《大数据分析》专题
-
hazelcast数据分布
我将hazelcast服务器分布在多个节点上。我假设hazelcast将在集群中分发任何IMap数据,这样每个节点都将拥有属于映射的数据。这是建立集群后默认情况下应该发生的事情,还是需要在hazelcast.xml中设置代码或配置?
-
数据集拆分
在机器学习中,通常将所有的数据划分为三份:训练数据集、验证数据集和测试数据集。它们的功能分别为 训练数据集(train dataset):用来构建机器学习模型 验证数据集(validation dataset):辅助构建模型,用于在构建过程中评估模型,为模型提供无偏估计,进而调整模型超参数 测试数据集(test dataset):用来评估训练好的最终模型的性能 不断使用测试集和验证集会使其逐渐失去
-
 vivo数据分析面经
vivo数据分析面经测评 8.25 一面 9.19 进来常规互相自我介绍。然后面试官说,我先问你三个和简历无关的问题,顿时我心凉了半截。第一道SQL,考窗口函数,很简单。第二道考统计,问卡方分布原理,还给两分钟让去查我都没查出来。第三道考概率论,五分钟时间看着你做,彻底凉凉。不过面试小哥哥人很好,全程微笑,看我不会还给我提示,在线给我解题,我只觉得自己很没用很丢人呜呜呜。 然后简历部分就是挑一段印象最深的实习经历展开
-
数据统计与分析
获取小程序概况趋势: $app->data_cube->summaryTrend('20170313', '20170313') 开始日期与结束日期的格式为 yyyymmdd。 API summaryTrend(string $from, string $to); 概况趋势 dailyVisitTrend(string $from, string $to); 访问日趋势 weeklyVisitT
-
数据统计与分析
通过数据接口,开发者可以获取与公众平台官网统计模块类似但更灵活的数据,还可根据需要进行高级处理。 {info} 接口侧的公众号数据的数据库中仅存储了 2014年12月1日之后的数据,将查询不到在此之前的日期,即使有查到,也是不可信的脏数据; 请开发者在调用接口获取数据后,将数据保存在自身数据库中,即加快下次用户的访问速度,也降低了微信侧接口调用的不必要损耗。 额外注意,获取图文群发每日数据接口的结
-
 蚂蚁 数据分析师
蚂蚁 数据分析师蚂蚁面试体验感真的很好!!!之前在网上刷到我还不相信,面完觉得太好了。 1. 项目如何进行分析处理和得到结果的 2.为什么想来做数据分析师?跟你的背景相对区别那么大 3. 情景题如何获得种子用户以及如何安排触点能够得到更高的点击率 反问环节 聊了很多关于进入部门的发展和工作内容,本来对这个面试还不抱有什么希望,但是聊的很开心,突然觉得如果一面能过,二面一定好好准备。 1.进来以后会要做具体项目的分
-
 PDD数据分析二面
PDD数据分析二面1.transfomer底层 2.用户分级进行优惠促销 如何做 3.F1值含义 4.手撕sql 5.掷硬币的数学期望
-
9.1 本地数据分析
在5.2 本地数据存储及安全性这一节,我们对本地数据存储对安全性做了详尽的分析。 NSUserDefaults,plist,sqlite3等等,即使设备不越狱,攻击也能够提取出数据。在设备越狱之后,keychain中的数据也不安全。 因此,要对敏感数据加密,且尽量保存到keychain中(比如token信息)。 下面是2个例子。(密码都被我用password字串替换) a) 家里的WIFI信息 b
-
 大华二面 大数据开发c++
大华二面 大数据开发c++1.hashmap底层数据结构 2.virtual的使用场景,虚函数表 3.设计模式 4.多线程同步的方法 5.三次握手 6.智能指针有哪些,如何设计一个share_ptr? 7. vector是如何实现的,和list相比有何优缺点? 8.想问我网络编程方面的,我说不熟悉,跳过了…… 9.c++ 源文件到可执行文件的过程 9.多线程适用于那些应用场景? 10.stl哪些容器是线程安全的 11.补充
-
 一面数据-数据分析实习生面经
一面数据-数据分析实习生面经写在前面:这个岗位重视可视化的能力,在去年一战失败后也投过这个岗位的正职,面试前和面试中都在问有没有相应的可视化作品,对于实习生希望熟悉sql和tableau,一来就可以干活 1.自我介绍 2.对于以往实习经历和项目浅挖 3.次日留存sql代码考察 4.询问了不了解窗口函数 5.利用窗口函数计算不同品类前十GMV 6.tableau和power bi知识点考察 -技术问题一直准备的sql,DAX公
-
为什么H2数据库文件的大小要比数据大小大得多?
我有大约500MB的H2数据库。 H2的版本是1.2.147。 数据库的存储引擎是PageStore。 JDBC URL如下所示。 jdbc:h2:file://C:/h2/client;如果存在=真;MVCC=真;数据库\u事件\u侦听器。H2DBMonitor';AUTO_SERVER=TRUE;对数=2 我做了一个版本的H2 1.4.192没有改变数据库的存储引擎。 当我的客户使用数据库时,
-
将大文件中的数据分块进行多处理?
问题内容: 我正在尝试使用多重处理来并行化应用程序,该处理程序会处理一个非常大的csv文件(64MB至500MB),逐行执行一些工作,然后输出一个固定大小的小文件。 目前,我正在执行,不幸的是,它已完全加载到内存中(我认为),然后我将该列表分成了n个部分,n是我要运行的进程数。然后,我在分类列表上执行。 与单线程,仅打开文件并迭代的方法相比,这似乎具有非常非常糟糕的运行时。有人可以提出更好的解决方
-
MySQL数据库表分区注意事项大全【推荐】
本文向大家介绍MySQL数据库表分区注意事项大全【推荐】,包括了MySQL数据库表分区注意事项大全【推荐】的使用技巧和注意事项,需要的朋友参考一下 表分区与数据库分区是不一样的那么碰到表分区使用时我们要注意一些什么事情呢,今天我们来看一篇关于MySQL数据库表分区注意事项的细节。 1、分区列索引约束 若表有primary key或unique key,则分区表的分区列必须包含在primary ke
-
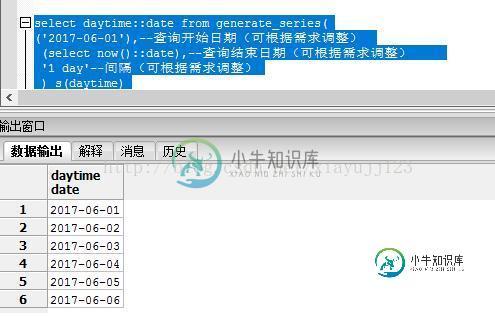 postgresql 实现取出分组中最大的几条数据
postgresql 实现取出分组中最大的几条数据本文向大家介绍postgresql 实现取出分组中最大的几条数据,包括了postgresql 实现取出分组中最大的几条数据的使用技巧和注意事项,需要的朋友参考一下 看代码吧~ 其中 执行结果: 添加行序号:ROW_NUMBER () OVER (ORDER BY A.bsm ASC) AS 序号 分组添加序号:ROW_NUMBER () OVER (PARTITION BY xzqdm ORDER
-
如何确定Apache Spark数据帧中的分区大小
我一直在使用SE上发布的问题的一个极好的答案来确定分区的数量,以及跨数据帧的分区分布需要知道数据帧Spark中的分区详细信息 有人能帮我扩展答案来确定数据帧的分区大小吗? 谢谢