《大数据测试》专题
-
Java数学-NaN测试
问题内容: 我想为导致赋值的任何代码提供某种项目范围内的快速失败机制(也许是一种)。 在我的项目中从来没有一个有效的值。 我意识到我可以在整个过程中添加断言(使用isNaN)或其他测试,但是我想知道是否还有更优雅的方法。 问题答案: 是的,只要将值设置为NaN,就可以使用AspectJ(面向方面的编程)引发错误。 本质上,您希望在设置值时进行拦截,并执行其他功能。 我们已经在代码库中完成了类似
-
SpringBoot mvn测试参数
TKS
-
1.2.3.13 参数化测试
参数化测试可以用不同的参数多次运行测试。它们和普通的@Test方法一样声明,但是使用@ParameterizedTest注解。另外,您必须声明至少一个将为每次调用提供参数的来源(source)。 参数化测试目前是实验性功能。有关详细信息,请参阅实验性API中的表格。 @ParameterizedTest @ValueSource(strings = { "racecar", "radar", "a
-
 网易互娱大数据研发工程师面试经验分享
网易互娱大数据研发工程师面试经验分享本人社招,面试大数据研发工程师岗位,一共三轮面试。 1、一面(技术面),约40分钟,面试题如下: (0)自我介绍,别照着简历说,补充说些简历上没有的,比如哪里人、兴趣爱好、优势有哪些等。 (1)笔试,编程题,语言自选,题目:输入一个字符串,找出其中的整数,按升序排序后输出,多个相连的数字为一个整数,排序可用类库自带方法。 实现很简单,这里就不提供答案了。 (2)笔试,SQL编程,
-
 【这才是重量级框架】大数据开发面试题【Spark篇】
【这才是重量级框架】大数据开发面试题【Spark篇】115、Spark的任务执行流程 driver和executor,结构式一主多从模式,driver:spark的驱动节点,用于执行spark任务中的main方法,负责实际代码的执行工作;主要负责:将代码逻辑转换为任务、在executor之间调度任务、跟踪executor的执行情况。 Executor:spark的执行节点,是jvm的一个进程,负责在spark作业中运行具体的任务,任务之间相互独立,
-
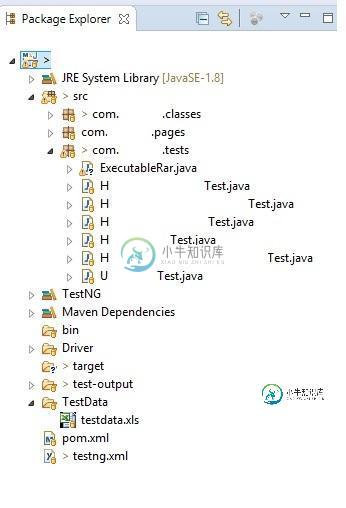 通过“可执行JAR”文件运行selenium测试时,无法从xls获取测试数据
通过“可执行JAR”文件运行selenium测试时,无法从xls获取测试数据我正在通过使用以下代码创建可执行的jar文件来运行selenium脚本。 另外,为了执行测试用例,我使用testdata.xls。每当我执行任何测试时,TestData.xls都是必需的。 下面是我的项目的层次结构:[请点击图片exapnd]。 在使用jar文件执行测试的同时,我需要做哪些更改,以便我的脚本将从test data.xls中获取测试数据? 更新:-写完这段代码后添加截图
-
 字节测开一面(大概凉)
字节测开一面(大概凉)818 1.自我介绍 2.问实习项目(怎么解决重复点击的问题 3.Mysql索引为什么快 4.c++指针和饮用的区别(不会,我说你问JAVA吧 5.哪些排序是稳定的(归并不是稳定的 6.测试的方法 7.SOFAActs为什么好 8.栈和队列的区别 9.怎么运行线程 10.静态方法和非静态方法的区别 代码:合并有序队列 感觉: 他说一个礼拜之后有结果,拒绝的很明显,我很受伤 #字节跳动##测试开发#
-
 快手大模型评测算法
快手大模型评测算法一二面技术面,主要问实习细节均有手撕,约1h 三面是主管面,有一定压力,拷打项目和实习,约0.5h 四面是hr面,15min,问了一下职业规划并简要介绍下实习经历和你觉得最有挑战的事情是什么 最后hr意思说十月底才能给出排序结果😭 鼠鼠感觉自己排序应该是靠后的,感觉希望不大了。 不知道有没有佬也是这个池子里的,可以交流一下
-
 商汤大模型测开 已oc
商汤大模型测开 已oc上周四一面 聊实习细节 聊项目细节(会对模型比较感兴趣?问一个数据分析项目使用模型解决中的细节) 用过的linux命令有哪些 代码题忘记了,中等吧 面完立即约二面,面试官出差所以只能这周二 二面 实习讲讲 项目讲讲 有自己设计过模型去解决问题吗? linux命令有哪些 八股好像都没咋问 半小时结束 周三hr电话通知通过 实习内容是对刚开发的新模型测试,商汤面试感觉不难,流程很快,hr姐姐特别温柔好
-
 众安测开面经base大连
众安测开面经base大连4.27投递 4.29收到笔试通知 5.8 一面(20min) 1.自我介绍 2.给了一个支付的场景,问怎么进行功能测试 5.10 二面 (40min) 1.介绍了一下公司情况,项目组要做的内容 2.自身情况介绍 3.测试从阶段可以分哪些部分 4.讲到了postman和jmeter,讲一下它们的主要功能 5.11 hr面(20min) 大概就是问为什么选择测开,自己的优势和缺点等主观问题 5.17
-
如何在Rails功能测试中发送原始发布数据?
问题内容: 我希望将原始的发布数据(例如,未参数化的JSON)发送到我的一个控制器进行测试: 但这给我一个symbolize_keys’ for 用什么发送原始帖子数据的正确方法是什么? 这是一些控制器代码: 问题答案: 我今天遇到了同一问题,找到了解决方案。 在您的内部定义以下方法: 在功能测试中,与方法一样使用它,但将原始文章正文作为第三个参数传递。 我在Rails 2.3.4上使用读取原始文
-
 python自动化测试之DDT数据驱动的实现代码
python自动化测试之DDT数据驱动的实现代码本文向大家介绍python自动化测试之DDT数据驱动的实现代码,包括了python自动化测试之DDT数据驱动的实现代码的使用技巧和注意事项,需要的朋友参考一下 时隔已久,再次冒烟,自动化测试工作仍在继续,自动化测试中的数据驱动技术尤为重要,不然咋去实现数据分离呢,对吧,这里就简单介绍下与传统unittest自动化测试框架匹配的DDT数据驱动技术。 话不多说,先撸一波源码,其实整体代码并不多 ddt
-
python 划分数据集为训练集和测试集的方法
本文向大家介绍python 划分数据集为训练集和测试集的方法,包括了python 划分数据集为训练集和测试集的方法的使用技巧和注意事项,需要的朋友参考一下 sklearn的cross_validation包中含有将数据集按照一定的比例,随机划分为训练集和测试集的函数train_test_split 得到的x_train,y_train(x_test,y_test)的index对应的是x,y中被抽取
-
如何在Cypress测试中公开/访问Redux等数据存储?
问题内容: 该赛普拉斯文档说可以 公开数据存储区(例如Redux中的数据存储区),以便您可以通过编程方式直接从测试代码中更改应用程序的状态。 我还观看了Kent C. Dodds先生的测试课程,他提到可以使用Cypress中的现有数据来初始化redux存储(在测试之前或之中,不确定) 我浏览了几乎所有的文档并进行了谷歌搜索,除了在介绍页面上将其作为关键区别之一外,我只是找不到任何实际执行此操作的参
-
H2集成测试数据库与MySQL prod DB命名不一致
我一直在编写一些使用内存(H2)数据库的集成测试,但我一直被这个错误所困扰。 原因:组织。h2.jdbc。JdbcSQLException:未找到表“TESTTABLE”;SQL语句: 问题是,在生产中,Hibernate正在将表名和列名从骆驼大小写更改为下划线。(TestTable- 下面是我的测试配置类: } 我宁愿不必注释所有内容,这样测试就可以知道名称是什么。 对此有什么想法或建议吗?感谢