《市场营销人求职交流聚集地》专题
-
集中式工作流
Centralized Workflow。项目的所有协作者把对项目的修改推送到统一的远程仓库,这就是集中式工作流。其它的 Git 工作流基本都是基于这种工作流程做了一些扩展。 项目的发起者在自己电脑上创建了一个本地仓库,他又为项目在远程创建了一个仓库,这个远程仓库就是所有协作者要把提交推送到的地方。这个远程仓库在谁家那创建都无所谓,可以用 Github,Coding.net,阿里云 Code,也可
-
监控集成流程
此章节针对于网聚宝业务监控集成流程作出说明。 主要内容包含: 添加依赖: 在 pom.xml 中引入 网聚宝监控客户端 的依赖。 dubbo.xml 配置: 在 dubbo 配置的 xml 文件下引入监控配置。 log4j 配置: 在 log4j.xml 中加入 监控的日志输出位置。 异常捕获方法调用: 在启动入口(main 函数)中加入方法调用。 (数据层)MyBatis plugin 配置:
-
两个或更多排序集的交集
问题内容: 我有两个排序集,并且想要进行交集,即。 关于效率,是否有比以下更好的方法: 问题答案: 您应该先使用ZCARD检查哪些元素较少,然后克隆并修剪较短的元素。 其次,您将剩下2个剩菜。您可以重复使用同一辅助程序,以加快清除速度。 我还想建议克隆使用DUMP和RESTORE,但是对于排序集的情况,ZUNIONSTORE实际上要快得多。这是一个100万个元素集的时间安排:
-
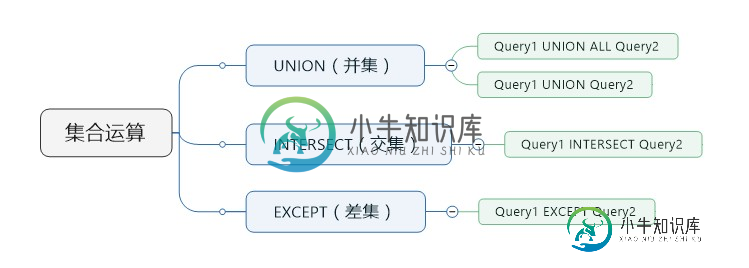 sql server 交集,差集的用法详解
sql server 交集,差集的用法详解本文向大家介绍sql server 交集,差集的用法详解,包括了sql server 交集,差集的用法详解的使用技巧和注意事项,需要的朋友参考一下 概述 为什么使用集合运算: 在集合运算中比联接查询和EXISTS/NOT EXISTS更方便。 并集运算(UNION) 并集:两个集合的并集是一个包含集合A和B中所有元素的集合。 在T-SQL中。UNION集合运算可以将两个输入查询的结果组合成一个
-
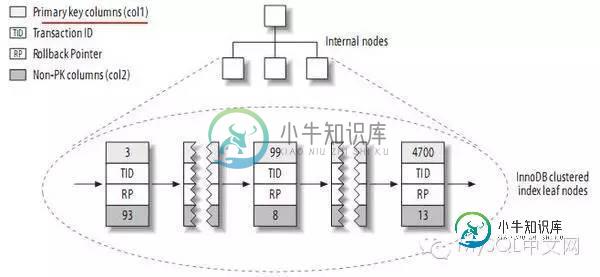 MySQL索引之聚集索引介绍
MySQL索引之聚集索引介绍本文向大家介绍MySQL索引之聚集索引介绍,包括了MySQL索引之聚集索引介绍的使用技巧和注意事项,需要的朋友参考一下 在MySQL里,聚集索引和非聚集索引分别是什么意思,有什么区别? 在MySQL中,InnoDB引擎表是(聚集)索引组织表(clustered index organize table),而MyISAM引擎表则是堆组织表(heap organize table)。 也有人把聚集索引
-
Microsoft Dynamics CRM唯一非聚集索引
我在工作中继承了一个Dynamics CRM系统,运行:Version1612(8.2.2.112)(DB 8.2.2.112)。 我们所处的情况是,重复似乎通过失败的表单提交断断续续地发生,随后又重新提交。我们已经在内部发布了一个文档,解释了这种行为,并表示首先检查部分或全部事务是否真正成功是多么重要。但人类终归是人类,常常忘记... 是否有更好的解决方案,我没有,提供数据库级的一致性,并不妨碍
-
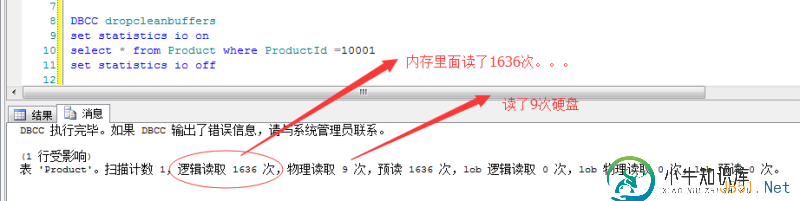 理解Sql Server中的聚集索引
理解Sql Server中的聚集索引本文向大家介绍理解Sql Server中的聚集索引,包括了理解Sql Server中的聚集索引的使用技巧和注意事项,需要的朋友参考一下 说到聚集索引,我想每个码农都明白,但是也有很多像我这样的猥程序员,只能用死记硬背来解决这个问题,什么表中只能建一个聚集索引,然后又扯到了目录查找来帮助读者记忆。。。。问题就在这里,我们不是学文科,,,不需要去死记硬背,,,我们需要的就是能看到在眼里面的真实东西
-
spring集成-拆分器和聚合器
目前,我正在与spring integration合作开发新的应用程序,并启动了poc,以了解如何处理故障案例。在我的应用程序中,spring integration将接收来自IBM mq的消息,并根据消息类型验证头信息和到不同队列的路由。传入的消息可能是批量消息,所以我使用了spring integration的拆分器和聚合器,并且对技术工作流程有很好的进展和控制。目前我面临的问题很少,我们有I
-
Mongodb聚合计数数组/集大小
{应用程序:“ABC”,日期:time.now,状态:“1”user_id:[id1,id2,id4]} {应用程序:“ABC”,日期:time.listerment,状态:“1”,user_id:[id1,id3,id5]} {应用程序:“ABC”,日期:time.ystayday-1,状态:“1”,user_id:[id1,id3,id5]} 我目前正在使用聚合框架并计算MongoDB之外的I
-
MySQL将列聚合为不同值集
我想将一列聚合为一组值。 让我们考虑以下模式 我需要这样的结果 我试着搜索一个集合聚合函数,但找不到任何有用的东西。
-
轴突再生聚集状态不清
null 我设置应用程序的方式是使用aggregateview将所需数据持久化到数据库中。因此,现在我感觉事件只是存储在事件存储区中,并且只在调用命令后用于重新创建聚合。对于正在存储的事件和集合的重新创建,我难道没有其他事情要做吗?例如,我是否应该重新创建整个聚合,而不是按ID从数据库中取出aggregateview来更新它。
-
MongoDB投影在@聚集Spring数据上
我已经为此挣扎了好几天了。我们刚刚开始与mongoDB合作,因此我对它的了解非常有限。 总之,我想做的是:我们有一个叫做Loan的课程,就像这样: 由于查询此集合时必须执行各种操作,因此我们在LoanRepository中创建了一个聚合(该聚合适用于我们在Mongo Compass中创建的,然后将其导出到我们的代码中): 这个想法是,在所有上述操作之后,我们只需要从整个Loans表中返回一些字段(
-
 欢聚集团平面设计面试
欢聚集团平面设计面试面的岗位是平面设计师 第一轮面试 感觉是hr在boss上初筛你的简历,正常来说会打电话问问你的基本情况 以后约面试时间(联系我的hr在boss跟我大概聊了会,就没有她打电话过来的情况, 直接加了她wx约的面试时间) 第二轮部门领导面 大概20分钟左右 视频面试(我自己开了摄像头) 1、自我介绍 2、问实习经历(简述你之前实习的工作内容) 3、介绍作品集里面你最满意的
-
 欢聚集团前端实习一面
欢聚集团前端实习一面面试时长(30min) 一、自我介绍 二、项目相关 1. 登录鉴权 2. 动态路由 3. token如何生成,如何做到持久化 4. 实习项目中封装了哪些组件 三、八股 1. 从浏览器地址栏输入 url 到请求返回发生了什么 2. 接上题,返回 HTTP 报文中包含哪些内容(不知道) 3. 浏览器缓存了解哪些 4. 强缓存中Expires有哪些参数 5. Cache-Control 中有哪些指令 四
-
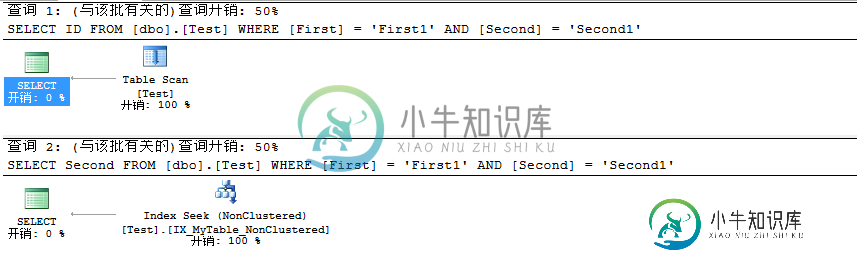 浅析SQL Server 聚焦索引对非聚集索引的影响
浅析SQL Server 聚焦索引对非聚集索引的影响本文向大家介绍浅析SQL Server 聚焦索引对非聚集索引的影响,包括了浅析SQL Server 聚焦索引对非聚集索引的影响的使用技巧和注意事项,需要的朋友参考一下 前言 在学习SQL 2012基础教程过程中会时不时穿插其他内容来进行讲解,相信看过SQL Server 2012 T-SQL基础教程的童鞋知道前面写的所有内容并非都是摘抄书上内容,如若是这样那将没有任何意义,学习的过程必须同时也是一