《大数据分析》专题
-
大数据集的TFIDF
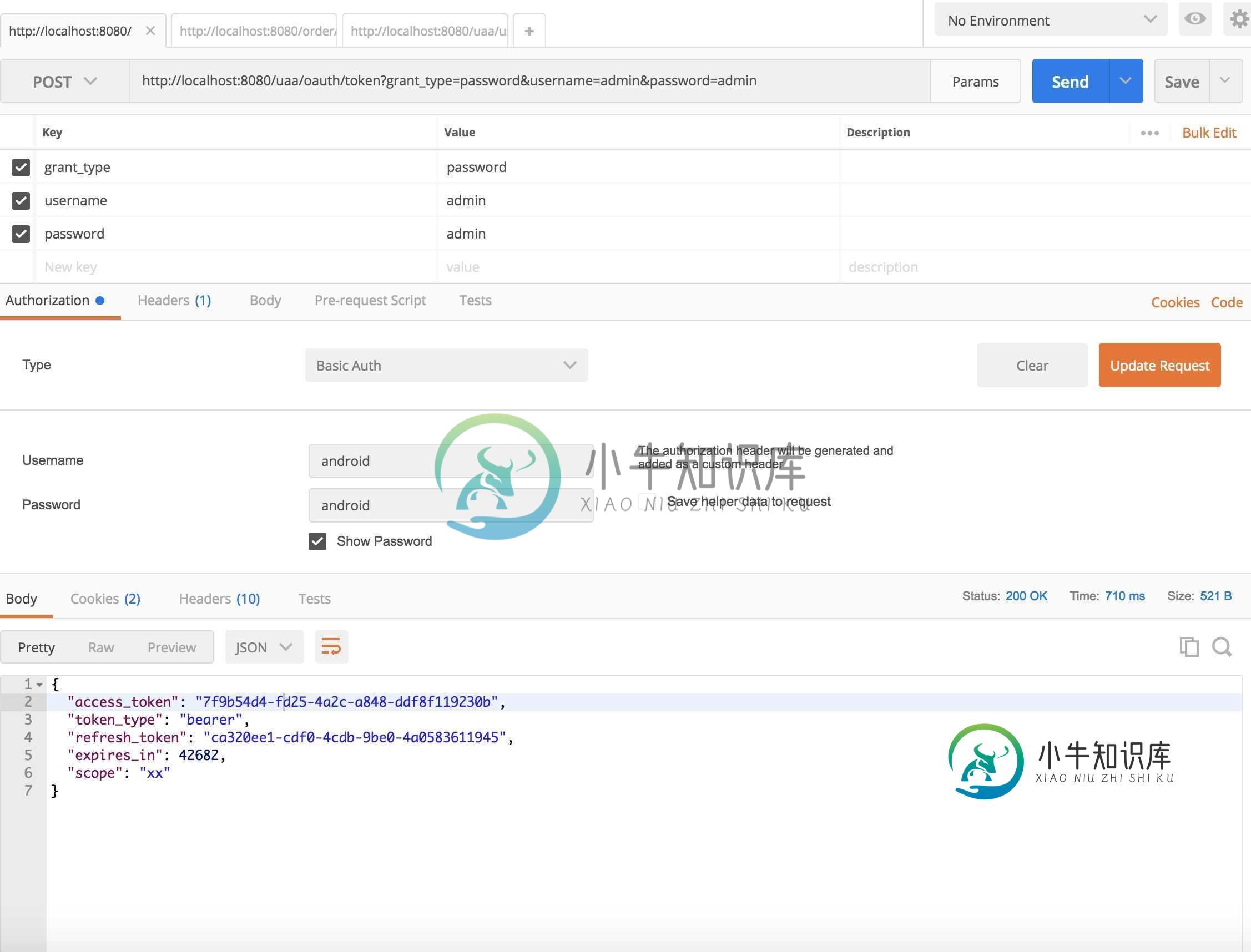
问题内容: 我有一个大约有800万条新闻文章的语料库,我需要以稀疏矩阵的形式获取它们的TFIDF表示形式。我已经能够使用scikit-learn来实现相对较少的样本数量,但是我相信它不能用于如此庞大的数据集,因为它首先将输入矩阵加载到内存中,这是一个昂贵的过程。 谁知道,对于大型数据集,提取TFIDF向量的最佳方法是什么? 问题答案: Gensim具有高效的tf-idf模型,不需要一次将所有内容存
-
大数据多处理
问题内容: 我用来并行化一些繁重的计算。 目标函数返回大量数据(庞大的列表)。我的RAM用完了。 如果不使用,我只需将生成的元素依次计算出来,就将目标函数更改为生成器。 我了解多处理不支持生成器- 它等待整个输出并立即返回,对吗?没有屈服。有没有一种方法可以使工作人员在数据可用时立即产生数据,而无需在RAM中构造整个结果数组? 简单的例子: 这是Python 2.7。 问题答案: 这听起来像是队列
-
编写大型数据
由于网络的原因,如何有效的写大数据在异步框架是一个特殊的问题。因为写操作是非阻塞的,即便是在数据不能写出时,只是通知 ChannelFuture 完成了。当这种情况发生时,你必须停止写操作或面临内存耗尽的风险。所以写时,会产生大量的数据,我们需要做好准备来处理的这种情况下的缓慢的连接远端导致延迟释放内存的问题你。作为一个例子让我们考虑写一个文件的内容到网络。 在我们的讨论传输(见4.2节)时,我们
-
 10.24京东大数据
10.24京东大数据1.自我介绍 2.大数据项目battle 3.对于窗口函数的了解 有什么,什么场景,怎么用 4.文本拼接函数是什么 5.hbase负载均衡怎么实现 6.cv项目battle 不同模型的区别 网络+部署 7.反问 京东商城核心检索业务 和leader讨论面试结果,一周内hr会联系
-
 soul大数据面经
soul大数据面经1.自我介绍 2.你的优势是什么 3.对数仓怎么看 4.sql,有id,score。怎么实现按score排序并且要排名,不能使用开窗函数。
-
 tplink大数据开发
tplink大数据开发6.27一面 20min 问简历,介绍项目提到的各种模型,做了什么优化 有没有spark实践的经历 介绍一下hadoop 了解哪些机器学习算法 xgboost和随机森林的区别 有用Java做过项目吗(无...) 反问 6.28二面 35min 简历项目一个一个详细讲 transformer编码器解码器区别 transformer位置编码的情况 spark实践经历 反问
-
大量的素数分解
问题内容: 我想找到小于10 ^ 12的大数的质分解。我得到了以下代码(在Java中): 首先,上述算法的复杂性是什么?我很难找到它。 而且对于大量的素数来说太慢了。 有没有更好的算法,否则如何优化这种算法? 问题答案: 如果您想分解 许多 大数,那么最好先找到质数最大(例如使用Eratosthenes的Sieve)。然后,您只需要检查那些质数是否是因数,而不是全部测试。
-
蛮力大整数分解
正如你从标题中所看到的,我正在努力对因子为2个素数的大整数进行强制因子分解。我想知道是否有一种方法可以在for循环中使用for循环。我知道这是一种很糟糕的方式,但无论如何我都愿意这样做。(我本来打算使用费马分解定理,但如果没有一些额外的方法/库,你就不能求大整数,我无法做到这一点),所以请尝试一下,看看你是否可以帮助我。大致如下: 显然,这太可怕了,我知道你不能通过说i.nextPossibleP
-
 阿里大淘宝数分
阿里大淘宝数分周二约面 周四电话 人生第一次面试 甚至约面的时候我还问这是什么 面试还是啥 简历不都有吗 为什么要聊一聊(蚌埠住了,现在想想当时好傻) 面试官小哥哥可能看出来我是第一次面试 还一直安慰我不要紧张 整个面试流程体验特别好 一面 1h20mins 自我介绍 项目深挖: 每一步的背景 目的 特征工程的进一步选择 机器学习算法 怎么选择的指标 为什么不选其他指标 (简历写的基本都问了,特别特别深入,不愧
-
 【秋招】数分offer大赏
【秋招】数分offer大赏金九银十铜十一摆烂十二,想想还是给自己秋招画个总结句号 bg:中流985+港三硕,5段非大厂数分实习,无科研无奖 找工作方向:数据分析师/数据挖掘师/产品经理 timeline:8月开始,9月爆满,10月爆满,11月零零散散,12月收尾 offer:pingan、蚂蚁金服、PDD、oppo、SF、淘天 数分的薪资基本上比较接近,薪资范围在n*15——(n+5)*15,有烂大白菜也有大sp,越晚拿到
-
dynamo数据库中不区分大小写的查询
问题内容: 我想扫描/查询发电机数据库表。Dynamo DB区分大小写。我想有时将哈希/范围键用作字符串。有什么方法可以在dynamo DB级别启用不区分大小写的功能?还是存在其他解决方案?我正在使用JAVA SDK查询Dynamo 问题答案: 我可以想到2种可能的方法 1)通过调整模式在应用程序端解决 例如,假设您现在使用“名称”作为哈希键,则每当添加新用户时,您都将其姓名小写之后再添加 记住要
-
Elasticsearch未分配的碎片CircuitBreakingException[[父级]数据太大
我收到警报说elasticsearch有两个未分配碎片。我进行了以下api调用以收集更多细节。 以下输出 我查询了断路器配置 并且可以看到3个节点(elasticsearch-data-0、elasticsearch-data-1和elasticsearch-data-2)的父limit_size_in_byes如下所示。 我参考了这个答案https://stackoverflow.com/A/6
-
 mysql大数据查询优化经验分享(推荐)
mysql大数据查询优化经验分享(推荐)本文向大家介绍mysql大数据查询优化经验分享(推荐),包括了mysql大数据查询优化经验分享(推荐)的使用技巧和注意事项,需要的朋友参考一下 正儿八经mysql优化! mysql数据量少,优化没必要,数据量大,优化少不了,不优化一个查询10秒,优化得当,同样查询10毫秒。 这是多么痛的领悟! mysql优化,说程序员的话就是:索引优化和where条件优化。 实验环境:MacBook Pro MJ
-
将大熊猫数据帧分块写入CSV文件
问题内容: 如何将大数据文件分块写入CSV文件? 我有一组大型数据文件(1M行x 20列)。但是,我只关注该数据的5列左右。 我想通过只用感兴趣的列制作这些文件的副本来使事情变得更容易,所以我可以使用较小的文件进行后期处理。因此,我计划将文件读取到数据帧中,然后写入csv文件。 我一直在研究将大数据文件以块的形式读入数据框。但是,我还无法找到有关如何将数据分块写入csv文件的任何信息。 这是我现在
-
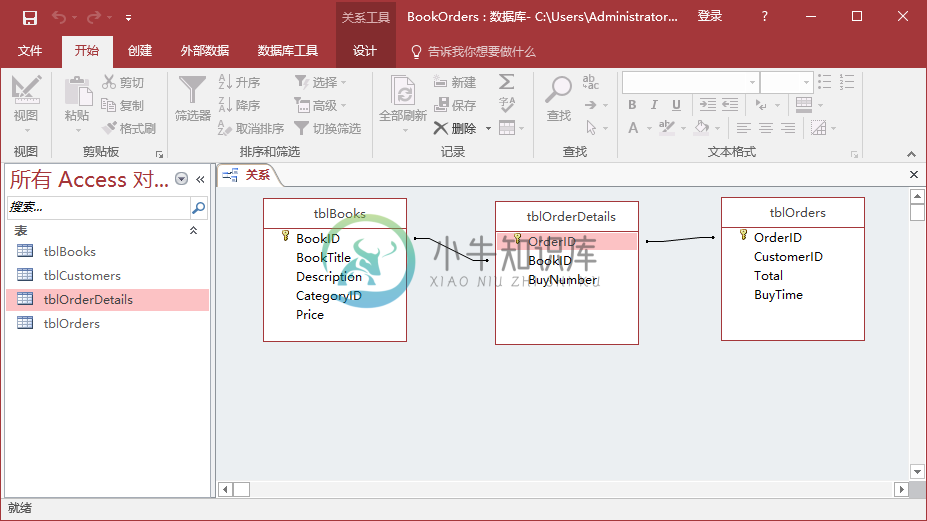 Access分组数据
Access分组数据主要内容:聚合查询,Access中的连接,示例在本章中,我们将介绍Access中如何计算如何分组记录。 我们创建了一个按行计算或按记录计算的字段来创建行总计或小计字段,但是如果想通过分组记录而不是单个记录来计算,那该怎么办呢? 可以通过创建聚合查询来实现这一点。 聚合查询 聚合查询也称为总计或汇总查询是总和,质量或组的详细信息。它可以是总金额或总金额或记录的组或子集。 聚合查询可以执行许多操作。下面是一个简单的表格,列出了分组记录中总的方法。