《大数据测试》专题
-
 科大讯飞测试实习一面凉经
科大讯飞测试实习一面凉经2024.7.9 在实习僧上面投了没两天就收到hr的微信请求约好了面试时间,面试官倒是准时,提前了两分钟开始 一开始就是常规的自我介绍,然后面试官介绍了这个岗位的工作内容后,他就问了一个问题 有一个答题卡扫描系统要测试,请问你要怎么测试 我就从功能和非功能测试两个方面去回答,回答完毕后面试官就让我反问了,我就问:在工作中有什么经验可以提供给我们学习 面试官就说让我多看多积累 大概率是凉了。。。。
-
 浙江省北大信研院-测试面经
浙江省北大信研院-测试面经全称:浙江省北大信息技术高等研究院,是北京大学和浙江省gov合办的研发机构,以研发产品为主要业务。北大信研院对求职者的学校水平层次有要求,如果通过面试的求职者的学校不在要求范围内,通过面试后入职的是与其合作的公司(杭州明实科技有限公司)。二者工作内容相同。 面试时间:2024年3月 ———————— 测试实习生面经(45min)———————— 1. 了解基本情况。 2. 网络场景题:a通过微信给
-
 众安国际(大连)业务测试实习
众安国际(大连)业务测试实习笔试挂! 笔试题型,选择题73道,包括常识题、例如世界上最大的沙漠是什么——Sahara Desert,不过都是问题和选项,需要具备英语基础;还有智力题,如有一口井深7米,白天向上爬3米,晚上向下滑2米,问几天能爬到井上?——5天; 还有设计模式的题,如能解决对象之间依赖关系的设计模式是?——代理模式; 还有测试基础的,如什么测试适合编码阶段检查——单元测试; mysql的题,如给出mysql语句
-
数据类型来表示Java中的大十进制
问题内容: 哪种数据类型倾向于代表十进制数字,例如“ 10364055.81”。 如果尝试使用double: 但是,当我尝试打印该数字时,它会显示为“ 1.036405581E7 ”,这是我不想要的。 我应该使用BigDecimal吗?但其显示为 10364055.81000000052154064178466796875 。是否有任何数据类型按原样显示值?同样,该数字可能大于示例中的数字。 顺便
-
dynamo数据库中不区分大小写的查询
问题内容: 我想扫描/查询发电机数据库表。Dynamo DB区分大小写。我想有时将哈希/范围键用作字符串。有什么方法可以在dynamo DB级别启用不区分大小写的功能?还是存在其他解决方案?我正在使用JAVA SDK查询Dynamo 问题答案: 我可以想到2种可能的方法 1)通过调整模式在应用程序端解决 例如,假设您现在使用“名称”作为哈希键,则每当添加新用户时,您都将其姓名小写之后再添加 记住要
-
Grails,使用withTransaction插入大量数据会导致OutOfMemoryError
问题内容: 我正在使用Grails 1.1 beta2。我需要将大量数据导入Grails应用程序。如果我反复实例化grails域类然后保存它,则性能会降低到无法接受的程度。以从电话簿导入人为例: 事实证明这是缓慢的。Grails邮件列表上的某人建议在事务中分批保存。所以现在我有: 这必须至少在开始时更快。每笔交易会保存500条记录。随着时间的流逝,交易花费的时间越来越长。最初的几笔交易大约需要5秒
-
无法通过phpmyadmin文件导入数据库太大
问题内容: 我一直在尝试通过phpMyAdmin导入数据库。我的数据库文件是,它的大小是1.2 GB,我正在尝试将其导入本地,并且phpMyAdmin表示: 您可能试图上传太大的文件。请参阅文档以了解解决此限制的方法。 请帮助我,我真的需要这个工作。 问题答案: 这是由于PHP对上传文件具有文件大小限制。 如果您具有终端机/外壳程序访问权限,则以上答案@Kyotoweb将起作用。 一种实现方法是创
-
php计算整个mysql数据库大小的方法
本文向大家介绍php计算整个mysql数据库大小的方法,包括了php计算整个mysql数据库大小的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了php计算整个mysql数据库大小的方法。分享给大家供大家参考。具体如下: 这里用MB,KB或者GB的格式返回计算结果。 希望本文所述对大家的php程序设计有所帮助。
-
Elasticsearch未分配的碎片CircuitBreakingException[[父级]数据太大
我收到警报说elasticsearch有两个未分配碎片。我进行了以下api调用以收集更多细节。 以下输出 我查询了断路器配置 并且可以看到3个节点(elasticsearch-data-0、elasticsearch-data-1和elasticsearch-data-2)的父limit_size_in_byes如下所示。 我参考了这个答案https://stackoverflow.com/A/6
-
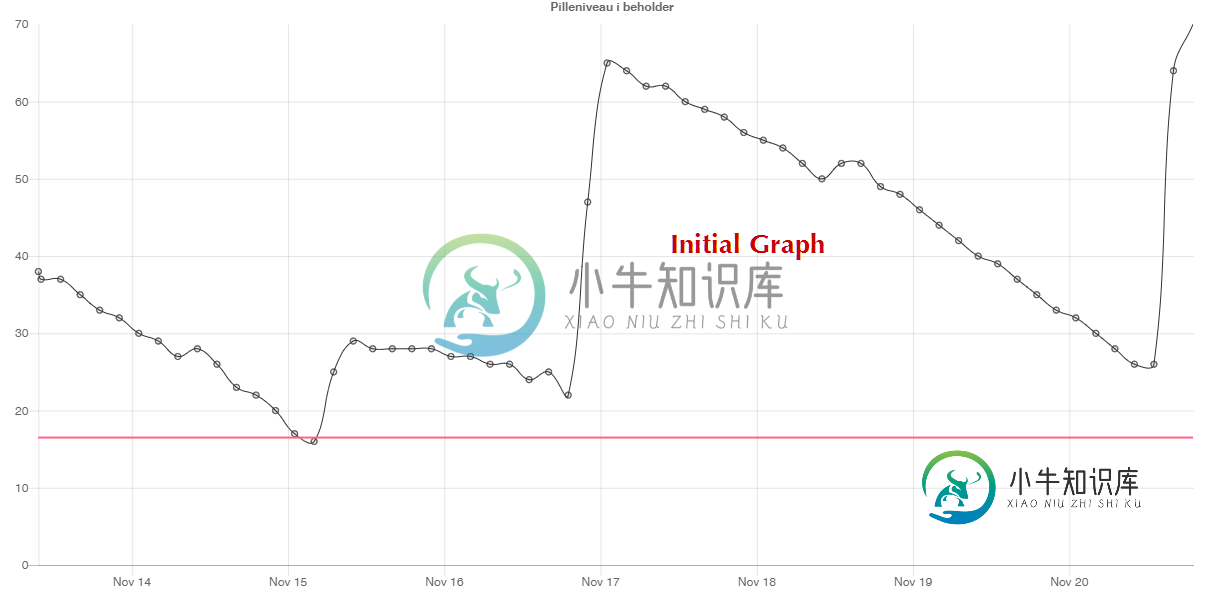 用不同大小的数据集更新chart.js图表
用不同大小的数据集更新chart.js图表我设置了一个chart.js图表,它使用mysql数据库中的数据。我已经建立了一个rest服务来提供tha数据,具有定义分组IE的能力。数据每隔5分钟测量一次,但我将其分组为3小时段,使用我的SQL语句 我希望能够通过定义一个新的粒度来改变数据的粒度。 我创建了一个更新函数来将请求发送到后端,并更新图表。 图表已更新,但默认值有61个条目(目前),最细粒度的数据有180个条目。所发生的情况是,数据
-
 根据数量动态布局固定大小的div
根据数量动态布局固定大小的div对你来说有点困惑...... 我有一个730px宽,自动高度div。在这里面,我将小div的数量164px X 261px。 这些将被动态地拉入模板,所以我可以有1个,或者我可以有18个,或者为了这个练习,我可以有1000个,或者介于两者之间的任何地方。 我需要把它们隔开,这样每一行之间就有相等的距离。简单,如果我们处理多达4个,我可以这样做: 然而,当有人说5。我想要3个在最上面一排,2个在最下
-
Neo4j/Spring数据Neo4j 4索引和字符大小写
我有以下SDN 4节点实体: 在这个实体内部,我添加了属性并声明了一个索引。 现在,我将按产品名称实现不区分大小写的搜索。 我创建了一个SDN 4存储库方法: 为了搜索产品,我使用以下密码: 我认为索引在这种情况下不能有效地工作,因为我小写了字符串。 Neo4j/SDN 4中使索引在这里工作的正确方法是什么?
-
使用J2ME存储大量数据的最佳实践
问题内容: 我正在开发一个J2ME应用程序,该应用程序具有要存储在设备上的大量数据(大约1MB,但是可变)。我不能依靠文件系统,所以我卡住了记录管理系统(RMS),该系统允许多个记录存储,但每个记录存储空间都有限。我最初的目标平台Blackberry将每个限制为64KB。 我想知道是否还有其他人必须解决在RMS中存储大量数据的问题,以及他们如何进行管理?我正在考虑必须计算记录大小并在多个存储区中拆
-
Java:将大量数据序列化为单个文件
问题内容: 我需要将大量小对象的数据(大约2gigs)序列化为单个文件,以便稍后由另一个Java进程进行处理。性能是很重要的。谁能建议一个好的方法来实现这一目标? 问题答案: 您是否看过Google的协议缓冲区?听起来像是一个用例。
-
 mysql大数据查询优化经验分享(推荐)
mysql大数据查询优化经验分享(推荐)本文向大家介绍mysql大数据查询优化经验分享(推荐),包括了mysql大数据查询优化经验分享(推荐)的使用技巧和注意事项,需要的朋友参考一下 正儿八经mysql优化! mysql数据量少,优化没必要,数据量大,优化少不了,不优化一个查询10秒,优化得当,同样查询10毫秒。 这是多么痛的领悟! mysql优化,说程序员的话就是:索引优化和where条件优化。 实验环境:MacBook Pro MJ