《市场营销人求职交流聚集地》专题
-
 秋招日记|快手海外销售运营面经
秋招日记|快手海外销售运营面经业务一面(32分钟) 1. 自我介绍 2. 主要经历涵盖了销售和销售运营,未来想往哪个方面的发展 3. 你认为你有哪些能力是适配销售运营的 4. 简单介绍下你所在京东业务部门 5. 介绍下你在京东的一天是如何度过的做了哪些事情 6. 介绍下你的优劣势 7. 我认为你的的劣势不是你的劣势,为什么你认为它是你的劣势呢 8. 深挖京东实习部分所有的经历 9. 具体讲讲一个项目 10. 你是如何做调研报告
-
 中国移动在线营销中心 web前端岗
中国移动在线营销中心 web前端岗很轻松的一次面试,面了25—28分钟。有三个面试官会进行提问。首先是自我介绍。然后就是第一个面试官对我专业知识的拷打,介绍闭包,然后哪些情况下使用闭包,学习前端的路线是什么,es5和es6,箭头函数的this(箭头函数没有this,....那个面试官故意说错,其实是希望我纠正),promise怎么捕捉错误,async awiat的作用,await有啥作用,巴拉巴拉一大堆。然后第二个面试官问我项目,
-
如何销毁应聘人员排队的工作?
问题内容: 我在rails-3项目上使用Resque来处理计划每5分钟运行一次的作业。我最近做了一些工作,使这些工作的创建雪上加霜,而堆栈已经击中了1000多个工作。我修复了导致许多作业排队的问题,现在我遇到的问题是由错误创建的作业仍然存在,因此由于将作业添加到具有1000多个作业的队列中,因此很难进行测试。我似乎无法停止这些工作。我尝试使用flushall命令从redis- cli中删除队列,但
-
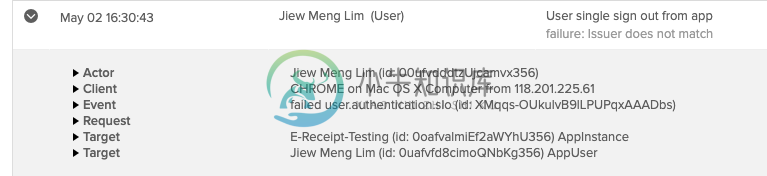 SAML注销失败:发行人不匹配(NodeJS Okta)
SAML注销失败:发行人不匹配(NodeJS Okta)我正在尝试用SAML注销,Okta是我的IdP。我在Okta日志中看到“发卡机构不匹配”: 我已经设置了单次注销: 上传的证书是我的SP公钥。 代码方面: 以及注销功能:
-
 字节抖音组商业化运营一面面经(已入职)
字节抖音组商业化运营一面面经(已入职)1.自我介绍🎓 大致介绍了自己的院校、专业,我结合了所招岗位JD来讲,过程中挑之前自己实习过程中和JD相符的点,全力证明自己和这个岗位的匹配度,全程大概2min 2.深挖简历 ✏️ 针对刚才的自我介绍,面试官反问问题,主要是反问和JD上相关的(所以提前了解岗位所需很重要),深挖之前的实习经历 ⚠️简历一定不能造假 面试官会问很细节的东西,比如拉新了多少人,有关项目的数据(如不知道就诚实的讲不知
-
 职优你教育科技公司用户运营一面面经
职优你教育科技公司用户运营一面面经这个岗是职优你教育科技公司的用户运营。一面是业务面,总体感觉比较轻松,可能是小公司要求不高吧,面试官比较开朗健谈、诚恳,出结果效率也比较高。 一面 1. 自我介绍#运营人求职交流聚集地# 具体问题: 1、自我介绍 自我介绍+兴趣爱好+两段相关实习经历+数据化表现 2、简单介绍一下简历实习项目经历 一端是文化传媒公司的3个月实习,主要负责运营账号 一段是个人去自媒体创作 3、针对一个实习项目讲一下自
-
 腾讯IEG光子 游戏运营 面试经验贴 (待入职)
腾讯IEG光子 游戏运营 面试经验贴 (待入职)背景:南京某211 23届毕业生 因为之前腾讯运营公开课的经历 收到过很多面试但是都凉凉 这次难得到了hr面 记录一下 攒个人品吧 流程: 一面 组长面(5.31):目前这么多面试都没有群面过,可能是公开课的原因。面试官人非常好,让我拆解了几个手游运营思路之后就开始介绍项目(一个海外发行的射击手游)。反问环节问到建议,面试官挺真诚的说了自己的职业发展过程,说了运营岗的优点。 二面 主管面?(6.
-
本地上的交叉源请求
我正在尝试一些非常简单的方法,但由于某些原因它不起作用: 启动index.html时出现的错误: 无法加载文件:///e:/dev/eclipse/syrilab/pages/header.html:跨源请求仅支持协议方案:http、data、chrome、chrome-extension、HTTPS。 无法加载文件:///e:/dev/eclipse/syrilab/pages/home.htm
-
JSON字符串的交集
问题内容: 我正在尝试找到一种方法来将一个JSON字符串用作各种“模板”以应用于另一个JSON字符串。例如,如果我的模板如下所示: 然后将其应用于以下JSON字符串: 我想要如下所示的结果JSON字符串: 不幸的是,我既不能依赖模板也不可以是固定格式的输入,因此我无法编组/解组到已定义的接口中。 我已经编写了一个遍历模板的递归函数,以构造一个带有每个要包含的节点名称的字符串切片。 我称这个函数如下
-
Elasticsearch日期范围交集
问题内容: 我在elasticsearch中存储以下信息: 假设我还有另一个日期范围(例如,从用户输入中得出),我想搜索一个相交的时间范围。与此类似:确定两个日期范围是否重叠这概述了以下逻辑: 但是我不确定如何将其放入elasticsearch查询中,我会使用范围过滤器并且仅将“ to”值设置为,而将from留为空白吗?还是有一种更有效的方法? 问题答案: 更新:现在可以使用在elasticsea
-
MongoDB中的数组交集
好吧,这里有几件事。。我有两个集合:test和test1。这两个集合中的文档都有一个数组字段(分别是tags和tags1),其中包含一些标记。我需要找到这些标记的交叉点,如果单个标记匹配,还需要从集合test1获取整个文档。 令人惊讶的是,这并没有返回任何结果。但是,当我尝试使用单个文档时,它是有效的: 但这是我需要的一部分。我也需要交集。所以我尝试了这个: 但它只返回“a”,而“a”和“b”都在
-
Hadoop 集成 - spark streaming交互
Apache Spark 是一个高性能集群计算框架,其中 Spark Streaming 作为实时批处理组件,因为其简单易上手的特性深受喜爱。在 es-hadoop 2.1.0 版本之后,也新增了对 Spark 的支持,使得结合 ES 和 Spark 成为可能。 目前最新版本的 es-hadoop 是 2.1.0-Beta4。安装如下: wget http://d3kbcqa49mib13.clo
-
similarity - 获取数组交集
返回存在于两个数组中的元素数组。 使用 Array.filter() 移除不在 values 中的值,使用 Array.includes() 确定。 const similarity = (arr, values) => arr.filter(v => values.includes(v)); similarity([1, 2, 3], [1, 2, 4]); // [1,2]
-
Java流收集到Map
我使用的是java 11,我有一个名为MyObject的对象列表,看起来像这样 我想使用流将这些对象收集到地图中 我试着用收集器来做。toMap(),但似乎不可能做到这一点 我的问题是可以制作一张地图吗
-
收集的实施。流()
我已经在JDK 1.8上工作了几天,遇到了一些类似的代码: 现在,对于一直在使用流()的人来说,它可能看起来既简单又干净,但我找不到实现方法的实际类。 当我说列表时,我有以下问题。流(): 我从哪里获取? 他们是如何在不实际“干扰”现有集合的情况下实现它的?(假设他们没有接触它们) 我确实试着浏览了java的文档。util。AbstractCollection和java。util。Abstract