《市场营销人求职交流聚集地》专题
-
 深圳市城市交通规划设计研究中心(前端一面——HR面10分钟)
深圳市城市交通规划设计研究中心(前端一面——HR面10分钟)1.自我介绍 2.校内情况,学习情况,考研考公,成绩 3.谈过对象吗? 4.其他一些家庭情况 5.职业规划 HR知道我是22届投23校招。可能有点意外,估计我没了 #2022届毕业生现状##秋招##面经##面试##校招#
-
 乐有家 职能高储(业务运营岗 ) 群面经历
乐有家 职能高储(业务运营岗 ) 群面经历当时投这家公司其实抱着试着玩玩的心态,因为觉得二手房这个市场鱼龙混杂,我可能进去会被玩死,所以一开始根本没想过进地产。后来秋招投不下去了,在APP上随意投了一个乐有家,没想到HR小姐姐非常努力地给我打了两个电话发了短信,让我加微信,想着见见世面,就接着进行了流程。 总共四个人,都是职能岗,但不是同一个岗位,面试进行了两个小时。一开始是自我介绍环节,然后是问答环节。 问答环节是先是一对一的进行问答(
-
如何销毁应聘人员排队的工作?
问题内容: 我在rails-3项目上使用Resque来处理计划每5分钟运行一次的作业。我最近做了一些工作,使这些工作的创建雪上加霜,而堆栈已经击中了1000多个工作。我修复了导致许多作业排队的问题,现在我遇到的问题是由错误创建的作业仍然存在,因此由于将作业添加到具有1000多个作业的队列中,因此很难进行测试。我似乎无法停止这些工作。我尝试使用flushall命令从redis- cli中删除队列,但
-
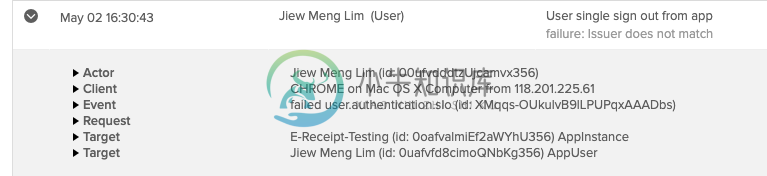 SAML注销失败:发行人不匹配(NodeJS Okta)
SAML注销失败:发行人不匹配(NodeJS Okta)我正在尝试用SAML注销,Okta是我的IdP。我在Okta日志中看到“发卡机构不匹配”: 我已经设置了单次注销: 上传的证书是我的SP公钥。 代码方面: 以及注销功能:
-
采集帮助 - 了解采集 - 采集流程
采集流程: 采集一般可以分为3个过程:1.设置采集规则;2.采集数据内容;3.导出内容,这3个内容是可以独立分开来的。 设置采集规则:这个就是在操作中的添加采集节点,并对这个节点规则进行设置,比如:设置采集内容列表的地址、指定采集标题或者内容的位置(规则)、设置采集内容过滤规则。这个规则是采集最根本最基础的东西,采集规则可以导入导出,方便对这个采集规则进行分享。 采集数据内容:根据不同情况对数据采
-
如果现在让你来设计一款更受人欢迎的社交游戏,你会进行怎样的设计?以真实的社交游戏市场来分析,你可以自行组织描述结构,例如市场状况与对手分析、产品设计要点等均可描述。
本文向大家介绍如果现在让你来设计一款更受人欢迎的社交游戏,你会进行怎样的设计?以真实的社交游戏市场来分析,你可以自行组织描述结构,例如市场状况与对手分析、产品设计要点等均可描述。相关面试题,主要包含被问及如果现在让你来设计一款更受人欢迎的社交游戏,你会进行怎样的设计?以真实的社交游戏市场来分析,你可以自行组织描述结构,例如市场状况与对手分析、产品设计要点等均可描述。时的应答技巧和注意事项,需要的朋
-
JSON字符串的交集
问题内容: 我正在尝试找到一种方法来将一个JSON字符串用作各种“模板”以应用于另一个JSON字符串。例如,如果我的模板如下所示: 然后将其应用于以下JSON字符串: 我想要如下所示的结果JSON字符串: 不幸的是,我既不能依赖模板也不可以是固定格式的输入,因此我无法编组/解组到已定义的接口中。 我已经编写了一个遍历模板的递归函数,以构造一个带有每个要包含的节点名称的字符串切片。 我称这个函数如下
-
Elasticsearch日期范围交集
问题内容: 我在elasticsearch中存储以下信息: 假设我还有另一个日期范围(例如,从用户输入中得出),我想搜索一个相交的时间范围。与此类似:确定两个日期范围是否重叠这概述了以下逻辑: 但是我不确定如何将其放入elasticsearch查询中,我会使用范围过滤器并且仅将“ to”值设置为,而将from留为空白吗?还是有一种更有效的方法? 问题答案: 更新:现在可以使用在elasticsea
-
MongoDB中的数组交集
好吧,这里有几件事。。我有两个集合:test和test1。这两个集合中的文档都有一个数组字段(分别是tags和tags1),其中包含一些标记。我需要找到这些标记的交叉点,如果单个标记匹配,还需要从集合test1获取整个文档。 令人惊讶的是,这并没有返回任何结果。但是,当我尝试使用单个文档时,它是有效的: 但这是我需要的一部分。我也需要交集。所以我尝试了这个: 但它只返回“a”,而“a”和“b”都在
-
Hadoop 集成 - spark streaming交互
Apache Spark 是一个高性能集群计算框架,其中 Spark Streaming 作为实时批处理组件,因为其简单易上手的特性深受喜爱。在 es-hadoop 2.1.0 版本之后,也新增了对 Spark 的支持,使得结合 ES 和 Spark 成为可能。 目前最新版本的 es-hadoop 是 2.1.0-Beta4。安装如下: wget http://d3kbcqa49mib13.clo
-
similarity - 获取数组交集
返回存在于两个数组中的元素数组。 使用 Array.filter() 移除不在 values 中的值,使用 Array.includes() 确定。 const similarity = (arr, values) => arr.filter(v => values.includes(v)); similarity([1, 2, 3], [1, 2, 4]); // [1,2]
-
Java流收集到Map
我使用的是java 11,我有一个名为MyObject的对象列表,看起来像这样 我想使用流将这些对象收集到地图中 我试着用收集器来做。toMap(),但似乎不可能做到这一点 我的问题是可以制作一张地图吗
-
收集的实施。流()
我已经在JDK 1.8上工作了几天,遇到了一些类似的代码: 现在,对于一直在使用流()的人来说,它可能看起来既简单又干净,但我找不到实现方法的实际类。 当我说列表时,我有以下问题。流(): 我从哪里获取? 他们是如何在不实际“干扰”现有集合的情况下实现它的?(假设他们没有接触它们) 我确实试着浏览了java的文档。util。AbstractCollection和java。util。Abstract
-
集中式工作流
Centralized Workflow。项目的所有协作者把对项目的修改推送到统一的远程仓库,这就是集中式工作流。其它的 Git 工作流基本都是基于这种工作流程做了一些扩展。 项目的发起者在自己电脑上创建了一个本地仓库,他又为项目在远程创建了一个仓库,这个远程仓库就是所有协作者要把提交推送到的地方。这个远程仓库在谁家那创建都无所谓,可以用 Github,Coding.net,阿里云 Code,也可
-
监控集成流程
此章节针对于网聚宝业务监控集成流程作出说明。 主要内容包含: 添加依赖: 在 pom.xml 中引入 网聚宝监控客户端 的依赖。 dubbo.xml 配置: 在 dubbo 配置的 xml 文件下引入监控配置。 log4j 配置: 在 log4j.xml 中加入 监控的日志输出位置。 异常捕获方法调用: 在启动入口(main 函数)中加入方法调用。 (数据层)MyBatis plugin 配置: