《顺丰机器学习》专题
-
在机器学习中处理地理空间坐标
我正在建立一个机器学习模型,其中一些列是物理地址(我可以将其转换为X / Y坐标),但我对ML算法如何处理这一点有点困惑。有没有一种特定的方法可以将地理位置转换成列,以便用于ML(分类和/或回归)中? 提前感谢!
-
生产中机器学习算法的实验设计
我已经准备好了机器学习算法。我想在一个拥有70个城市的国家将其投入生产。但在将其推广到 70 个城市之前,我想在 1 个城市进行实验,以评估它在生产中的性能。但是,我现在面临一个问题,如果出现以下情况,我应该设置什么标准:1. 时间(我可以将其投入生产多少个月)2.数据(在实时环境中我需要多少数据来评估算法性能) 任何人都可以在生产环境中指导此机器学习实验吗? 编辑:我正在将机器学习应用于美国的价
-
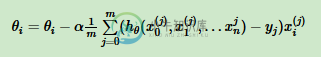 python实现机器学习之多元线性回归
python实现机器学习之多元线性回归本文向大家介绍python实现机器学习之多元线性回归,包括了python实现机器学习之多元线性回归的使用技巧和注意事项,需要的朋友参考一下 总体思路与一元线性回归思想一样,现在将数据以矩阵形式进行运算,更加方便。 一元线性回归实现代码 下面是多元线性回归用Python实现的代码: 特别需要注意的是要弄清:矩阵的形状 在梯度下降的时候,计算两个偏导值,这里面的矩阵形状变化需要注意。 梯度下降数学式子
-
机器学习和人工智能之间的区别
本文向大家介绍机器学习和人工智能之间的区别,包括了机器学习和人工智能之间的区别的使用技巧和注意事项,需要的朋友参考一下 人工智能 人工智能是指可以使非自然元素变得智能的科学。简单来说,人造物体,人造物体可以自己理解和思考。 机器学习 机器学习是指机器无需编程即可学习的方式。简而言之,机器学习是数据驱动的应用程序,它可以基于变化的输入做出自己的决定,并且可以随着时间的推移改进其决定。 以下是机器学习
-
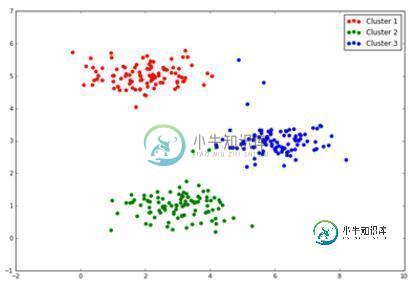 Python机器学习之K-Means聚类实现详解
Python机器学习之K-Means聚类实现详解本文向大家介绍Python机器学习之K-Means聚类实现详解,包括了Python机器学习之K-Means聚类实现详解的使用技巧和注意事项,需要的朋友参考一下 本文为大家分享了Python机器学习之K-Means聚类的实现代码,供大家参考,具体内容如下 1.K-Means聚类原理 K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大
-
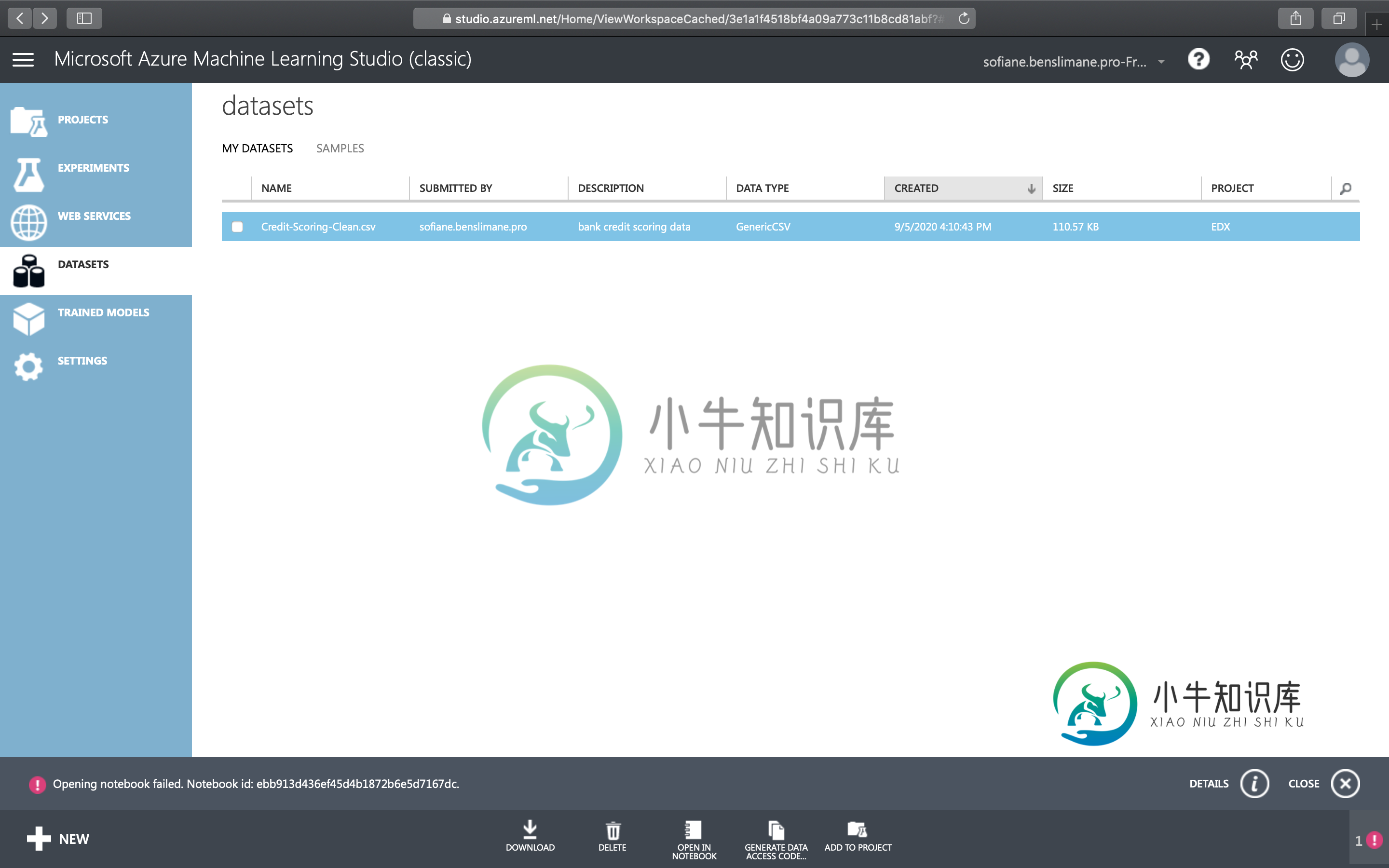 在Azure机器学习工作室打开笔记本
在Azure机器学习工作室打开笔记本我是Azure机器学习的新手。 我试图从Azure机器学习工作室经典中的数据集中打开一个笔记本。 但我得到了这个错误: 打开笔记本失败。笔记本id:ebb913d436ef45d4b1872b6e5d7167dc。 正如你在图片上看到的,我甚至不可能访问左侧菜单中的所有笔记本。
-
机器学习如何比较不同的特征集
假设我有两组不同的特性A和B。我正在尝试确定哪一组特性是最好的。由于我的数据集很小,所以我使用了漏掉一个交叉验证作为最终指标。我正试图弄清楚我的实验装置,我在以下几种方式中做出选择: 1) 将特征集A赋予我的分类器(并可选地运行特征选择),将特征集B赋予同一分类器(也可选地运行特征选择),然后比较这两个分类器之间的LOOCV错误? 2) 将特征集A和B赋予分类器,然后明确地对其进行特征选择,然后根
-
从新的Azure机器学习工作室导出ARFF?
我在新的Azure机器学习工作室工作,但我没有看到像Azure机器学习经典版那样转换为ARFF模块。是否有人知道此功能是否仍然存在以及如何访问它?
-
 深算所机器学习助理工程师一面
深算所机器学习助理工程师一面全程面试大概1小时,流程: 1.自我介绍,(项目,实习。。。。。) 2. 决策树原理 3.信息熵和基尼系数取值范围,连续性和离散型数据是否都能用 4. XGBoost原理 5.为什么要用泰勒展开 7.PCA原理 8.什么样矩阵PCA不适用 9.SVM损失函数 10. 决策森林和决策树的对比,分类和回归分别如何决策 11. 啥叫多态?啥叫重写? 12. Python 迭代器和生成器是怎么回事? (本
-
涉及面最广的机器学习资料大全
资料内容涵盖 小白(前置知识) 初级(了解初识) 中级(系统学习) 高级(应用拓展) 部分文件清单 /小白(前置知识)/ /小白(前置知识)/数学/ /小白(前置知识)/数学/复分析(原书第3版) L /小白(前置知识)/数学/复分析笔记 /小白(前置知识)/数学/小波与傅里叶分析基础 /小白(前置知识)/数学/线性代数 /小白(前置知识)/数学/线性代数第8版 /小白(前置知识
-
 Spark 机器学习算法研究和源码分析
Spark 机器学习算法研究和源码分析本项目对 spark ml 包中各种算法的原理加以介绍并且对算法的代码实现进行详细分析,旨在加深自己对机器学习算法的理解,熟悉这些算法的分布式实现方式。
-
 Sklearn 与 TensorFlow 机器学习实用指南第二版
Sklearn 与 TensorFlow 机器学习实用指南第二版2006 年,Geoffrey Hinton 等人发表了一篇论文,展示了如何训练能够识别具有最新精度(> 98%)的手写数字的深度神经网络。他们称这种技术为“Deep Learning”。
-
 蚂蚁 机器学习算法实习 一面面经
蚂蚁 机器学习算法实习 一面面经一共50分钟左右,基本没八股 1.自我介绍 2.挑一个项目详细介绍一下,我介绍了一下我的RAG的项目,吟唱完面试官说提问几个重要的点,第一个问了一下数据集怎么构建的,第二个问了一下大模型怎么解决幻觉问题,第三个问我数据集构建问答切分怎么考虑语义问题 3.让我详细介绍另一个项目,我另一个项目是论文项目,吟唱完面试官又提问几个重要的点,第一个问我论文里情绪划分详细怎么做的,第二个问我共情怎么定义的,都
-
 美团机器学习数据挖掘算法面经
美团机器学习数据挖掘算法面经一面 问实习 问的比较详细 然后问基础 XGBOOST算法详细介绍 XGBOOST算法与LightGBM区别 怎么筛选数据特征以及PCA怎么做 欠拟合怎么解决 注意不是过拟合 还问了一个业务问题 因为可能是美团平台事业部 写代码 leetcode 322 零钱兑换 要求同时输出零钱数量 以及 零钱组合 动态规划 粗心了 最开始只写了零钱数量 SQL 代码 比较简单 两个情形 一个题目 面试官水平挺
-
 超参数科技 - 机器学习研究员 - 一面
超参数科技 - 机器学习研究员 - 一面8-24面试,还没结果 算法题:矩阵中原有1的行和列置1,原地修改。要求空间复杂度低(我写的是复杂度最高的,面试官问有没有优化的方法,我讲了思路) 快速排序 单链表判断环的存在,如何找到入口 损失函数用过什么 python值传递和引用传递 过拟合如何解决 介绍SVM, pooling, 1*1conv transformer介绍,如果长序列爆显存,如何处理。 YOLOv8了解吗 目标检测的评估指标