《华住酒店》专题
-
oracle执行update语句时卡住问题分析及解决办法
本文向大家介绍oracle执行update语句时卡住问题分析及解决办法,包括了oracle执行update语句时卡住问题分析及解决办法的使用技巧和注意事项,需要的朋友参考一下 问题 开发的时候debug到一条update的sql语句时程序就不动了,然后我就在plsql上试了一下,发现plsql一直在显示正在执行,等了好久也不出结果。但是奇怪的是执行其他的select语句却是可以执行的。 原因和解决
-
让复选框记住它的状态的最佳方法是什么?
我有一个使用许多复选框的javafx应用程序。选中复选框后,主窗口中将显示一个按钮。复选框设置为“false”将使按钮消失。很简单。 问题是复选框不记得它已被选中,并且应用程序总是以所选复选框开始,如fxml文件中定义的: 由于我在谷歌上找不到任何令人满意的东西,我想出了一个本土的解决方案,设置了一个函数,直接在fxml文档中将复选框的选定状态设置为“真”或“假”,效果非常好。 我只是想知道这是否
-
试图通过RMI进行通信时,在weblogic中卡住了线程
我们的应用程序运行在8节点Weblogic集群中,并尝试与RMI服务器通信。由于RMI服务器中的错误,执行此操作的线程被卡住。我们正试图解决这个问题,但问题是在那之前,卡住的线程会减慢应用程序的速度,最终导致整个集群瘫痪。 我的问题是‘我们如何从客户端确保线程被释放?’ 任何帮助都非常感谢。 实现细节:-Weblogic 10.0MP2,具有8个节点的集群-Java 1.5 线程转储代码段: 应用
-
抓住被抛弃的人是一种不好的习惯吗?[副本]
抓一次性的东西是一种不好的习惯吗?例如,我的代码是这样的。但在声纳中,它表现为虫子。我们如何解决这个问题
-
带有spring amqp的rabbitmq-消息在amqp异常情况下被卡住
我在我的消费者体内抛出一个AMQP异常。我的期望是,消息将以FIFO顺序返回队列,并在将来的某个时候重新处理。 Spring AMQP似乎没有将消息释放回队列。而是一次又一次地尝试重新处理失败的消息。这会阻止处理新到达的消息。卡在AMQP控制台内的设备将永远处于“未打包”状态。 有什么想法吗?
-
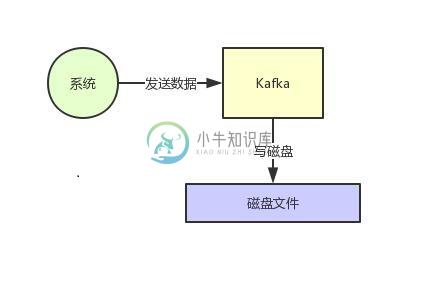 字节面试题: 如何让一个MQ抗住几十万并发?
字节面试题: 如何让一个MQ抗住几十万并发?主要内容:1、页缓存技术 + 磁盘顺序写,2、零拷贝技术,3、最后的总结这篇文章来聊一下Kafka的一些架构设计原理,这也是互联网公司面试时非常高频的技术考点。 Kafka是高吞吐低延迟的高并发、高性能的消息中间件,在大数据领域有极为广泛的运用。配置良好的Kafka集群甚至可以做到每秒几十万、上百万的超高并发写入。 那么Kafka到底是如何做到这么高的吞吐量和性能的呢?这篇文章我们来一点一点说一下。 1、页缓存技术 + 磁盘顺序写 首先Kafka每次接收到数据都会往磁
-
 字节住小帮用户运营实习生——一面面经分享
字节住小帮用户运营实习生——一面面经分享2月底到3月中旬,半个月海投了60+简历,面了11次,百度、字节、快手、小红书、蒙牛等都面了,有时候一天面三个(累)。主要方向是MKT或者运营(用户/电商/产品),打算在牛客依次写一下我面过的这些的面经,算是为暑实攒人品了。 面试: 1.讲一段最难忘的实习经历,描述难忘的原因、过程、你在其中的角色以及获得了什么样的成绩? 后续有一些追问,主要是对其中行动的动机进行逻辑上的追问 2.讲一下你对我们业
-
python - 今天被一个看似简单的df转字典难住了?
今天被一个看似简单的问题难住了,一个df,表头为['date','code','name','涨幅','换手率'], 希望转换成字典方便使用 dic.get(dt,[])返回的只有一行数据 发现不对,上面dic将表中数据只取了最后一行,df中date列有重复的,每个日期都有多行,期望dic.get(dt,[])返回二维列表(多行数据),用groupby好像解决不了这个问题,要遍历生成字典吗?
-
它允许用谷歌购买在华为商店发布应用?
我有应用程序,它在谷歌播放商店发布了一个工作不错。我想在华为商店发布这个应用。但在我的应用程序中,我有谷歌计费的应用程序内购买。华为允许在他们商店发布应用吗?还是我需要实施华为采购然后发布?
-
 【华为OD机试2023】字符串解密(Python)
【华为OD机试2023】字符串解密(Python)题目描述: 给定两个字符串string1和string2。 string1是一个被加扰的字符串。string1由小写英文字母('a'~'z')和数字字符('0'~'9')组成,而加扰字符串由'0'~'9'、'a'~'f'组成。string1里面可能包含0个或多个加扰子串,剩下可能有0个或多个有效子串,这些有效子串被加扰子串隔开。 string2是一个参考字符串,仅由小写英文字母('a'~'z')组
-
 【华为OD机试2023】租车骑绿道(Python)
【华为OD机试2023】租车骑绿道(Python)题目描述: 部门组织绿道骑行团建活动。租用公共双人自行车骑行,每辆自行车最多坐两人、做大载重M。 给出部门每个人的体重,请问最多需要租用多少双人自行车。 输入描述: 第一行两个数字m、n,自行车限重m,代表部门总人数n。 第二行,n个数字,代表每个人的体重。体重都小于等于自行车限重m。 0 < m <= 200 0 < n <= 1000000 输出描述: 最小需要的双人自行车数量。 示例1 输入
-
 【华为OD机试2023】学校的位置(Python)
【华为OD机试2023】学校的位置(Python)题目描述: 为了解决新学期学生暴涨的问题,小乐村要建所新学校。考虑到学生上学安全问题,需要所有学生家到学校距离最短。 假设学校和所有的学生家,走在一条直线上。 请问,学校要建在什么位置,能使得学校到各个学生家的距离之和最短? 输入描述: 输入的第一行是一个整数N(1<=N<=1000),表示有N户家庭。 输入的第二行是一个属组 (0<= <=10000),表示每户家庭的位置,所有家庭的位置都不相同
-
 【华为OD机试2023】贪心的商人(Python)
【华为OD机试2023】贪心的商人(Python)题目描述: 商人经营一家店铺,有number种商品,由于仓库限制每件商品的最大持有数量是item[index],每种商品的价格在每天是item_price[item_index][day],通过对商品的买进和卖出获取利润,请给出商人在days天内能获取到的最大的利润; 注: 同一件商品可以反复买进和卖出; 输入描述: 3 // 输入商品的数量 number 3 // 输入商人售货天数 days
-
 【华为OD机试2023】不含101的数(Python)
【华为OD机试2023】不含101的数(Python)题目描述: 小明在学习二进制时,发现了一类不含101的数,也就是: - 将数字用二进制表示,不能出现101。 现在给定一个正整数区间[l,r],请问这个区间内包含了多少个不含101的数? 输入描述: 输入的唯一一行包含两个正整数l,r(1<=l<r<=109)。 输出描述: 输出的唯一一行包含一个整数,表示在[l,r]区间内一共有几个不含101的数。 示例1 输入: 1 10 输出: 8 说明:
-
 【华为OD机试2023】最差产品奖(Python)
【华为OD机试2023】最差产品奖(Python)题目描述: A公司准备对他下面的N个产品评选最差奖,评选的方式是首先对每个产品进行评分,然后根据评分区间计算相邻几个产品中最差的产品。评选的标准是依次找到从当前产品开始前M个产品中最差的产品,请给出最差产品的评分序列。 输入描述: 第一行,数字M,表示评分区间的长度,取值范围是0<M<10000 第二行,产品的评分序列,比如[12,3,8,6,5],产品数量N范围是-10000<N<10000 输