《面试体验最好的公司》专题
-
 【面试经验分享】前瞻产业研究院实习生笔试
【面试经验分享】前瞻产业研究院实习生笔试时长:2h 形式:线下笔试 流程: 1. 到公司后有工作人员带领到达指定电脑前笔试 2. 笔试题目:对某一行业产出一份行业研究分析PPT -行业概念 -行业特点 -行业产业链情况 -行业未来发展规模 -行业公司等 3. 可以在网上搜集资料,就是时间非常紧张#爱思益##24秋招求职节奏总结##我的求职思考#
-
ImageJ固体的计算面积
我有一系列冰的图像,我想通过分析来确定固体和液体的面积。这里有一个示例图像。这类似于孔隙率测量,但由于颜色太相似,无法简单地进行阈值测量,因此我很难进行测量。 目前,我不得不玩弄对比/寻找边缘/去斑/制作二进制文件,以使晶体更容易识别。 然后我通过形态分割:例子和阈值来计算区域。 有没有更简单的方法来计算冰的面积和空间/液体的面积,而不必追踪每一个晶体?
-
spring boot不加载试验柑橘试验期间的特定应用特性
我正在尝试让spring boot在运行我的Citrus集成测试时自动加载文件,而不是文件。这些属性在测试期间是可用的,但它们不会覆盖在主spring boot应用程序内部使用的主要属性。 以下是我到目前为止的配置: src/main/Java/EventPublisher.Java src/main/resources/application.properti src/test/Java/end
-
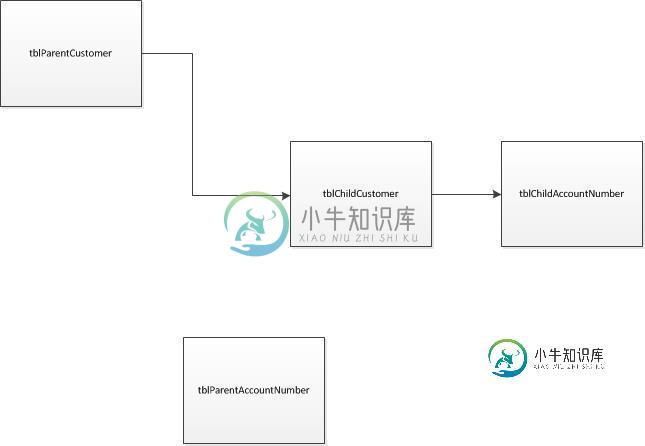 相似实体的最佳表关系设计
相似实体的最佳表关系设计我正在试图找出设置实体图的最佳方法。我将基于下面的图像进行解释。 TBLParentCustomer:此表存储主要客户的信息,主要客户可以是企业或消费者。(使用查找表TBLCustomerType标识这些客户。) TBLChildCustomer:此表存储主客户下的客户。主要业务客户可以有授权员工和授权代表,主要消费客户可以有授权用户。(它们是使用查找表TBLCustomerType标识的。) T
-
使用背包变体的最优MLB阵容
我正在写一个程序,以找到最好的MLB阵容使用背包解决方案。为此,我传入球员数据,其中有球员计算的价值和工资。就背包问题而言,工资将是我的“重量”。 我的问题不是能够选择球员,而是选择最优的阵容。我正在选择一个投手,一个中锋,一垒手,二垒手,三垒手,短停,和三个外野手。我可以成功地完成这一切。我希望我的“体重”是36000,但我目前只选择了一个总共21000的阵容。 我是在犯一个公然的错误,我只是没
-
Python中的“ public”或“ private”属性?什么是最好的方法?
问题内容: 在Python中,我有以下示例类: 如您所见,我有一个简单的“私有”属性“ _attr”和一个用于访问它的属性。有很多代码可以声明一个简单的私有属性,我认为这样声明所有属性并不符合“ KISS”哲学。 因此,如果我不需要特定的getter / setter / deleter,为什么不将我的所有属性都声明为公共属性呢? 我的回答是:因为封装原理(OOP)另有说明! 什么是最好的方法 ?
-
浅谈Vue开发人员的7个最好的VSCode扩展
本文向大家介绍浅谈Vue开发人员的7个最好的VSCode扩展,包括了浅谈Vue开发人员的7个最好的VSCode扩展的使用技巧和注意事项,需要的朋友参考一下 在Visual Studio中添加正确的VS Code扩展可以让你作为开发者的生活变得更加轻松。 它们可以帮助格式化、可伸缩性、强制执行最佳实践,从而自动化开发过程中许多容易忘记的任务。它们也可以只是有趣的扩展,使我们的代码看起来更漂亮/更容易
-
最好的方法来管理长期运行的PHP脚本?
问题内容: 我有一个需要很长时间(5-30分钟)才能完成的PHP脚本。以防万一,脚本正在使用curl从另一台服务器上刮取数据。这就是它花费这么长时间的原因。它必须等待每个页面加载,然后再处理并移至下一页。 我希望能够启动脚本并放任其完成,这将在数据库表中设置一个标志。 我需要知道的是如何能够在脚本完成运行之前结束http请求。另外,php脚本是做到这一点的最佳方法吗? 问题答案: 当然可以使用PH
-
 游戏业务数据指标体系面试题1
游戏业务数据指标体系面试题1面试高频题1: 题目:游戏业务中有哪些常用指标? 答案解析 比较关键的指标,流量相关的有用户量、用户转化率、留存率,内容相关的有用户在线时长、有效游戏时长,收入相关指标有用户付费率、LTV、ROI等。 面试高频题2: 题目:怎么制定游戏业务的目标 制定目标可以套用SMART原则 SMART是一个目标设定原则,能够帮助我们以及团队设置具体的、可衡量的、可实现的、相关的和有时间期限的目标,从而提高工作
-
 游戏业务数据指标体系面试题2
游戏业务数据指标体系面试题2面试高频题4: 题目:怎么衡量你在业务部门的贡献 业务部门是数据分析师分析所服务的相关方,包括产品、运营等 答案解析: 数据分析师比较像游戏中的辅助角色,也是非常关键的 所以,衡量标准为: 能否驱动业务提供方向和结论,并有明显业务效益的提升 能否理解业务并提供专业的意见,从而解决了业务方的一些难题 能否对业务充分理解,并能高效做出取数和数据报表等操作,提升业务方效率 拿日常工作详细举例: 比起零散
-
 电商业务数据指标体系面试题1
电商业务数据指标体系面试题1面试高频题1: 题目:电商业务中有哪些常用指标? 答案解析: 1、流量指标 (1)UV (2)PV (3)访问人数 (4)新访问占比 (5)实例数 (6)访问深度 (7)停留时间 (8)跳出率 (9)退出率 (10)产品页转化率 (11)加入购物车转化率 (12)结算转化率 (13)购物车内转化率 2、商品数据化运营指标 (1)订单量和商品销售量 (2)GMV (3)商品销售额和订单金额 (4)平
-
Spring靴驼峰试验
我正在用Spring boot为Camel编写一个测试。下面是测试类的配置 我认为骆驼不应该被启动。但当我运行测试时,它已经开始了。 我注意到CamelSpringBootRunner确实在CamelSpringBootExecutionListener中启动了camel上下文。 如何强制不启动骆驼上下文。
-
Spring靴骆驼试验
没有“org.apache.camel.CamelContext”类型的合格bean可用:应至少有一个合格的自带候选bean。 依赖项注释:{@org.SpringFramework.Beans.Factory.Annotation.AutoWired(required=true)}
-
火花速度试验
我通过连接到一个有500'000'000行和14列的数据库。 下面是使用的代码: 上面的代码花了9秒来显示DB的前20行。 后来,我创建了一个SQL临时视图 上面的代码用了1355.79秒(大约23分钟)。这样可以吗?这似乎是一个大量的时间。 最后,我尝试计算数据库的行数 用了2848.95秒(约48分钟)。 是我做错了什么,还是这些数额是标准的?
-
Spock/GEB试验污染
我受到了某种测试污染。当我单独运行失败测试时,它们会通过。当我把它们一起运行时,我会得到错误。这些错误与数据库无关。我不能理解错误。例如:页面: 我不明白,因为模块的内容不是必需的。另外,另一个测试的污染会导致这种情况吗?我的测试太多了,无法列出。 我唯一的想法是cookie被设置而不是由我的程序。有一堆cookie,它们具有奇怪的名称,如“ba743b”、“kvcd”、“kn_ai”等,并具有神