《阿里云分布式块存储》专题
-
Google云平台:将数据从发布/订阅累积到云存储中的文件,无需数据流
我试图弄清楚GCP上是否有一项服务,允许使用发布/订阅的流,并将累积的数据转储/批处理到云存储中的文件中(例如,每X分钟一次)。我知道这可以通过Dataflow实现,但如果有现成的解决方案,我会寻找更多的解决方案。 例如,这是可以使用AWS Kinesis Firehose进行的操作—纯粹在配置级别—可以告诉AWS定期或在累积数据达到一定大小时将流中累积的任何内容转储到S3上的文件。 这样做的原因
-
Flysystem:Google云存储适配器-缓存控制
是否有一种方法来设置缓存控制元数据,同时将文件放入谷歌云存储使用谷歌云存储适配器Flysystem? 我的所有文件都公开在bucket中,但有时我需要更新一些文件,之后我仍然会看到旧文件。一般来说,我认为这是可能的,但我没有看到一种通过Flysystem实现这一点的方法,我们在任何地方都使用它。
-
谷歌云存储:手动清除缓存
-
Artifactory Jenkins:从自由式构建发布到maven存储库
我有一个Jenkins的自由式构建,基于一个使用SBT的Scala项目。我正试图使用Jenkins艺术工厂插件将生成的工件发布到艺术工厂存储库,特别是托管在artifactoryonline.com.的存储库。然而,我正在努力寻找一个合理的配置。我倾向于怀疑我错过了什么,但我无计可施,我找到的留档似乎都没有详细介绍这个用例,我厌倦了浏览艺术工厂插件源代码。非常感谢任何帮助。 情况如下。我想: 使用
-
分析云下载
在事件分析报告中,可对已生成的报告进行导出,导出按钮位置如图。 每日导出次数根据版本不同有所限制,剩余次数会在导出确认框中进行提示。 开通全量导出的用户,可在导出时选择是否全量导出。 导出后的报告,可在管理-分析云设置-分析云下载中进行下载,下载次数无限制。
-
 阿里设计师面试流程,做好打胜仗的充分准备
阿里设计师面试流程,做好打胜仗的充分准备01 | 进入流程系统 首先要做的是把简历和作品集成功地上传到应聘系统。 最推荐的方式是内推,因为可以让朋友帮你看看都有哪些岗位,要求是什么,你可以提前了解并做出选择。而且你的阿里小伙伴认识你要应聘的团队老板的话,还可以直接把你的作品集发给他过目,行就录入,不行也不用继续浪费时间。 一次只能有一个部门的面试流程在系统里哦,但是可以跟多个部门私下面试,最后你做出选择的时候,可以拒绝其他部门,让心仪的
-
从Google云数据存储迁移到Google云SQL
我们将Google Cloud Datastore用于Google App Engine(GAE)应用程序。在我们的项目改造期间,我们希望将数据库从Datastore迁移到Google CloudSQL。 我们在数据存储中约有1 TB数据,不包括索引。 如何从数据存储迁移到云SQL,是否有任何现有的开源解决方案可用于此。 我已经检查了下面的一个https://cloud.google.com/da
-
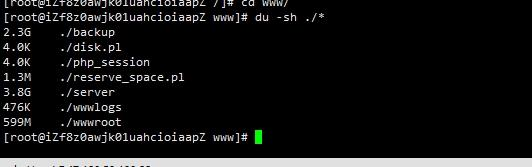 php - 阿里云linux服务器,安装宝塔后如何对服务器进行瘦身?
php - 阿里云linux服务器,安装宝塔后如何对服务器进行瘦身?公司的服务器安装的是宝塔,可是这几天看到服务器空间增长很快,从原来的6G左右 突然增长到15G左右,但是宝塔里面那些日志可以删除?请教一下告诉
-
 NoSQL数据库的分布式算法详解
NoSQL数据库的分布式算法详解本文向大家介绍NoSQL数据库的分布式算法详解,包括了NoSQL数据库的分布式算法详解的使用技巧和注意事项,需要的朋友参考一下 今天,我们将研究一些分布式策略,比如故障检测中的复制,这些策略用黑体字标出,被分为三段: 数据一致性。NoSQL需要在分布式系统的一致性,容错性和性能,低延迟及高可用之间作出权衡,一般来说,数据一致性是一个必选项,所以这一节主要是关于 数据复制 和 数据恢复 。 数据放置
-
适用于Python的分布式锁管理器
问题内容: 我有一堆服务器,其中有多个实例,这些实例正在访问对每秒请求有严格限制的资源。 我需要一种机制来锁定正在运行的所有服务器和实例对此资源的访问。 我在github上找到了一个宁静的分布式锁管理器:https : //github.com/thefab/restful-distributed-lock- manager 不幸的是似乎有一个分钟。锁定时间为1秒,并且相对不可靠。在几次测试中,解
-
SpringBoot+Dubbo+Seata分布式事务实战详解
本文向大家介绍SpringBoot+Dubbo+Seata分布式事务实战详解,包括了SpringBoot+Dubbo+Seata分布式事务实战详解的使用技巧和注意事项,需要的朋友参考一下 前言 Seata 是 阿里巴巴开源的分布式事务中间件,以高效并且对业务0侵入的方式,解决微服务场景下面临的分布式事务问题。 事实上,官方在GitHub已经给出了多种环境下的Seata应用示例项目,地址:https
-
合流Kafka连接分布式jdbc连接器
我们已经成功地使用了MySQL - 使用jdbc独立连接器的kafka数据摄取,但现在在分布式模式下使用相同的连接器(作为kafka connect服务)时面临问题。 用于独立连接器的命令,工作正常 - 现在,我们已经停止了这一项,并以分布式模式启动了kafka connect服务,如下所示 2 个节点当前正在运行具有相同连接服务。 连接服务已启动并正在运行,但它不会加载 下定义的连接器。 应该对
-
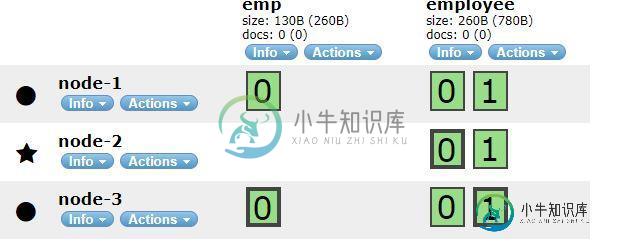 碎片和副本的基本分布方式
碎片和副本的基本分布方式我正在尝试在我的本地机器上安装弹性搜索环境的单集群-多节点环境。我混淆了碎片和复制品的概念 情况1)在下面的pic中:emp索引碎片数=1和副本数=1,这似乎很好,因为主节点不包含副本,碎片数应该是1,所以分配另一个节点中的一个成为它的碎片和副本 情况2)在情况2中,员工索引-i增加了碎片数=2和副本数=2-> 下面那个头部插件在暗示什么 1)我们设置的碎片数量是否存在于每个节点中-例如,在emp
-
 Docker实现分布式应用功能教程
Docker实现分布式应用功能教程本文向大家介绍Docker实现分布式应用功能教程,包括了Docker实现分布式应用功能教程的使用技巧和注意事项,需要的朋友参考一下 本文详细讲述了Docker实现分布式应用功能。分享给大家供大家参考,具体如下: 这里接着前面一篇《Docker简单安装与应用入门教程》后面扩展应用程序。实现负载平衡,要做到这一点,必须在分布式应用程序的层次结构中的服务层实现。 在分布式应用程序中,应用程序的不同部分被
-
 Java使用Redisson分布式锁实现原理
Java使用Redisson分布式锁实现原理本文向大家介绍Java使用Redisson分布式锁实现原理,包括了Java使用Redisson分布式锁实现原理的使用技巧和注意事项,需要的朋友参考一下 1. 基本用法 针对上面这段代码,重点看一下Redisson是如何基于Redis实现分布式锁的 Redisson中提供的加锁的方法有很多,但大致类似,此处只看lock()方法 更多请参见https://github.com/redisson/red