《阿里云分布式块存储》专题
-
分布式 - 如何充分利用多个计算机资源?
有多台笔记本电脑,手机,如何统合这些计算资源? 比如我在一台电脑上安装QQ这个软件 另一台电脑上不需要再安装这个软件 也可以使用QQ这个程序也就是说同样的资源是需要在一台电脑上即可 (我尝试过网络存储,但是效果不太好,首先太慢了,其次需要把每台电脑灯配置成服务器) 另外一个要求 对于一个计算任务把它分配给不同电脑上的CPU进行计算 顺便问一下企业是如何实现多个CPU资源充分利用
-
Android发布高分辨率图像耗尽内存
问题内容: 各位开发人员,大家好。 我正忙于android从应用程序上传图像。 我也可以使用它(代码将在下面)。 但是,当我发送大图像(10兆像素)时,我的应用程序因内存不足异常而崩溃。 一个解决方案是使用压缩,但是如果我要发送完整尺寸的图像怎么办? 我想也许有些东西在溪流中,但我不喜欢溪流。也许urlconnection可能有帮助,但我真的不知道。 我给文件名命名为File [0到9999] .
-
Hazelcast-客户端模式拓扑/分布式映射锁问题
下面是我们在生产中遇到的问题的描述。请注意,我无法在测试或本地环境中再现该问题,因此无法向您提供测试代码。 我们有一个hazelcast集群,有两个成员M1、M2和三个客户端C1、C2、C3。Hazelcast版本为3.9。 客户端使用IMap。tryLock()方法,超时10秒。获得锁后,将执行关键和长时间运行的操作,最后使用IMap释放锁。unlock()方法。 生产中出现的问题如下: 在某个
-
分布式运行模式下Kafka Producer的唯一事务ID
我有一个基于过程消费的大数据应用程序- 假设我的应用程序在一台机器上运行,我实例化了2个消费者,他们有自己的生产者,例如生产者1有事务ID - 如果我的应用程序在一台机器上工作,这完全可以正常工作,但是,事实并非如此,因为应用程序需要在多台机器上运行,因此当相同的代码在机器2上运行时,由机器2上的消费者实例化的生产者将具有与机器1上相同的事务ID。我希望事务ID的生成方式不会相互冲突,并且它们是可
-
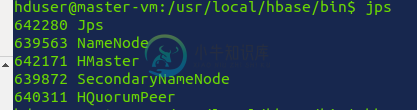 HBase完全分布式模式[执行HBase shell时Zookeeper错误]
HBase完全分布式模式[执行HBase shell时Zookeeper错误]根据这两个教程:即教程1和教程2,我能够在完全分布式模式下设置HBase集群。最初,集群似乎工作正常。 hmaster/Name节点中的“jps”输出 datanodes/RegionServers中的jps输出 null (我已经试着在/etc/hosts/中评论与HBase相关的主机,但仍然没有成功) 在hbase-site.xml中
-
深度剖析一站式分布式事务方案Seata-Server
再前不久,我写了一篇关于分布式事务中间件Fescar的解析,没过几天Fescar团队对其进行了品牌升级,取名为Seata(Simpe Extensible Autonomous Transcaction Architecture),而以前的Fescar的英文全称为Fast & EaSy Commit And Rollback。可以看见Fescar从名字上来看更加局限于Commit和Rollback
-
谷歌云存储与aws s3多部分上传的兼容性
好吧,我有一个使用AmazonS3 multipart的应用程序,它们使用CreateMultipart,UploadPart和CompleteMultiPart。 现在我们正在迁移到谷歌云存储,而我们在MultiPart上遇到了一个问题。据我所知,谷歌不支持s3多部分,从这里得到了谷歌云存储支持s3多部分上传的信息。 所以我看到google有最接近的方法Compose https://cloud
-
将阿拉伯语存储到mysql中
我有一个关于阿拉伯语编码和将阿拉伯语存储到mysql的问题。 我应用了以下所有步骤: set-MySQL字符集:UTF-8 Unicode(utf8) 设置MySQL连接排序规则:utf8\u常规\u ci 集合数据库和表排序规则设置为:utf8\U general\U ci或utf8\U unicode\U ci mysql_查询(“设置名称‘utf8’”); mysql_查询('SET CHA
-
上传谷歌云存储iOS
我应该做什么才能成功上传图片?任何帮助都将不胜感激。 非常感谢。
-
在云扳手中存储 UUID
我想在Cloud Spanner中使用UUID作为主键。读写UUID的最佳方式是什么?是否有UUID类型或客户端库支持?
-
VideoWriter输出到Google云存储
我正在创建一个web应用程序,使动画从框架。我使用opencv和VideoWriter来实现它。但有个问题。我想在Google App Engine上托管我的应用程序,所以我不能在上面保存文件。是否可以直接将VideoWriter视频输出到谷歌云商店,而不保存在机器上,或者我必须找其他库来实现?
-
谷歌云存储ACL混乱
我是一个谷歌云项目的所有者,里面有一个谷歌云存储桶。我们所有的备份都被移到这个桶中。当我试图检索一些备份时,我得到了一个被拒绝的权限。我什么也做不了,只能把桶列出来。 当我尝试用 CommandException:未能为gs://abc/1234.sql设置acl。请确保您拥有对此资源的所有者角色访问权限。 这毫无意义,因为我是项目和桶的所有者。
-
1.6.7 文件系统 / 云存储
简介 Lumen 有很棒的文件系统抽象层,是基于 Frank de Jonge 的 Flysystem 扩展包。 Lumen 集成的 Flysystem 提供了简单的接口,可以操作本地端空间、 Amazon S3 、 Rackspace Cloud Storage 。更好的是,它可以非常简单的切换不同保存方式,但仍使用相同的 API 操作! 配置文件 文件系统的配置文件放在 config/file
-
分区分布不均匀
我们在AWS上运行16个节点kafka集群,每个节点是m4. xLargeEC2实例,具有2TB EBS(ST1)磁盘。Kafka版本0.10.1.0,目前我们有大约100个主题。一些繁忙的话题每天会有大约20亿个事件,一些低量的话题每天只有数千个。 我们的大多数主题在生成消息时使用UUID作为分区键,因此分区分布相当均匀。 我们有相当多的消费者使用消费群体从这个集群消费。每个使用者都有一个唯一的
-
elasticsearch在哪里存储数据
问题内容: 因此,我有了这种elasticsearch安装,可以在用logstash插入数据时使用kibana可视化它们。 conf文件中的所有内容均已注释,因此它使用的是相对于elasticsearch文件夹的默认文件夹。 这怎么可能? 但是,此命令将删除数据: 谢谢。 ps:忘了说我在窗户上 问题答案: 如果您在Linux上安装了ES,则默认数据文件夹位于(CentOS)或(Ubuntu)