《顺丰机器学习》专题
-
集成学习应用:随机森林算法
主要内容:决策树和随机森林,算法应用及其实现,总结随机森林(Random Forest,简称RF)是通过集成学习的思想将多棵树集成的一种算法,它的基本单位是决策树模型,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。我们知道,集成学习的实现方法主要分为两大类,即 Bagging 和 boosting 算法,随机森林就是通过【Bagging 算法+决策树算法】实现的。前面已经学习过决策树算法,因此随机森林算法
-
Android 事件触发机制的深入学习
本文向大家介绍Android 事件触发机制的深入学习,包括了Android 事件触发机制的深入学习的使用技巧和注意事项,需要的朋友参考一下 Android 事件触发机制的深入学习 最近在研究android的事件触发和传播机制,说来很惭愧,web下的事件太熟悉不过了,可在android中却很郁闷,常用的触摸事件都糊里糊涂的,在网上看了半天,也整理一份,供大家参考: 监控触摸事件,主要是实现OnGe
-
第 1 章 计算机科学:将抽象机械化
计算机科学是个新领域,不过它几乎已经触及人类工作的每个方面。计算机、信息系统、文本编辑器、电子表格的普及,以及使得计算机更便于使用、人们生产效率的精彩应用程序的激增,都显示出计算机科学对社会的影响。该领域有个重要的部分,涉及如何让程序设计更容易以及让软件更可靠。不过从根本上讲,计算机科学是一门抽象的科学,它为人们思考问题以及找到适当的机械化技术解决问题而建立模型。 其他科学是顺其自然地研究宇宙。例
-
什么服务用于触发分配给机器学习任务的Azure管道?
我有一个在SVM上训练的模型,数据集作为CSV,作为blob存储中的blob上传。如何更新CSV以及如何使用更改来触发重新训练ML模型的管道。
-
将训练有素的机器学习模型部署到生产中的步骤
我是ML世界的新手,当阅读关于用训练数据构建模型并最终测试数据以适应要求时,直到这一点我都能够理解,我的问题是一旦测试模型就准备好了 生产部署后是否需要训练/重新训练模型? 如果是这样,做法是什么? 有没有办法持久化假设,以便模型可以使用持久化的结果进行预测? 每天、每周或每月重新训练模型是好的做法吗? 假设spark MLib用于构建模型 让我补充更多细节。当我训练模型时,为了论证,它会在预生产
-
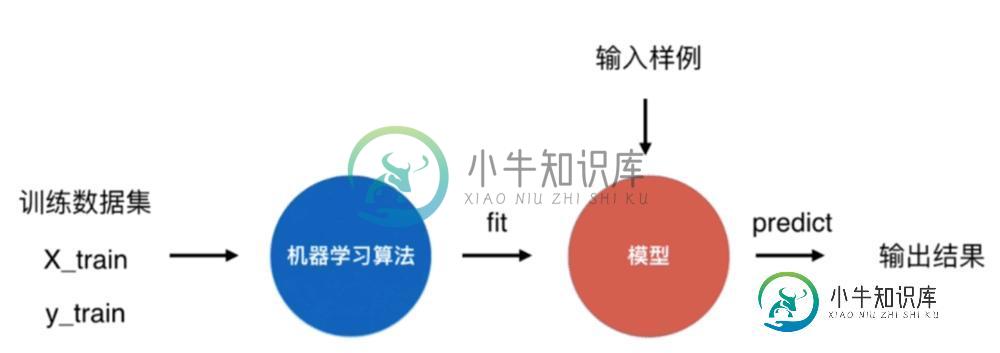 Python机器学习之scikit-learn库中KNN算法的封装与使用方法
Python机器学习之scikit-learn库中KNN算法的封装与使用方法本文向大家介绍Python机器学习之scikit-learn库中KNN算法的封装与使用方法,包括了Python机器学习之scikit-learn库中KNN算法的封装与使用方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python机器学习之scikit-learn库中KNN算法的封装与使用方法。分享给大家供大家参考,具体如下: 1、工具准备,python环境,pycharm 2、在机器
-
 使用python将列文本数据转换为用于机器学习的功能
使用python将列文本数据转换为用于机器学习的功能左侧CSV文件有五列列有几个应用程序类型,用
-
如何为一个机器学习模型解释损失和准确性[关闭]
当我用Theano或Tensorflow训练我的神经网络时,它们会每历元报告一个叫做“损失”的变量。 我该如何解释这个变量呢?更高的损耗是更好还是更差,或者这对我的神经网络的最终性能(准确性)意味着什么?
-
Azure机器学习工作室:无法从AzureSQL数据库创建数据存储
我正在尝试从 Azure 机器学习工作室内部连接到 Azure SQL 数据库。根据 https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.datastore.datastore?view=azure-ml-py,建议的模式似乎是使用Datastore.register_azure_sql_database方法创
-
随机/随机比较器
问题内容: 有没有什么方法可以模拟Collections.shuffle的行为,而比较器不容易受到排序算法实现的影响,从而确保结果安全? 我的意思是不违反可比合同等。 问题答案: 不打破合同就不可能实现真正的“改组比较器”。合同的一个基本方面是,结果是可 重现的, 因此必须确定特定实例的顺序。 当然,您可以使用混洗操作预先初始化该固定顺序,并创建一个比较器来精确地建立此顺序。例如 虽然没有意义。显
-
随机/随机比较器
是否有任何方法可以模拟Collections.shuffle的行为,而比较器不容易受到排序算法实现的影响,以确保结果安全? 我的意思是不违反类似的合同等..
-
是否可以将Python设置的无顺序视为随机顺序?
问题内容: 我想知道Python内置结构的元素排序是否不足够“随机”。例如,采用集合的迭代器,是否可以将其视为其元素的混合视图? (如果很重要,我将在Windows主机上运行Python 2.6.5。) 问题答案: 不,这 不是 随机的。它是“任意排序”的,这意味着您不能依赖于它是随机的还是随机的。
-
Vue.js学习之过滤器详解
本文向大家介绍Vue.js学习之过滤器详解,包括了Vue.js学习之过滤器详解的使用技巧和注意事项,需要的朋友参考一下 前言 在这个教程中,我们将会通过几个例子,了解和学习VueJs的过滤器。阅读这这篇文中的前提是你对Vue已经有了基本的语法基础。 Vue.Js中的过滤器基础 过滤器是一个通过输入数据,能够及时对数据进行处理并返回一个数据结果的简单函数。Vue有很多很便利的过滤器,可以参考官方文档
-
 顺丰-大数据挖掘与分析工程师-一二三面面经(oc)
顺丰-大数据挖掘与分析工程师-一二三面面经(oc)一面 简历面,如果过往实习项目由机器学习等,比较关心其中数据预处理和特征处理,没有问coding和模型延伸问题(八股) 二面 对于项目中涉及的某个优化算法特别感兴趣,深挖概念、流程、优点、公式等 (第一次也是目前唯一被问到这个细节,真的要对简历熟悉) 压力大的时候喜欢干什么 hr面 为什么想来深圳 深圳还投了哪些公司 十一前发意向 总体觉得顺丰的问题难度很看分配到的面试官,和身边同学交流,有的就会
-
HashMap:以随机顺序迭代键值对
问题内容: 我有一个HashMap,每次我获得迭代器时,我都希望以不同的随机顺序迭代它们的键值对。从概念上讲,我想在调用迭代器之前对地图进行“混洗”(或者,如果需要,可以对迭代器进行“混洗”)。 我有两种选择: 1)使用LinkedHashMap的方法,并在内部保留条目列表,将其随机洗净,并在调用迭代器时返回该视图。 2)使用map.entrySet(),构造一个ArrayList并在其上使用sh