
RabbitMQ集群可以被应用程序用作单个endpoint吗?

- RabbitMQ集群中有三个节点,如下所示。
- 在RabbitMQ中,有两个队列,
Q1和Q2。 Q1和Q2的主副本分布在不同的节点上。这两个队列都由其他节点镜像。- 三个节点前面有一个负载均衡器。
- 负载均衡器公开AMQP(节点端口5672)和管理HTTP API(节点端口15672)。
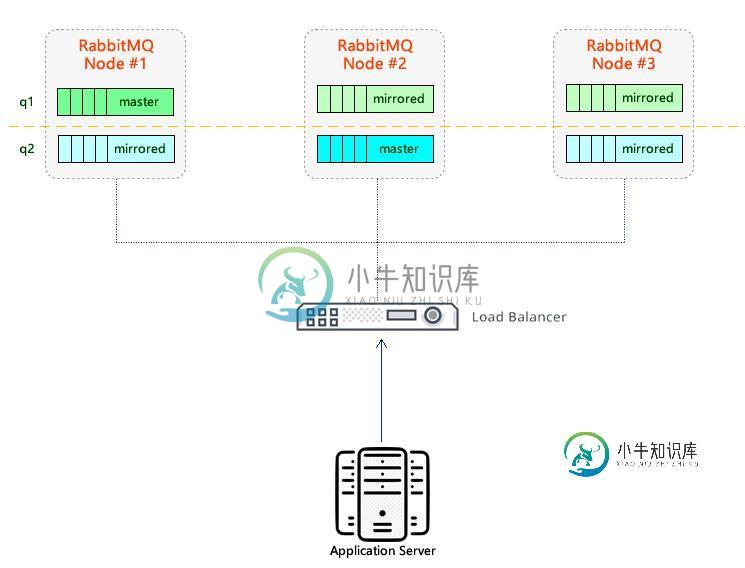
当应用程序通过负载均衡器建立连接时,可以到达后面随机的RabbitMQ节点。而这对于应用程序来说是不可见的。
问题:
共有1个答案

当RabbitMQ被设置为集群并且您的队列被镜像到它们之间时,连接到哪个节点并不重要。因为队列的AMQP连接将自动路由到包含主队列的节点,这由RabbitMQ在内部处理。因此,如果发布或使用队列Q1的请求来了,它将被路由到节点#1。
你问题的答案。
>
在单个AMQP连接中消耗多个队列是不可取的。一个消费进程的异常可能导致连接关闭,从而中断另一个。
-
我们的prod环境架构决定如下:2台机器,每台机器有2个tomcat实例(在vm上)。tomcat上有运行hibernate的spring web应用程序。还有2个db实例分布到这两台机器上。 因此,我们认为hazelcast非常适合这种结构。hazelcast将是hibernate的二级缓存,它将通过db实例管理集群缓存。 我们安装了hibernate服务器并在其上定义了集群。我已经搜索了官方的
-
对于一个幼稚的开发人员来说,他们似乎可以发布到集群中的任何节点,并从这些节点消费,这会给他们一种高可用性的错误感觉。 如果承载队列的节点死亡,使用者将不再能够从另一个节点到达队列。 是否有一种方法可以禁用这种行为,这样就可以很明显地看到,您要么必须有一个镜像队列,要么需要在每台服务器上创建一个不同的队列,从这两个服务器中使用,然后处理重复的队列。 谢谢
-
本文向大家介绍RabbitMQ 集群有什么用?相关面试题,主要包含被问及RabbitMQ 集群有什么用?时的应答技巧和注意事项,需要的朋友参考一下 集群主要有以下两个用途: 高可用:某个服务器出现问题,整个 RabbitMQ 还可以继续使用; 高容量:集群可以承载更多的消息量。
-
如果我使用带有2个读取副本的AWS Aurora MYSQL数据库,我需要使用不同的连接字符串进行读写,还是由集群endpoint为我路由流量?如果是这样的话,对于一个写得更少的应用程序来说,让读副本成为比主副本更大的实例(更强大)是否明智,因为它几乎不会被使用? 提前道谢。
-
我在我的kubernetes集群上部署了RabbitMQ服务器,我能够从浏览器访问管理用户界面。但是我的Spring启动应用程序无法连接到端口5672,我收到连接拒绝错误。如果我将我的application.yml属性从kuberntes主机替换为localhost并在我的机器上运行docker映像,同样的代码也可以工作。我不确定我做错了什么? 有人试过这种设置吗?请帮帮忙。谢谢!
-
问题内容: 我有一个棘手的情况:我正在构建一个完整的流星功能的应用程序。但是出于自动化原因,我还需要将某些功能公开为REST服务(第三方应用程序应该能够通过REST插入和接收数据)。 express.js-package似乎是将REST- Endpoint构建到node.js环境中的一个非常可靠的选择,但是我想知道如何将该终结点集成到流星中。 我想要的是例如通过来访问“常规”站点,同时又能够通过来