《阿里云分布式块存储》专题
-
linux在哪里存储我的系统日志?
问题内容: 我编写了一个简单的测试应用程序,以将某些内容记录到日志文件中。我正在使用 linux mint ,在应用程序执行后,我尝试使用以下命令查看日志: 但是文件消息既不经过测试也不存在。在下面可以找到我的代码。也许我做错了什么,文件没有存储在那儿,或者我需要启用Linux Mint中的登录功能。 问题答案: 在我的Ubuntu机器上,我可以在看到输出。 在RHEL / CentOS计算机上,
-
在Redux中,状态实际存储在哪里?
问题内容: 我对这个问题进行了一些搜索,但发现了非常模糊的答案。在redux中,我们知道状态存储为对象。但是这种状态实际上存储在哪里?它是否以某种方式保存为文件,以后我们可以访问?我所知道的是,它不会以Cookie格式或浏览器的本地存储方式存储它。 问题答案: Redux中的状态存储在Redux存储中的内存中。 这意味着,如果刷新页面,该状态将消失。 您可以想象该商店看起来像这样: redux中的
-
Reporting Services在哪里存储其日志文件
问题内容: Google最相关的结果似乎表明,为了访问日志,我们必须将自己的日志表解绑定到数据库中,并使Reporting Services对其进行写入 。 简而言之:Reporting Services是否一定要有纯文本日志文件?如果是,这些文件存储在哪里? 问题答案: 假设您将SQL 2008安装到默认位置:C:\ Program Files \ Microsoft SQL Server \
-
临时表在SQL Server中的哪里存储?
问题内容: 临时表在哪里存储在数据库中?我想删除一个临时表(如果已经存在)。我可以通过查询信息模式来对安全表执行此操作,但是我不知道临时表的存储位置。 问题答案: 临时表存储在tempdb数据库中。这里概述了检查临时表是否存在的多种方法:检查是否存在临时表。
-
主机上的Docker映像存储在哪里?
我设法找到了目录下的容器,但找不到映像。 下的目录和文件是什么?
-
.eh_frame和.eh_frame_hdr部分分别存储什么?
问题内容: 我知道,当使用支持异常的语言(例如C ++)时,必须向运行时环境提供其他信息,以描述在处理异常期间必须解开的调用框架。此信息包含在目标文件的特殊部分中,例如和。 但是,这些部分中存储了什么样的数据结构?我的意思是,可以使用任何C结构读取它们吗?难道他们有什么做的语句(如,,,,和在GNU汇编代码)?如果它们这样做,那么这些子句中的每一个在这些部分中引起什么?本节与该节有什么关系? 我希
-
wcsdup分配的内存是否应该显式释放?
wcsdup等函数隐式调用malloc为目标缓冲区分配内存。我想知道,由于内存分配不是很明确,所以显式释放存储似乎合乎逻辑吗?这更像是一种设计困境,赞成和反对的理由如下 应释放,因为 不释放它会导致内存泄漏。 wcsdup/_wcsdup调用malloc来分配内存,即使是从C程序调用的。 不应该被释放,因为 wcsdup积累的内存最终会在程序退出时被释放。在整个程序生命周期中,我们总是会遇到一些内
-
使用pandas以.txt格式保存拆分数据集
尝试将数据集吐槽到和,然后需要将其保存为格式。 这是到目前为止的代码,
-
无法保存画布数据
07-24 12:36:23.742: W/System.err(10386):java.io.IO异常:拒绝许可07-24 12:36:23.750: W/System.err(10386): atjava.io.File.createNewFileImpl(本地方法)07-24 12:36:23.750: W/System.err(10386): atjava.io.File.createNe
-
在Java,我可以决定我的字段存储在哪里:寄存器、缓存还是内存?
我知道这是自动完成的——访问数据的频率越高,它存储的处理器就越近。但我能用Java语法影响它们的位置吗?按照我的理解,Volatile将数据放在三级缓存或RAM中,因为所有线程都可以看到它,对吗?
-
Redis实现分布式锁和等待序列的方法示例
本文向大家介绍Redis实现分布式锁和等待序列的方法示例,包括了Redis实现分布式锁和等待序列的方法示例的使用技巧和注意事项,需要的朋友参考一下 在集群下,经常会因为同时处理发生资源争抢和并发问题,但是我们都知道同步锁 synchronized 、 cas 、 ReentrankLock 这些锁的作用范围都是 JVM ,说白了在集群下没啥用。这时我们就需要能在多台 JVM 之间决定执行顺序的锁了
-
在Oracle分布式数据库中处理LOB的最佳方法
问题内容: 如果创建Oracle dblink,则无法直接访问目标表中的LOB列。 例如,使用以下命令创建一个dblink: 之后,您可以执行以下操作: 除非该列是LOB,否则您将收到错误: 这是有据可查的限制。 同一页上建议您将值提取到本地表中,但这有点…杂乱无章: 还有其他想法吗? 问题答案: 是的,这很混乱,不过我想不出办法避免这种情况。 您可以通过将临时表创建放入存储过程中(并使用“立即执
-
C++实现的分布式游戏服务端引擎KBEngine详解
本文向大家介绍C++实现的分布式游戏服务端引擎KBEngine详解,包括了C++实现的分布式游戏服务端引擎KBEngine详解的使用技巧和注意事项,需要的朋友参考一下 KBEngine 是一款开源的游戏服务端引擎,使用简单的约定协议就能够使客户端与服务端进行交互, 使用KBEngine插件能够快速与(Unity3D, OGRE, Cocos2d, HTML5, 等等)技术结合形成一个完整的客户端。
-
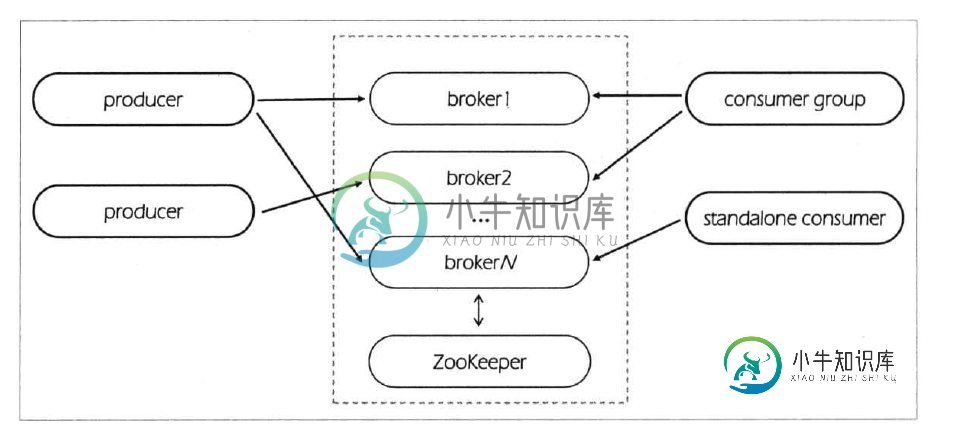 Kafka多节点分布式集群搭建实现过程详解
Kafka多节点分布式集群搭建实现过程详解本文向大家介绍Kafka多节点分布式集群搭建实现过程详解,包括了Kafka多节点分布式集群搭建实现过程详解的使用技巧和注意事项,需要的朋友参考一下 上一篇分享了单节点伪分布式集群搭建方法,本篇来分享一下多节点分布式集群搭建方法。多节点分布式集群结构如下图所示: 为了方便查阅,本篇将和上一篇一样从零开始一步一步进行集群搭建。 一、安装Jdk 具体安装步骤可参考linux安装jdk。 二、安装
-
如何在分布式性能测试中验证JMeter的性能?
我正在做一个RESTAPI性能测试,在这里我必须同时做很多请求。为此,我使用了3个JMeter实例(1个主实例和2个从实例)。 为了让您有更多的竞争,我编写了一个包含2个线程组的JMeter脚本,每个组上有150个线程和一个恒定吞吐量计时器。 下面是我用来启动测试的命令行: 在这个命令行中,吞吐量是我针对3台服务器的总吞吐量(它的值除以vmnb,我的第三个变量,然后每个服务器执行这部分吞吐量),持