《群面攻略》专题
-
基于 Akka 集群的微服务 API 网关模式实现
我尝试基于Akka创建一些使用CQRS的微服务。所以我的微服务有Httpendpoint的写端(向集群发送命令)和读端(从数据库读取投影),但这不是主要问题。由于许多微服务,问题出现了为客户端收集复杂的API。我找到了答案:API网关模式。但我还有下一个问题:如何实现它? > < li> 我可以创建单独的项目,该项目将实现API网关模式(在简单的情况下,它是一个反向代理)。完整堆栈将: 赞成的意见
-
Cassandra集群的插入性能和插入稳定性较差
我必须为每个客户端每秒存储大约250个数值,即每小时大约90万个数字。它可能不会是全天的记录(可能每天5-10个小时),但我会根据客户端ID和读取日期对数据进行分区。最大行长约为22-23M,这仍然是可管理的。无论如何,我的方案看起来像这样: 密钥空间的复制因子为2,仅用于测试,告密者为和。我知道复制因子3更符合生产标准。 接下来,我在公司服务器上创建了一个小型集群,三台裸机虚拟化机器,具有2个C
-
集群创建HdInsight和核心辞职。调整apache spark提交
我想使用Spark处理Azure Hd Insight群集中的250gb gzip(filename.json.gzip)文件。但我做不到。 我猜是因为内核、ram和vCPU之间的关系不好,所以我想知道要创建的更好的集群和要发送的Spark配置。 目前我正在使用此实例: 集群E8a v4的6个节点(8核,64 GB RAM) 我的Spark配置是: < li >驱动程序内存:10Gb < li >
-
spark集群的性能因添加更多节点而降低
我有一个由1B记录组成的大型数据集,由于Apache spark提供的可扩展性,我想使用它运行分析,但我在这里看到了一个反模式。我向spark集群添加的节点越多,完成时间就越长。数据存储是Cassandra,查询由Zeppelin运行。我尝试过许多不同的查询,但甚至是对<code>数据帧的简单查询。count()的行为如下。 这是齐柏林飞艇笔记本临时表有18M记录 当针对不同数量进行测试时。这些是
-
Quartz不延迟已在群集环境中启动的作业
我有在集群中运行,并且我得到定期运行的作业。该作业在一台计算机中启动,其他计算机将保持到下一个执行时间。 我现在想要的是,如果前一次调用还没有完成,则延迟作业调用。例如: 即使这样也是可以接受的: 我使用了类似触发器的cron表达式,它每10分钟触发一次()。
-
如何建立VPN隧道连接到kubernetes集群外的eureka
我在kubernetes集群上部署了spring boot微服务。在集群之外,AWS上有netflix eureka发现服务。我想在这个eureka上注册我的服务。网关也在AWS上。在我的本地机器上,我需要通过openvpn创建vpn连接以访问eureka,Kubernetes群集也在aws之外,需要vpn。我有*。ovpn,我想我必须在kubernetes上创建一些vpn隧道,但我不知道合适的工
-
Spring Cloud数据流:任务无法在Kubernetes集群上启动
我已经在本地Kubernetes集群上部署了Spring Cloud Data Flow server。看起来一切都很好。然后创建一个类型的应用程序,提供Spring-Boot jar的URL。然后我创建一个任务“定义”并启动它。任务定义挂起状态为“正在启动”。 以下是我的发现: > 查看Kubernetes,我看到与正确创建但未能启动的任务对应的a pod,状态为 此pod配置有,日志显示消息:
-
Windows 10上的Minikube,Hyper-V卡在“启动群集组件”上
我正在Windows 10上使用迷你库贝,并尝试使用Hyper-V启动它。因为我在公司代理后面,并使用 CNTLM 来避免身份验证。我添加了http_proxy,并将https_proxy为docker env。 输出如下: 启动本地库伯内特斯v1.10.0集群… 启动VM… 获取VM IP地址… 将文件移动到集群… 设置证书… 连接到集群… 设置kubeconfig… 启动集群组件… 在最后一步
-
如何在K8s集群中获取可用资源(内存、cpu)?
我想知道我正在使用的整个K8s集群中有哪些可用资源。 明确地说,我不是在谈论资源配额,因为它们只定义每个名称空间的资源。我想知道整个集群的功能是什么(内存、cpu等等)。请注意,所有资源配额的总和并不等于集群的能力。与集群的资源相比,总和可以更大(为名称空间之间的资源创建竞争条件)或更小(集群未充分利用其潜力)。 我能用kubectl回答这个问题吗?
-
如何在ha kubeadm Kubernetes集群中使用本地docker镜像
在网上搜索如何在kubernetes中部署本地构建的docker映像,我只找到了与minikube结合的解决方案。 例如:minikube 因此,我想知道,是否可以在由建立的Kubernetes集群中使用本地构建docker镜像,或者是将这些镜像部署到私有注册中心并随后从集群中提取镜像的首选方法?
-
如何在AnyLogic中定义一群代理的特定代理?
我有一群“乘客”代理人,其中每一个代理人都会向另一个“机场”代理人发出请求(“OrderPassenger”代理人类型)。此时,“机场”代理人必须通过“机场建议”代理人响应请求,并将其发送给“乘客”群体中的特定“乘客”。 我尝试使用:send(airportSuggestion,main.passengers(orderPassenger.passenger));但是乘客。乘客不是整数类型。 我尝
-
boot2docker中Docker中的Hazelcast“提取群集分区表时出错”
我的设置:运行在boot2docker vm中的Hazelcast docker容器(托管在windows上,是的,端口5701被转发)。这是榛子3.4.2。 当我尝试将一个简单的java客户端连接到这个hazelcast实例时,我得到一个: 总而言之:客户机似乎看到了集群及其成员,但接下来发生的事情阻止了连接按预期工作。 知道吗?
-
Spark集群上sqlContext.read...load()和sqlContext.write...save()代码在哪里运行?
我使用Spark Dataframe API从NFS共享加载/读取文件,然后将该文件的数据保存/写入HDFS。 1)整个代码在哪里运行?它是在驱动程序上运行?还是同时使用两个worker? 2)load()和save()API是否在worker节点上运行,它是否并行工作?如果是,那么两个worker如何跟踪while的读写部分? 3)到现在为止,我在“for”循环中顺序地读取每个文件,并顺序地处理
-
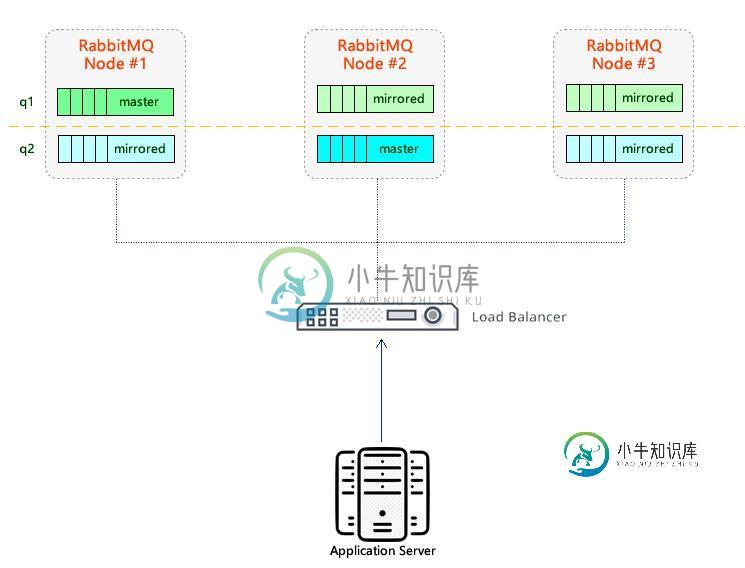 RabbitMQ集群可以被应用程序用作单个endpoint吗?
RabbitMQ集群可以被应用程序用作单个endpoint吗?RabbitMQ集群中有三个节点,如下所示。 在RabbitMQ中,有两个队列,和。 和的主副本分布在不同的节点上。这两个队列都由其他节点镜像。 三个节点前面有一个负载均衡器。 负载均衡器公开AMQP(节点端口5672)和管理HTTP API(节点端口15672)。 当应用程序通过负载均衡器建立连接时,可以到达后面随机的RabbitMQ节点。而这对于应用程序来说是不可见的。 问题:
-
ActiveMQ Artemis中的筛选。在群集中重新加载配置
关于ActiveMQ Artemis中筛选的一个问题。 在broker.xml中的标记下 当我阅读手册时,更改broker.xml时,现在应该每5秒在broker.xml中重新配置一次。 但当我将过滤器更改为