《阿里云分布式块存储》专题
-
 分布式专题面试(1)-14个问题
分布式专题面试(1)-14个问题主要内容:1.分布式Id的策略,2.雪花算法生成的Id由哪些部分组成,3.分布式锁在项目的应用场景,4.分布式锁有哪些解决方案,5.Redis做分布式锁的话死锁有哪些情况如何解决,6.Redis如何做分布式锁,7.基于zk分布式锁的原理,8.zk和redis分布式锁的区别,9.mysql如何做分布式锁,10.计数器算法是什么,11.滑动时间窗口算法是什么,12.漏桶限流算法是什么,13.令牌桶限流算法是什么,1.分布式Id的策略 这里的uuid生成策略 1.基于时间生成:Mac地址+时间戳+随机
-
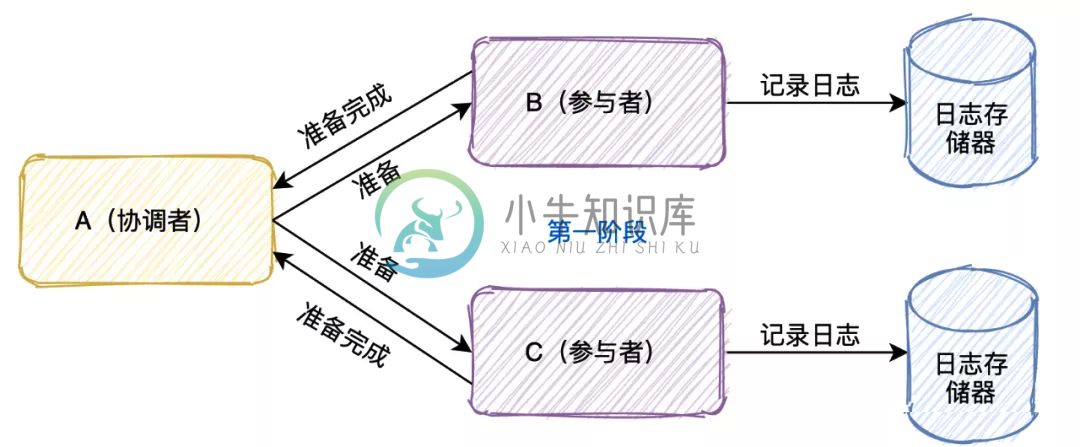 Spring Tx (分布式事务及解决方案)
Spring Tx (分布式事务及解决方案)主要内容:1.2PC,2.三阶段提交(3PC),3.补偿事务(TCC),4.本地消息表,5.消息事务,6.最大努力通知,7.Sagas 事务模型1.2PC 两阶段提交 mysql是通过日志系统完成事务的。就是两阶段提交:undolog和binlog的两阶段提交。 两阶段协议可以用于单机集中式系统,由事务管理器协调多个资源管理器;也可以用于分布式系统,由一个全局的事务管理器协调各个子系统的局部事务管理器完成两阶段提交。 第一阶段:投票阶段 1.协调者写命令进写入日志 2.协调者发一个prepare
-
 smartX分布式系统管理平台一面
smartX分布式系统管理平台一面差不多70MIN 面试官人很帅,而且上来就介绍面试流程,整个面试下来感觉很舒服,写算法题的时候也在和面试官沟通确定一些特殊情况 1.自我介绍 2.集中管理平台是什么#面经# 3.发布是怎样实现的 4.Exporter是怎么采集到数据的 (没答好 确实没了解过) 5.交付相关 6.Prometheus规则是怎样的 具体存储在哪里 7.仪表盘数据是哪里来的 Prometheus支持多少台机器 8.怎么
-
到达分布
在我的模型上,为代理设置自定义分布,以达到双峰分布,从而模拟白天的峰值。要明确的是,代理有一个名为“arrivals”的参数,我们有一个连接到代理的自定义分发,其中“arrivals”的分发设置为自定义分发。最后,源将到达率设置为上述自定义分布。然而,在运行模型时,到达的速度似乎比我在建模时预期的要快得多。分配设置为“每小时”。 以下是源设置和自定义分发source\u settings分发的屏幕
-
地域分布
地域分为两部分: 信息筛选 和 地域分布 (详情) 1.时间筛选 便捷按钮有今日、昨日、前日、上周 X、近七天,可自定义选择地域名、省份、时间段、设备等来得出想要的结果报表 2.地域分布 (详情) 1)地域分布:国家/省份、城市、接入商、国家/省份+城市、国家/省份+接入商、城市+接入商 2)如有需要,亦可点击下载当前报表及更多数据下载,将报表下载到个人电脑,以供存档及分析
-
地域分布
功能介绍 获取地域分布报告数据,包括表格详情数据与趋势数据,所获取数据与 https://mtj.baidu.com 中报告数据一致 接口 https://openapi.baidu.com/rest/2.0/mtj/svc/app/getDataByKey 此处仅列本接口特有参数,公共参数请参考报告级API说明 获取表格数据 参数名 参数类型 是否必须 描述 method string 是 r
-
分区布局
分区布局将会产生邻接的图形:一个节点链的树图的空间填充转化体。节点将被绘制为实心区域图(无论是弧还是矩形),而不是在层次结构中绘制父子间链接,节点将被绘制成固定区域(弧度或者方形),并且相对于其它节点的位置显示它们的层次结构中的位置。节点的尺寸将编码为一个量化的维度,这将难以在一个节点链图中展示。 就像D3的其他类,布局将遵循方法链模式,setter方法返回布局本身,并通过一个简洁的语句来调用多个
-
发布分支
从开发者的角度讲,一个自由软件项目处于连续发布的状态。开发者通常一直在任何时候都运行最新的可用代码,因为他们需要定位bug,而且因为他们近距离的接触项目,可以避开当前特性的不稳定区域。他们通常会每天更新他们软件的备份,有时一天几次,当他们检入变更时,他们有道理认为其他开发者会在24小时内得到。 然而,何时项目应该做出正式的发布?是否仅仅取得某个时刻的快照,打包并交给世界,然后说“3.5.0”?常识
-
春云+丝带+假+zuul+尤里卡
应用程序M1:
-
给你的云里撒点容器
夏天绝对是云计算的高危季节,因为夏天多雷暴,多火烛,运维人员难免还会上火。这三样东西像个瘟神一样在云计算圈里轮着肆虐了一阵子。教训很惨痛,影响很恶劣,但是除了 100 倍的赔偿很给力之外,我们似乎就这样拿着优惠券被遣散了。你用,或者不用,云就在那里,不悲不喜。 大家一直讲云是服务,服务就是客户至上。但是当一个东西真的成了服务,你无法对他要求过多。因为服务都是标准化的,甚至垄断的。所以你不能抱怨自来
-
如何将自定义罐子发布到本地阿帕奇常春藤存储库
我已经阅读了所有的教程和示例,但仍然无法在我的本地常春藤存储库中发布一组自定义jar 编辑:基本上,我希望与maven安装插件具有相同的行为 这是我的设置。我有一个Ant任务,它在给定的文件夹中生成jar。文件夹名称不是固定的,而是作为文件中的属性传递的。我想得到这个文件夹中的所有jar,并将它们安装到我的本地常春藤存储库中,以便在下一步使用它们 这是我的蚂蚁,我把它叫做常春藤:publish:
-
 阿里大淘宝技术java凉经(45min)
阿里大淘宝技术java凉经(45min)#面经# #凉经# 3.7晚****上联系的,3.8上午网上投递,下午约当晚面。第一次面,感觉还是太紧张了,很多东西说不清楚。 1.自我介绍。 2.问点项目balabala。 3.b+树,要设计一个索引要考量哪些。 4.two sum O(n)做法,没做过,以为是找出所有数对,开始没想出来,最后说了说大概差不多的思路。 5.布隆过滤器,redis 缓存穿透击穿雪崩,一致性balabala。 6.锁
-
 阿里暑期实习Java一面面经
阿里暑期实习Java一面面经1. 自我介绍 2. 找一个你觉得比较有代表性的项目,详细讲下这个项目做了什么事情,你做了什么样的工作,用了哪些技术,解决了什么问题。为什么要去做这个项目? 3. 中间件部分比较了解熟悉的有哪些?(redis) 4. Redis主要用来做什么,有什么作用?(缓存、消息队列、分布式锁) 5. 有没有用过或者了解Redis集群的概念?(没有) 6. 什么时候需要用到分布式锁,redis是怎么去实现分布
-
 偶然听到的一次阿里面试
偶然听到的一次阿里面试想找个没人的地方办公,无意中听见后面的师兄在面校招生,就把听到的问题记录一下: HTTP访问一个网站,发生了哪些过程? TCP三次握手发生了什么? 三次握手建立起来的连接,在操作系统层面表现的是什么? JVM的内存模型 java代码运行的时候怎么进行类加载的,这个类加载和刚刚说的JVM有什么关系? 说几个线程的状态 Thread.sleep() Thread.wait()进入哪个状态 Redis使
-
 23秋招-阿里巴巴二面面经
23秋招-阿里巴巴二面面经岗位:JAVA开发岗 部门:阿里cco 进程:二面 一共面了1小时20分钟,相比一面全是场景题,这次基本都是数据结构和算法相关的设计题目。感受偏难,不管说什么面试官都要问个问什么,有股子pua味。最后反馈说要综合对比一下才能出结果。 - 一个键值对如何插入hashmap? 哈希的应用场景? 图搜索场景如何应用哈希来优化? MD5使用哈希冲突,会有什么问题? 数据结构题 1.1T数据,内存有限,如何