《群面攻略》专题
-
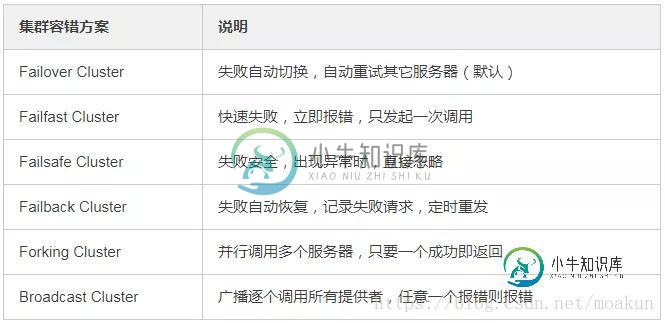 Dubbo有哪几种集群容错方案,默认是哪种?
Dubbo有哪几种集群容错方案,默认是哪种?本文向大家介绍Dubbo有哪几种集群容错方案,默认是哪种?相关面试题,主要包含被问及Dubbo有哪几种集群容错方案,默认是哪种?时的应答技巧和注意事项,需要的朋友参考一下 Failover Cluster 失败自动切换,当出现失败,重试其它服务器。通常用于读操作,但重试会带来更长延迟。 Failfast Cluster 快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录
-
为Flink集群中的插件添加自定义依赖项
我有一个Flink会话集群(作业管理器任务管理器),版本1.11.1,配置了log4j控制台。属性包括Kafka appender。此外,在作业管理器和任务管理器中,我都启用了flink-s3-fs-hadoop内置插件。 我已经将kafka客户端jar添加到flink/lib目录,这是容器运行所必需的。但在实例化S3插件(并初始化记录器)时,我仍然会遇到类下加载错误。 原因:org.apache
-
在AWS-ECS的新集群上获取"资源:内存"错误
我在AWS上使用ecs-cli设置了一个带新集群,命令如下: 配置群集:ecs cli配置--群集群集名称--区域名称--默认启动类型EC2--配置名称配置名称 使用默认配置文件:ecs cli配置默认--配置名称配置名称 创建群集:ecs-cli up--key对key_name--ablece-iam--size 1实例类型t2.micro安全组sg_id--vpcvpc_id子网subnet
-
自动部署。Kubernetes集群中Payara满吊舱的war应用
正如标题所说,我需要自动部署运行在Payara-FullPod上的应用程序。 目前,我已经手动部署了。通过在Pod内复制war文件(通过命令),然后通过
-
Kubeadm加入失败。我的主群集IP是192.168.0.9还是10.96.0.1?
当我运行kubeadm令牌create-print-join-command时,我得到以下信息: “Kubeadm join 192.168.0.9:6443--令牌FF9EGA.4AD2Z5YN2GICFVMC--发现-令牌-CA-证书-哈希SHA256:66884E1573B3AA1644BA5C724A53703D2C497F9C0E9131325866057937E8C154” 在节点上运
-
Zeppelin+Spark+Kubernetes:让Zeppelin作业在现有Spark集群上运行
在k8s集群中。如何配置zeppelin在现有spark集群中运行spark作业,而不是旋转一个新的Pod? 我有一个k8s集群正在运行,我想在其中运行与齐柏林飞艇的火花。 Spark使用官方的Bitnami/Spark helm chart(v3.0.0)进行部署。我有一个主舱和两个工人舱运转良好,一切都很好。 短伪DockerFile: 我稍微修改了。(Image,imagePullSecre
-
如何配置kubectl以与minikube和部署的集群交互?
当您使用minikube时,它会自动创建本地配置,因此可以随时使用。并且根据kubectl配置的引用,在kubectl命令中似乎支持多个集群。 环境变量似乎可以引用这些配置文件的多个位置,内置默认值为(这是minikube创建的)。 如果我希望能够使用kubectl调用多个集群的命令,我是否应该将相关的配置文件下载到一个新的位置(例如,下载到,将环境变量设置为引用这两个位置? 还是在调用kubec
-
配置kubectl命令以访问azure上的远程kubernetes集群
我有一个在Azure上运行的kubernetes集群。从本地kubectl命令访问集群的方式是什么。我在这里提到过,但是在kubernetes主节点上没有kube配置文件。此外,kubectl配置视图在
-
 使用Spring引导数据redis连接到redis集群问题
使用Spring引导数据redis连接到redis集群问题我使用spring boot data redis连接到redis群集,使用版本2.1.3,配置如下: 但是,在操作过程中,始终会收到警告异常消息,如下所示: 这似乎是莴苣的问题,如何映射远程主机
-
在本地机器上设置多代理集群时出错
在Ubuntu上使用Kafka:Zookeeper启动Kafka启动主题创建生产者启动消费者启动消息在生产者和消费者之间传递良好 我创建了2个新的server.properties文件:server-1.properties: 服务器-2。属性为: 当我开始新经纪人时: 错误为:
-
如何将Apache Ignite瘦客户端连接到Apache Ignite集群?
我有一个正在运行的Ignite集群,并且我使用进行节点发现: 它工作得很好,我可以使用节点连接到这个集群。 null
-
如何基于String的值对节点集群进行分片?
我想创建一个分布式系统,其中数据在所有节点上分片。我知道有像Hazelcast或Apache Ignite这样的库为您做这些工作。在我的例子中,对于每个分片密钥,我需要创建一个到另一个系统的套接字订阅,所以这不仅仅是关于如何分发数据,还包括如何以分布式的方式实际创建这些订阅。 其思想是为每个分片密钥创建对另一个系统的订阅。每个订阅都将保留一个条目列表,其中包含用于检查来自套接字连接的每个更新的数据
-
配置ElasticSearch Magento 2.4-在集群中找不到活动节点
尝试在magento 2.4中搜索产品时返回以下错误 异常#0(Elasticsearch\Common\Exceptions\NoNodes可用性异常):在集群中找不到活动节点 以下配置: PHP 7.4.1 Nginx 1.14 MySql 8 ElasticSearch 7.9 /etc/nginx/conf.d/100-magento2.conf /etc/nginx/conf.d/90-
-
服务Fabric群集。Statefull服务。服务总线队列使用
-
如何在Spark独立集群模式下访问HDFS文件?
抛出错误 到目前为止,我在Hadoop中只有start-dfs.sh,在Spark中并没有真正配置任何内容。我是否需要使用YARN集群管理器来运行Spark,以便Spark和Hadoop使用相同的集群管理器,从而可以访问HDFS文件? 我尝试按照tutorialspoint https://www.tutorialspoint.com/Hadoop/hadoop_enviornment_setup