《群面攻略》专题
-
使用SStableloader从不同的Cassandra集群加载Cassandra数据
我有两台运行Cassandra的不同独立机器,我想将数据从一台机器迁移到另一台机器。 因此,根据数据税文档,我首先在机器1上拍摄了我的Cassandra集群的快照。 然后,我将数据移动到计算机 2,在那里我尝试使用 sstableloader 导入它。 注意:机器2上的keypsace(open_weather)和tablename(raw_weather_data)已创建,并且与机器1上的相同。
-
Cassandra集群特定节点特定表高下降突变
我在生产中的压缩策略是LZ4压缩。但我将其修改为Deflate 对于压缩更改,我们必须使用nodetool升级表来强制升级所有表上的压缩策略 但是,一旦在集群中的所有5个节点上完成升级命令,我的请求开始失败,包括读取和写入 问题被追踪到5个节点集群中的一个特定节点以及该节点上的一个特殊表。我的整个集群具有大致相同数量的数据和配置,但有一个节点特别出现故障是行为不端的 < code >节点工具状态的
-
告诉Datastax Java Cassandra驱动程序超时群集连接
当Datastax Java Cassandra驱动程序试图连接到您的集群时,如何让它超时? 我特别感兴趣的是当主机可以访问,但Cassandra端口被阻塞或Cassandr守护进程未运行时的情况。我正在编写一个命令行客户端,如果它不能在合理的时间内连接,它应该退出并报告适当的错误消息。目前,如果接触点可以到达,驾驶员似乎会永远等待接触点的响应。 也就是说,如果驱动程序在给定的最长时间内无法与任何
-
在集群环境中每天运行Quartz调度程序
要求是定期运行一个Java应用程序(例如每天),向客户发送电子邮件/短信通知。环境是集群/高可用性,其中多个节点将同时处于活动状态。该应用程序将部署在所有节点上,但只有一个节点应该启动并运行,即使所有节点都配置为运行。如何实现这一点。在Java应用中,使用了石英调度器。 还需要一些关于如何在Linux机器上部署这个Java应用程序的指导(像Cron作业或其他一些方式)。要求是,这个应用程序应该在服
-
如何在Akka集群中透明地创建参与者
我有一个演员系统,如下图所示。 主演员启动监控演员和监控演员。 Monitor actor会发出一条消息,告诉自己每30秒检查一次设备资源清册。对于资源清册中存在的每个设备,它会向Supervisor actor发送一条消息以注册该设备。 主管参与者在收到来自监视器参与者的消息以注册设备时启动设备参与者。 代码可以在github上找到。 在单个JVM实例中,一切都运行得很好,但当涉及到集群模式时,
-
如何配置redis集群时使用sping-data-redis 1.7.0.M1
我使用spring data redis 1.7.0版。M1和绝地2.8.0版这是我的配置 并使用[redisTemplate.opsForValue().get(“foo”)进行测试 抛出异常 使用spring data redis 1.7.0时如何配置redis群集。M1?
-
Terraform:具有指定可用性区域的ElastiCache Redis集群?
我使用这个Terraform示例创建一个ElastiCache Redis集群(启用集群模式):https://www.terraform.io/docs/providers/aws/r/elasticache_replication_group.html#redis-cluster-mode-enabled 但是如何为群集和副本指定可用性节点呢?通过AWS控制台是可能的。我希望添加来指定所有主节
-
JBPM群集:jbpm-console.war未在第二个节点上部署
我正在尝试构建一个以mysql为DB的JBPM6.5集群。我正在使用Zookeeper-3.4.10 Helix-Core-0.6.8 我正在通过以下步骤创建安装程序 ./bin/helix-admin.sh--zksvr localhost:2181,localhost:2182,localhost:2183--addnode jbpm-domain-cluster server-two:123
-
为什么要运行消息队列(例如RabbitMQ)集群?
你为什么要这么做?我理解增加消息的持久性(如果一个节点关闭,其他队列仍然获得消息)。但是性能呢?集群如何提高性能。难道所有的消费者/生产者都不会连接到主节点的队列吗?如果是这样,我们不是仍然在单个节点上获得流量吗?我们是否设置了负载均衡器,使得流量每次都指向不同的节点? RabbitMQ集群如何提高性能?
-
多重Kafka——Spring Boot多重Kafka集群中的消费者
想要从使用的Spring启动应用程序的不同集群上创建同质。 即想要为已经定义的类创建一个 Kafka Consumer 对象,该对象侦听动态定义的多个集群。 例如:假设一个Spring启动应用程序S,其中包含kafkaconsumer的
-
关于在集群(AWS)上运行spark作业的说明
我有一个在AWS EC2机器上运行的HortonWorks集群,我想在上面运行一个使用spark streaming的spark工作,该工作将吞下tweet concernings《权力的游戏》。在尝试在集群上运行它之前,我确实在本地运行了它。代码正在工作,如下所示: 我的问题更确切地说是关于这段特定代码行: 17/07/24 11:53:42 INFO AppClient$ClientEndpo
-
未绑定到浮动IP的Spark群集主IP地址
null 当我尝试使用这些浮动IPs和标准公共IPs时,我遇到了问题。 在spark-master计算机上,主机名为spark-master,/etc/hosts类似于 对spark-env.sh所做的唯一更改是。如果我运行,我可以查看web UI。 您的主机名spark-master解析为环回地址:127.0.1.1;使用192.x.x.1代替(在接口eth0)16/05/12 15:05:33
-
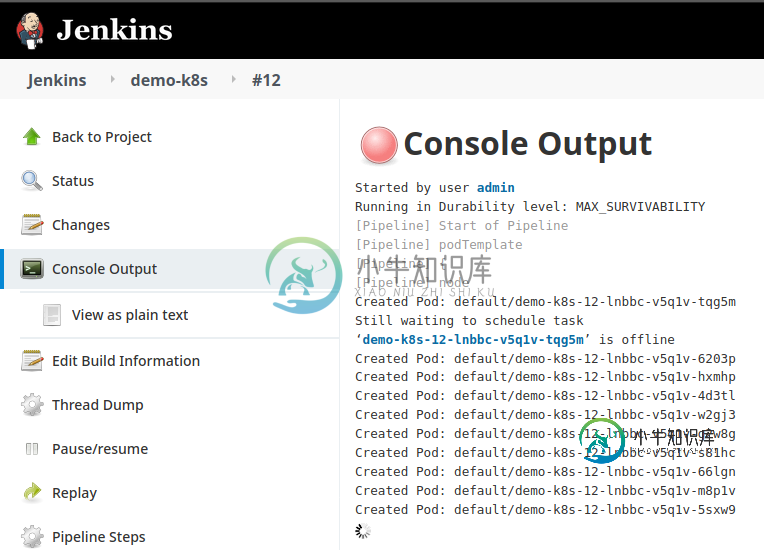 Jenkins管道作业继续在kubernetes集群内创建pod
Jenkins管道作业继续在kubernetes集群内创建pod最近我一直试图在詹金斯内部建立一个管道。目标是创建一个pod并执行kubernetes部署。 但是当我运行管道作业时,它会一个接一个地创建pod,它永远不会完成作业- 设置kubernetes集群-成功 安装jenkins-成功 连接jenkins到kubernetes集群-成功 这是管道脚本- 不-Pods创建成功,kubernetes部署也成功,但jenins管道从未停止。 我的jenkins
-
创建运行在多个docker容器上的HazelCast集群
有没有人知道,如果我们想在运行在多个docker容器上的Hazelcast实例之间形成Hazelcast集群,那么需要在Hazelcast.xml中进行哪些配置。我们应该提供127.0.0.1作为成员的地址还是应该提供docker主机的地址?Local.LocalAddress属性是否需要指向docker主机地址? 编辑:
-
Akka集群单例创业的正确道路是什么
null 我看到“singleton actor总是在具有指定角色的最老成员上运行。”在Akka集群中,单例Doc。但我不明白singleton是怎么开始的。也许所有的单例都必须在第一个种子节点中实现和启动?