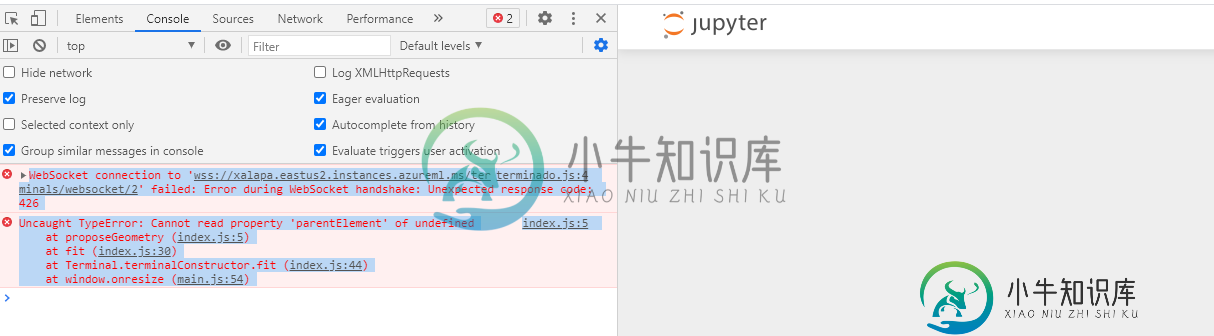 在Microsoft Azure机器学习中打开终端时出错
在Microsoft Azure机器学习中打开终端时出错在Microsoft Azure机器学习下创建计算实例并选择Jupyter以打开Jupyter笔记本后,我将从菜单中选择新建终端。然而,我得到以下错误: 我已经重新创建了compute实例,但运气不佳。 你知道这个问题与什么有关吗? 谢谢
-
 使用Azure机器学习检测图像中的符号
使用Azure机器学习检测图像中的符号四年前,我发布了这个问题,得到了一些答案,不幸的是,超出了我的技能水平。我刚刚参加了一个build tour会议,他们在会上谈到了机器学习,这让我想到了使用ML来解决我的问题的可能性。我在azure站点上发现了这一点,但我认为它对我没有帮助,因为它的范围非常狭窄。 以下是我正在努力实现的目标: 我有一个源图像: ML是解决这个问题的好工具吗?如果是的话,有什么开始的建议吗?
-
 百度 机器学习算法工程师 共享求捞
百度 机器学习算法工程师 共享求捞[toc] 百度 机器学习算法工程师 凉经 投递 2022.07.25 牛客投递,后面牛客上内推了,发了一个内推确认链接,就等于是官网内推投递吧应该 一面通知 2022.07.29 通知面试,直接发的2022.08.02 晚上 20 : 00一面 一面 2022.08.02 面试时长:60 min 面试平台: 如流(百度自家的) 面试过程,分为3部分 项目 介绍项目,问了两个项目 在问项目过程中,
-
 百度机器学习算法提前批一面凉经
百度机器学习算法提前批一面凉经约的8点开始, 8点面试官进来后说要上卫生间,等到8点10分开始,一共60分钟。 1、开始先聊了会儿在字节实习的内容,主要聊场景; 2、聊完后开始问xgboost(简历有写),很细,都是答完后继续往下深挖,答的不好: 和GBDT的区别 什么场景用lr,什么场景用xgboost,什么场景用nn 构造树的过程 怎么来做多分类的 。。。 3、auc指标的含义 4、分类问题为什么用交叉熵不用mse,从公式
-
100 行 python 代码实现机器学习自动分类
准备工作 1. 准备一张mysql数据库表,至少包含这些列:id、title(文章标题)、content(文章内容)、segment(中文切词)、isTec(技术类)、isSoup(鸡汤类)、isMR(机器学习类)、isMath(数学类)、isNews(新闻类) 2. 根据你关注的微信公众号,把更新的文章的title和content自动写入数据库中,具体方法见《教你成为全栈工程师(Full Sta
-
 24春招小红书机器学习算法工程师
24春招小红书机器学习算法工程师全程25分钟 手撕:lc5 只需要输出长度,中心扩展秒了 项目 Transformer中缩放点击注意力为什么要除以根号下dk(这个问题被问到好多次了,给出了原文解释) 为什么值是根号下dk而不是dk,dk的2/3次方等?(这里李沐的动手学深度学习给出了一个解释:假设查询和键的所有元素都是独立的随机变量,并且都满足零均值和单位方差,那么两个向量的点积的均值为0,方差为d。为确保无论向量长度如何,点积
-
 蚂蚁机器学习算法一面不热不凉经
蚂蚁机器学习算法一面不热不凉经发个面经攒攒人品吧家人们😥 上来全是问基础,太烧脑了呜呜 1.面试官介绍了他们是支付宝广告技术部,主要做搜广推aigc大模型等,包括涉及的业务等 1.开始严刑拷打了呜呜。问我在阿里做aigc项目,主要负责了哪块?问相关的vision transformer有没有了解过?我说没有只看过transformer,然后就问那你说说transformer。。。 2.问了神经网络中最大池化层的反向传播怎么算