《大数据测试》专题
-
python - psycopg2处理大数据量SQL在execute(sql)卡死?
题目描述 sql='select * from A',A表有8百万数据 前段时间写了数据库互相导数据的Python脚本,是Oracle导入postgreSQL,使用cx_Oracle执行execute(sql)没有任何问题。这次是postgreSQL导入postgreSQL,使用psycopg2执行execute(sql)就直接卡死在这一行了,并且内存占用持续上升。 自己的思路 数据库连接是没有问
-
 星环科技大数据后端二面凉经6.21
星环科技大数据后端二面凉经6.21大概1h 1.问基本情况 2.docker和java和k8s和大数据的接触情况 3.docker和虚拟机区别,以及虚拟化层次区别 4.java异常分类 5.看代码想结果 6.数据库mysql编码方式区别 7.mysql主键索引一般咋用,有没有用string作为主键 8.delete和tuncate区别 9.uuid和主键id区别 10.7层分层模型和什么层什么协议 11.长连接和长连接长连接在哪一
-
 星环科技大数据后端实习一面45min
星环科技大数据后端实习一面45min1.项目介绍+闲聊18min 2.springboot事务失效场景 3.uuid和自增id区别,分库分表场景下 4.使用过的JUC 5.分布式锁、ID实现原理,项目里的技术选型 6.快照读和当前读,以及mysql下对应的问题 7.手写除单例模式外其他的设计模式 8.求给定的数组中和为0的最长子序列的长度 update8点通知过了,约第二天二面
-
 美团大数据开发工程师-转正实习
美团大数据开发工程师-转正实习发帖求好运 部门:基础研发平台-数据科学与平台部 --------- 一面:57min 1.自我介绍; 2.讲最熟悉的项目; 3.爬虫遇到的问题,如何处理的呢; 4.mysql:left join \ right join \ full join,用一个案例讲一下; 5.数据仓库了解吗; 6.Hashmap的原理了解吗; 7.Hadoop了解吗; 8.NameNode了解吗; 9.HDFS为什么安
-
 星环大数据开发校园实习生面经
星环大数据开发校园实习生面经1、flume架构组成以及作用 2、flume到kafka中,如何保证同一个组件的数据放在kafka同一个分区里面 3、kafka支持全局有序吗?kafka isr?介绍kafka副本与hdfs副本区别 4、zookeeper在项目中的作用?如何判断节点是否存活? 5、HDFS什么功能用到了zookeeper? 6、spark的执行流程,比如做一个wordcount 7、sparkcontext内
-
 5.13亚信-暑假实习-大数据-电话二面
5.13亚信-暑假实习-大数据-电话二面16 min 七点左右打的电话,问我什么时间有空面试,我当时正和女朋友在汤泉泡澡,心想周六晚上怎么搞这么一出,就有些火大,也没改时间,反正也不去,应付一下吧。 Java、Python用的那个熟练? Java水平怎么样,常用的框架都会那些? Java 字符串的API有那些? 集合用过那些?有那些API? 怎么遍历集合?迭代器讲讲? 说说快排的思想? 比较器怎么实现? Linux shell 命令 讲
-
如何有效预测数据是否可压缩
问题内容: 我想编写一个存储后端来存储更大的数据块。数据可以是任何东西,但主要是二进制文件(图像,pdf,jar文件)或文本文件(xml,jsp,js,html,java …)。我发现大多数数据已经被压缩。如果所有内容都经过压缩,则可以节省大约15%的磁盘空间。 我正在寻找最高效的算法,该算法可以高概率地预测可以压缩或不压缩(无损压缩)大块数据(假设无损压缩),而不必尽可能查看所有数据。 压缩算法
-
在PHP json_decode()中检测到错误的json数据?
问题内容: 通过json_decode()解析时,我正在尝试处理错误的json数据。我正在使用以下脚本: 如果$ _POST等于: 然后,json_decode会正确处理错误并吐出“错误的json数据!”;但是,如果我将$ _POST设置为“无效数据”之类的东西,它将给我: 我是否需要编写自定义脚本来检测有效的json数据,还是有其他一些漂亮的方法来检测到此数据? 问题答案: 以下是有关以下几点的
-
Android数据绑定问题:“原因:无法猜测”
我正在使用添加启用数据绑定 数据绑定{启用=真} 和 卡普特公司。Android数据绑定:编译器:3.1.4' 在应用程序级别<代码>生成。gradle文件。 应用插件:“kotlin kapt” 是添加在此之上。项目基于kotlin。 这是我的模型: 主要活动: 这是我的布局: 我会得到这个错误: 我怎样才能解决这个问题?有什么问题吗?
-
如何转换两个不可观测数据流
我有两个可观察的
-
在Python中基于两组数据进行预测
想象一下你有两个来源。例如,某一天在谷歌上搜索“iPhone”的频率有多高,某一天卖出了多少部iPhone。你会想到,如果某一天iPhone被搜索了很多,那么接下来的几天销量就会增加。如果你有过去3个月的数据,那么你就可以根据iPhone的搜索次数,或者根据过去的销售模式和过去几天的销售次数来预测未来几天的销售数量是增加还是减少。因此,您希望根据这2个来源对其中的1个(销售数量)进行预测。因此,如
-
我的最大1、最大2、最大3数的代码正在通过所有测试用例,但一个测试用例显示MLE错误,有人知道如何通过吗?
给定一个大小为N的数组A,您需要找到它的最大值、第二最大值和第三最大值元素。尝试在每个测试用例中以O(N)求解它 输入 输入的第一行包含测试用例的数量T。 对于每个测试用例,输入的第一行包含一个整数N,表示数组A中的元素数。下一行包含A的N个(空格分隔)元素。 在我的代码中,除了一个显示MLE的测试用例之外,每个测试用例都通过了。
-
 TestNG参数化测试
TestNG参数化测试主要内容:1. 使用XML传递参数,2. 通过@DataProvider传递参数,3. @DataProvider + 方法,4. @DataProvider + ITestContextTestNG中的另一个有趣的功能是参数化测试。 在大多数情况下,您会遇到业务逻辑需要大量测试的场景。 参数化测试允许开发人员使用不同的值一次又一次地运行相同的测试。 TestNG可以通过两种不同的方式将参数直接传递给测试方法: 使用 使用数据提供者 在本教程中,我们将向您展示如何通过XML 或将参数传递给方法。
-
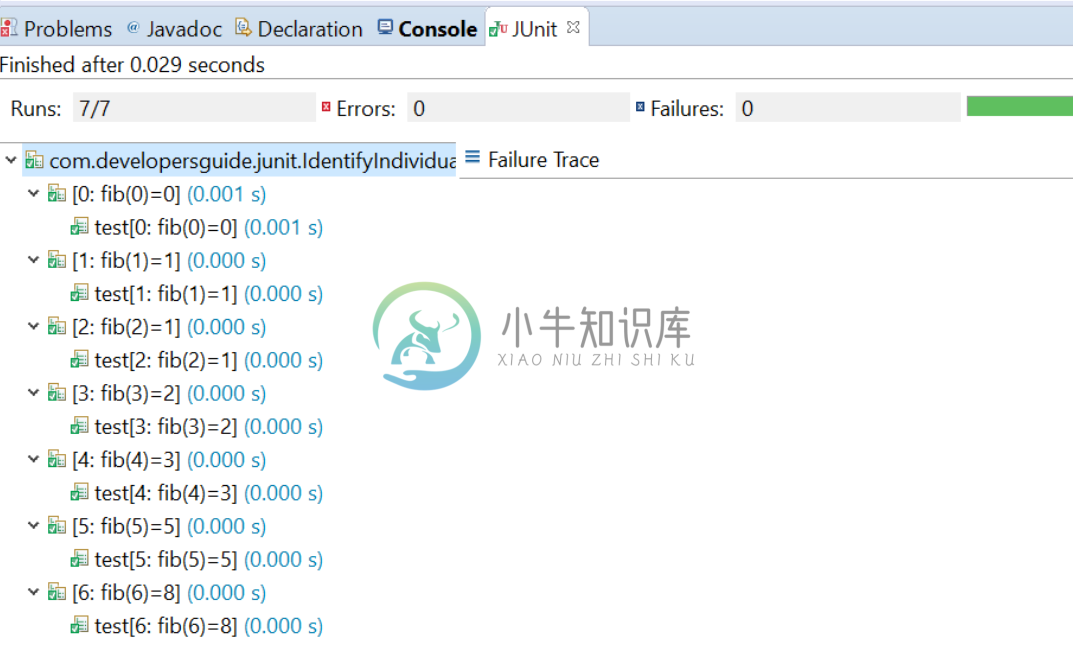 Junit4 参数化测试
Junit4 参数化测试主要内容:1 参数化测试的介绍,2 使用@Parameter进行字段注入而不是构造函数,3 使用单个参数进行测试,4 识别单个测试用例1 参数化测试的介绍 自定义流道参数化实现参数化测试。运行参数化测试类时,将为测试方法和测试数据元素的叉积创建实例。 例如,要测试斐波那契函数,请编写: FibonacciTest的每个实例都将使用二元参数构造函数和方法中的数据值构造 @Parameters 。 2 使用@Parameter进行字段注入而不是构造函数 也可以将数据值直接注入字段中,而无需使用@Pa
-
Python函数测试ping
问题内容: 我正在尝试创建一个可以定时调用的函数,以检查ping是否良好并返回结果,以便更新屏幕显示。我是python的新手,所以我不完全了解如何在函数中返回值或设置变量。 这是我的代码有效: 这是我创建函数的尝试: 这是我的显示方式: 所以我要寻找的是如何从函数返回pingstatus。任何帮助将不胜感激。 问题答案: 看起来您想要关键字 您需要使用类似以下内容的变量来捕获/“接收”函数的返回值