《大数据分析》专题
-
CPU百分比大于100的Docker统计数据
我通过从Jmeter发送请求来强调容器,然后通过docker stats命令监视容器的cpu使用情况,该命令给出的值大于100%。 我不明白为什么即使只给容器分配一个核心,它也会给出超过100%的!。你知道原因吗?这个cpu值是否表示除了容器之外的某些系统进程的cpu使用情况? 提前感谢你的帮助。 docker信息结果:集装箱:2运行:1暂停:0停止:1图像:10服务器版本:17.06.0-CE存
-
 10.14-潍柴雷沃-大数据-10分钟速通
10.14-潍柴雷沃-大数据-10分钟速通面试时间:12min 自我介绍 身高?体重? 高考分数?六级过了没?在学校成绩,排名多少? 家庭父母? 实习项目介绍? 用的什么ETL工具? Hive学的怎么样? 那些表是增量,那些是全量?为什么这样设计? 反问:部门业务 隔了三天给hr打电话说是通过了,这个周发offer,这是我迄今为止面过时间最短,流程最快的公司,666
-
 数据分析一面
数据分析一面经纬恒润 1.介绍下数学建模竞赛,你做了啥工作 2.介绍下实习项目 3.你mentor对你的评价 4.薪资要求,工作地点 5.sql题
-
WinPcap: 分析数据包
现在,我们可以捕捉并过滤网络流量了,那就让我们学以致用,来做一个简单使用的程序吧。 在本讲中,我们将会利用上一讲的一些代码,来建立一个更实用的程序。 本程序的主要目标是展示如何解析所捕获的数据包的协议首部。这个程序可以称为UDPdump,打印一些网络上传输的UDP数据的信息。 我们选择分析和现实UDP协议而不是TCP等其它协议,是因为它比其它的协议更简单,作为一个入门程序范例,是很不错的选择。让我
-
如何分析数据
当你检查一个商业活动并且发现了把它转换为软件应用程序的需求时,数据分析是软件开发早期的一个过程。这是一个官方的定义,当你,一个程序员,应该集中注意力在写别人设计的东西的代码时,这可能会让你相信数据分析是一种更应该归入系统分析的行为。如果我们严格遵循软件工程范式,这可能是正确的。有经验的程序员会成为设计者,最尖锐的设计者变成商业分析师,因此被冠名去思考所有数据需要,并且给你充分定义的任务去执行。这不
-
数据分析系统
数据概览 1.数据概览 首页>报表>数据 查看时间范围内系统的关键数据指标。包括总会话量、总消息量、平均会话时长、平均响应时长、排队放弃会话量、平均满意度以及会话量、消息量、平均会话时长之间的变化趋势条形图、柱状图和饼状图。 2.客服报表 首页>报表>客服 客服工作量分析:查看人工客服的工作数据。包括接待总数、对话总数、对话总时长、在线总时长以及在线人工利用率。 客服工作效率/质量分析:查看人工客
-
 客尼数据分析
客尼数据分析1.简历 2.标准化和归一化 3.ab test 4.如何与非技术人员进行沟通
-
 招联-数据分析
招联-数据分析1轮面试 5.13下午三点面试 1.自我介绍 2.实习项目深挖,好像也没问很多 (实习的经历和数分并不是很相关,偏算法) 3.比赛项目深挖 数据有哪些特征,用了什么模型,xgboost原理和rf的优缺点 4.反问 总得来说好像并没有问很深很难的的问题 二轮面试 一面面完五分钟内就通知过了 四点半开始(效率感人😂) 1.自我介绍 2.base,投了哪些公司,有什么offer(可能比较关注意向度)
-
 度小满运营数据分析师一面大约凉经
度小满运营数据分析师一面大约凉经基本不问简历,偏业务和基础知识 1.认为数据分析在行业中的作用 2.sort by和order by的差别 3.采用调研的方式效率低、成本高,怎么从数据角度分析 用户画像哪些维度(结合信贷业务) 4.对abtest有什么了解 5.为什么会产生过拟合的情况如何解决 #度小满##面试##数分#
-
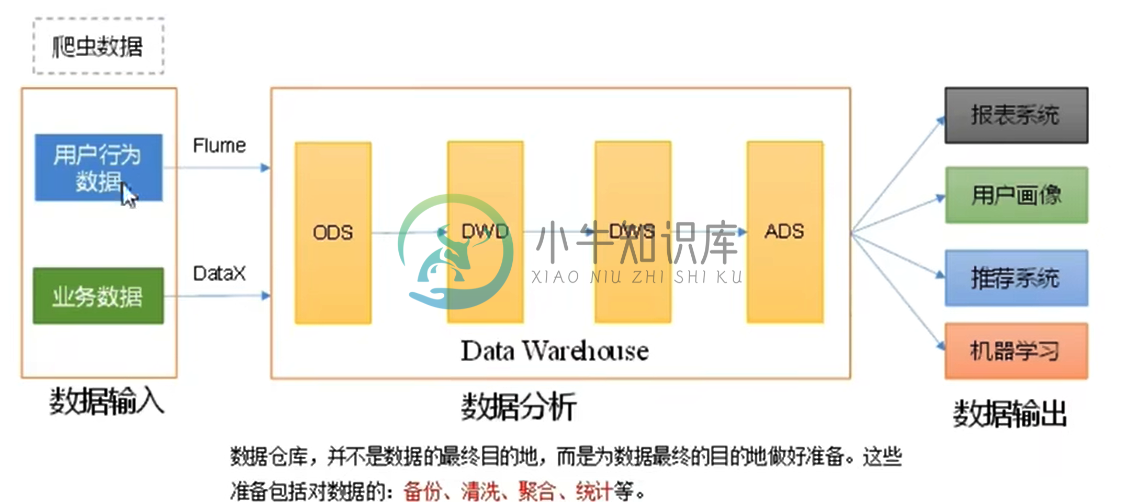 大数据平台之数据存储
大数据平台之数据存储主要内容:1.大数据生态技术,2.数据存储,3.数据存储的发展,4.数据存储的方式1.大数据生态技术 数据存储处理: 清洗, 关联, 规范化, 组织建模, 通过数据质量的检测, 数据分析然后提供相应的数据服务 离线数仓: 实时数仓: 以Kafka, cancal/Maxwell/FlinkCdc为区分, 离线数仓为Hive, Sqoop 实时数仓:分层: Ods, Dwd, Dim, Dwm, Dws, Ads 离线数仓分层: Ods. Dwd, Dws, Dwt, Ads 实
-
 龙湖数科数据分析
龙湖数科数据分析9.16 一面 20min左右 1.自我介绍 2.挖实习,针对部分细节做提问 3.数据分析需要哪些技能 4.反问 9.19 二面 25min 1.自我介绍 2.深挖简历,面试官比较关注项目的产出 3.广告投放的渠道分析(实习中有) 4.是否了解地产数字化 5.反问 问了下后续面试流程,说是至少还有一轮业务面+hr面,如果sp的话还会有总监面 许愿终试 龙湖数科数据分析求抱团 #龙湖集团数字科技##
-
pandas数据框的最大大小
问题内容: 我试图使用s或函数读取稍大的数据集,但我一直遇到s。数据框的最大大小是多少?我的理解是,只要数据适合内存,数据帧就应该可以,这对我来说不是问题。还有什么可能导致内存错误? 就上下文而言,我试图在《2007年消费者金融调查》中阅读ASCII格式(使用)和Stata格式(使用)。该文件的dta大小约为200MB,而ASCII的大小约为1.2GB,在Stata中打开该文件将告诉我,对于22,
-
 科大讯飞大数据一面
科大讯飞大数据一面#科大讯飞求职进展汇总##春招# 面试官人很好,还挺帅(有点像shy哥? 全程拷打简历,会重点问实习和2个左右项目 本来我在不断引导面试官问我数据库和机器学习方面的内容,但是面试官好像不怎么想问,连数据怎么清洗的这种都没问,就问了聚类了解那些?k-means聚类怎么优化?肘部法则和肘部加速的区别? 由于我项目大都是deep learning方向的,所以都在让我讲dl方向的东西 还有就是项目遇到了哪
-
熊猫对HDFStore中的大数据进行“分组依据”查询?
问题内容: 我有大约700万行,其中有60列以上。数据超出了我的内存容量。我正在基于列“ A”的值将数据聚合到组中。熊猫拆分/汇总/合并的文档假定我已经将所有数据都存储在了,但是我无法将整个商店读取到内存中。在分组数据的正确方法是什么? 问题答案: 这是一个完整的例子。 输出量 一些警告: 1)如果您的组密度相对较低,则此方法很有意义。大约数百或数千个组。如果获得的收益更多,则效率更高(但方法更复
-
大数据增量PCA
问题内容: 我只是尝试使用sklearn.decomposition中的IncrementalPCA,但它像以前的PCA和RandomizedPCA一样引发了MemoryError。我的问题是,我要加载的矩阵太大,无法放入RAM。现在,它以形状〜(1000000,1000)的数据集形式存储在hdf5数据库中,因此我有1.000.000.000 float32值。我以为IncrementalPCA可